 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-scale Medical Visual Task Adaptation Benchmark
Paper and Code
Apr 19, 2024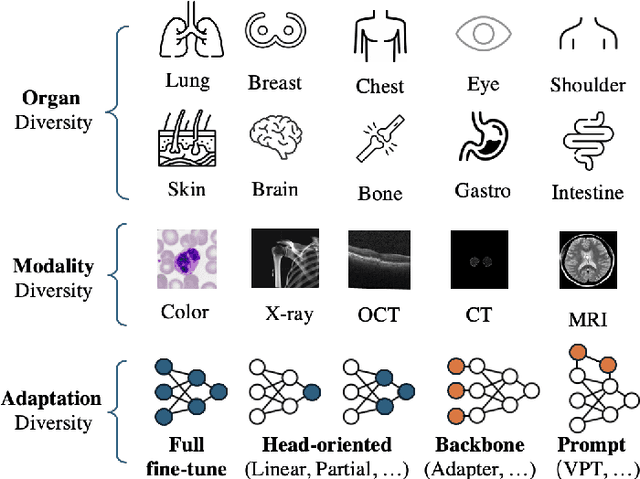
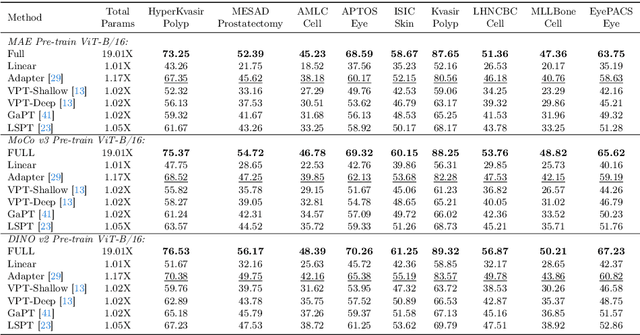
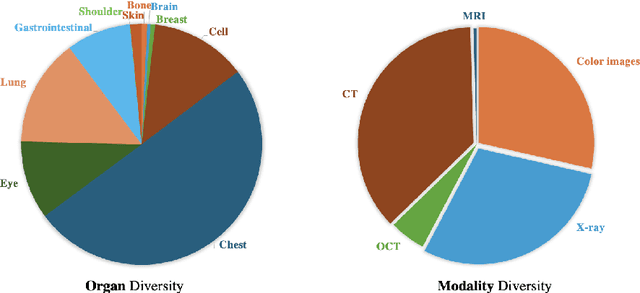
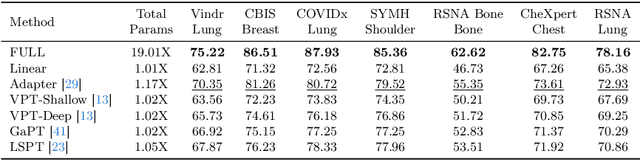
Visual task adaptation has been demonstrated to be effective in adapting pre-trained Vision Transformers (ViTs) to general downstream visual tasks using specialized learnable layers or tokens. However, there is yet a large-scale benchmark to fully explore the effect of visual task adaptation on the realistic and important medical domain, particularly across diverse medical visual modalities, such as color images, X-ray, and CT. To close this gap, we present Med-VTAB, a large-scale Medical Visual Task Adaptation Benchmark consisting of 1.68 million medical images for diverse organs, modalities, and adaptation approaches. Based on Med-VTAB, we explore the scaling law of medical prompt tuning concerning tunable parameters and the generalizability of medical visual adaptation using non-medical/medical pre-train weights. Besides, we study the impact of patient ID out-of-distribution on medical visual adaptation, which is a real and challenging scenario. Furthermore, results from Med-VTAB indicate that a single pre-trained model falls short in medical task adaptation. Therefore, we introduce GMoE-Adapter, a novel method that combines medical and general pre-training weights through a gated mixture-of-experts adapter, achieving state-of-the-art results in medical visual task adaptation.