 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSortedRL: Accelerating RL Training for LLMs through Online Length-Aware Scheduling
Mar 24, 2026Scaling reinforcement learning (RL) has shown strong promise for enhancing the reasoning abilities of large language models (LLMs), particularly in tasks requiring long chain-of-thought generation. However, RL training efficiency is often bottlenecked by the rollout phase, which can account for up to 70% of total training time when generating long trajectories (e.g., 16k tokens), due to slow autoregressive generation and synchronization overhead between rollout and policy updates. We propose SortedRL, an online length-aware scheduling strategy designed to address this bottleneck by improving rollout efficiency and maintaining training stability. SortedRL reorders rollout samples based on output lengths, prioritizing short samples forming groups for early updates. This enables large rollout batches, flexible update batches, and near on-policy micro-curriculum construction simultaneously. To further accelerate the pipeline, SortedRL incorporates a mechanism to control the degree of off-policy training through a cache-based mechanism, and is supported by a dedicated RL infrastructure that manages rollout and update via a stateful controller and rollout buffer. Experiments using LLaMA-3.1-8B and Qwen-2.5-32B on diverse tasks, including logical puzzles, and math challenges like AIME 24, Math 500, and Minerval, show that SortedRL reduces RL training bubble ratios by over 50%, while attaining 3.9% to 18.4% superior performance over baseline given same amount of data.
MTraining: Distributed Dynamic Sparse Attention for Efficient Ultra-Long Context Training
Oct 21, 2025The adoption of long context windows has become a standard feature in Large Language Models (LLMs), as extended contexts significantly enhance their capacity for complex reasoning and broaden their applicability across diverse scenarios. Dynamic sparse attention is a promising approach for reducing the computational cost of long-context. However, efficiently training LLMs with dynamic sparse attention on ultra-long contexts-especially in distributed settings-remains a significant challenge, due in large part to worker- and step-level imbalance. This paper introduces MTraining, a novel distributed methodology leveraging dynamic sparse attention to enable efficient training for LLMs with ultra-long contexts. Specifically, MTraining integrates three key components: a dynamic sparse training pattern, balanced sparse ring attention, and hierarchical sparse ring attention. These components are designed to synergistically address the computational imbalance and communication overheads inherent in dynamic sparse attention mechanisms during the training of models with extensive context lengths. We demonstrate the efficacy of MTraining by training Qwen2.5-3B, successfully expanding its context window from 32K to 512K tokens on a cluster of 32 A100 GPUs. Our evaluations on a comprehensive suite of downstream tasks, including RULER, PG-19, InfiniteBench, and Needle In A Haystack, reveal that MTraining achieves up to a 6x higher training throughput while preserving model accuracy. Our code is available at https://github.com/microsoft/MInference/tree/main/MTraining.
Chain-of-Model Learning for Language Model
May 17, 2025In this paper, we propose a novel learning paradigm, termed Chain-of-Model (CoM), which incorporates the causal relationship into the hidden states of each layer as a chain style, thereby introducing great scaling efficiency in model training and inference flexibility in deployment. We introduce the concept of Chain-of-Representation (CoR), which formulates the hidden states at each layer as a combination of multiple sub-representations (i.e., chains) at the hidden dimension level. In each layer, each chain from the output representations can only view all of its preceding chains in the input representations. Consequently, the model built upon CoM framework can progressively scale up the model size by increasing the chains based on the previous models (i.e., chains), and offer multiple sub-models at varying sizes for elastic inference by using different chain numbers. Based on this principle, we devise Chain-of-Language-Model (CoLM), which incorporates the idea of CoM into each layer of Transformer architecture. Based on CoLM, we further introduce CoLM-Air by introducing a KV sharing mechanism, that computes all keys and values within the first chain and then shares across all chains. This design demonstrates additional extensibility, such as enabling seamless LM switching, prefilling acceleration and so on. Experimental results demonstrate our CoLM family can achieve comparable performance to the standard Transformer, while simultaneously enabling greater flexiblity, such as progressive scaling to improve training efficiency and offer multiple varying model sizes for elastic inference, paving a a new way toward building language models. Our code will be released in the future at: https://github.com/microsoft/CoLM.
RetroInfer: A Vector-Storage Approach for Scalable Long-Context LLM Inference
May 05, 2025The growing context lengths of large language models (LLMs) pose significant challenges for efficient inference, primarily due to GPU memory and bandwidth constraints. We present RetroInfer, a novel system that reconceptualizes the key-value (KV) cache as a vector storage system which exploits the inherent attention sparsity to accelerate long-context LLM inference. At its core is the wave index, an Attention-aWare VEctor index that enables efficient and accurate retrieval of critical tokens through techniques such as tripartite attention approximation, accuracy-bounded attention estimation, and segmented clustering. Complementing this is the wave buffer, which coordinates KV cache placement and overlaps computation and data transfer across GPU and CPU to sustain high throughput. Unlike prior sparsity-based methods that struggle with token selection and hardware coordination, RetroInfer delivers robust performance without compromising model accuracy. Experiments on long-context benchmarks show up to 4.5X speedup over full attention within GPU memory limits and up to 10.5X over sparse attention baselines when KV cache is extended to CPU memory, all while preserving full-attention-level accuracy.
MMInference: Accelerating Pre-filling for Long-Context VLMs via Modality-Aware Permutation Sparse Attention
Apr 22, 2025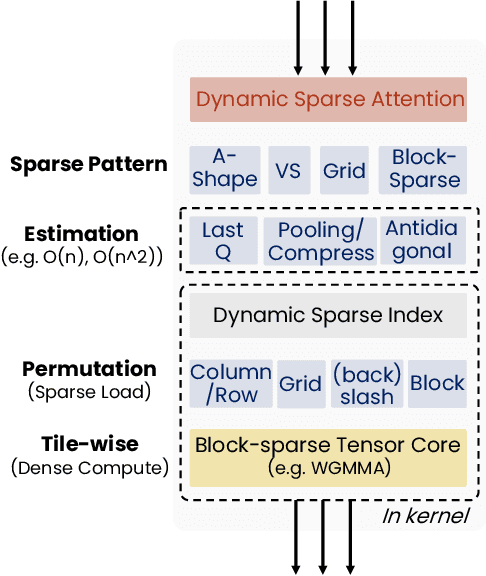
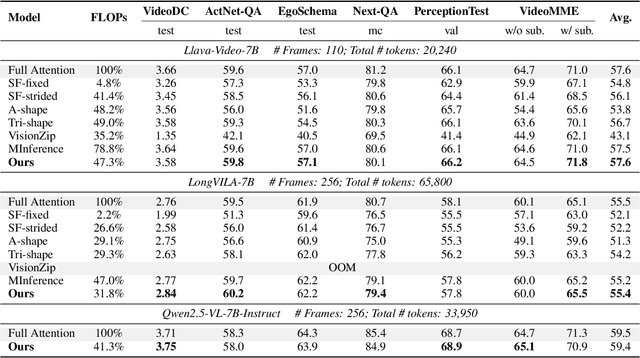
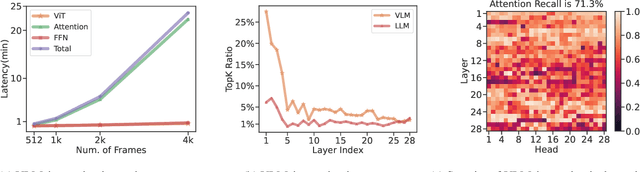

The integration of long-context capabilities with visual understanding unlocks unprecedented potential for Vision Language Models (VLMs). However, the quadratic attention complexity during the pre-filling phase remains a significant obstacle to real-world deployment. To overcome this limitation, we introduce MMInference (Multimodality Million tokens Inference), a dynamic sparse attention method that accelerates the prefilling stage for long-context multi-modal inputs. First, our analysis reveals that the temporal and spatial locality of video input leads to a unique sparse pattern, the Grid pattern. Simultaneously, VLMs exhibit markedly different sparse distributions across different modalities. We introduce a permutation-based method to leverage the unique Grid pattern and handle modality boundary issues. By offline search the optimal sparse patterns for each head, MMInference constructs the sparse distribution dynamically based on the input. We also provide optimized GPU kernels for efficient sparse computations. Notably, MMInference integrates seamlessly into existing VLM pipelines without any model modifications or fine-tuning. Experiments on multi-modal benchmarks-including Video QA, Captioning, VisionNIAH, and Mixed-Modality NIAH-with state-of-the-art long-context VLMs (LongVila, LlavaVideo, VideoChat-Flash, Qwen2.5-VL) show that MMInference accelerates the pre-filling stage by up to 8.3x at 1M tokens while maintaining accuracy. Our code is available at https://aka.ms/MMInference.
SCBench: A KV Cache-Centric Analysis of Long-Context Methods
Dec 13, 2024



Long-context LLMs have enabled numerous downstream applications but also introduced significant challenges related to computational and memory efficiency. To address these challenges, optimizations for long-context inference have been developed, centered around the KV cache. However, existing benchmarks often evaluate in single-request, neglecting the full lifecycle of the KV cache in real-world use. This oversight is particularly critical, as KV cache reuse has become widely adopted in LLMs inference frameworks, such as vLLM and SGLang, as well as by LLM providers, including OpenAI, Microsoft, Google, and Anthropic. To address this gap, we introduce SCBench(SharedContextBench), a comprehensive benchmark for evaluating long-context methods from a KV cachecentric perspective: 1) KV cache generation, 2) KV cache compression, 3) KV cache retrieval, 4) KV cache loading. Specifically, SCBench uses test examples with shared context, ranging 12 tasks with two shared context modes, covering four categories of long-context capabilities: string retrieval, semantic retrieval, global information, and multi-task. With it, we provide an extensive KV cache-centric analysis of eight categories long-context solutions, including Gated Linear RNNs, Mamba-Attention hybrids, and efficient methods such as sparse attention, KV cache dropping, quantization, retrieval, loading, and prompt compression. The evaluation is conducted on 8 long-context LLMs. Our findings show that sub-O(n) memory methods suffer in multi-turn scenarios, while sparse encoding with O(n) memory and sub-O(n^2) pre-filling computation perform robustly. Dynamic sparsity yields more expressive KV caches than static patterns, and layer-level sparsity in hybrid architectures reduces memory usage with strong performance. Additionally, we identify attention distribution shift issues in long-generation scenarios. https://aka.ms/SCBench.
RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval
Sep 16, 2024



Transformer-based large Language Models (LLMs) become increasingly important in various domains. However, the quadratic time complexity of attention operation poses a significant challenge for scaling to longer contexts due to the extremely high inference latency and GPU memory consumption for caching key-value (KV) vectors. This paper proposes RetrievalAttention, a training-free approach to accelerate attention computation. To leverage the dynamic sparse property of attention, RetrievalAttention builds approximate nearest neighbor search (ANNS) indexes upon KV vectors in CPU memory and retrieves the most relevant ones via vector search during generation. Due to the out-of-distribution (OOD) between query vectors and key vectors, off-the-shelf ANNS indexes still need to scan O(N) (usually 30% of all keys) data for accurate retrieval, which fails to exploit the high sparsity. RetrievalAttention first identifies the OOD challenge of ANNS-based attention, and addresses it via an attention-aware vector search algorithm that can adapt to queries and only access 1--3% of data, thus achieving a sub-linear time complexity. RetrievalAttention greatly reduces the inference cost of long-context LLM with much lower GPU memory requirements while maintaining the model accuracy. Especially, RetrievalAttention only needs 16GB GPU memory for serving 128K tokens in LLMs with 8B parameters, which is capable of generating one token in 0.188 seconds on a single NVIDIA RTX4090 (24GB).
MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention
Jul 02, 2024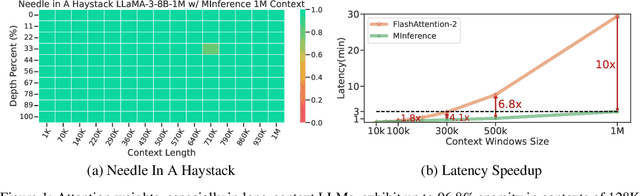

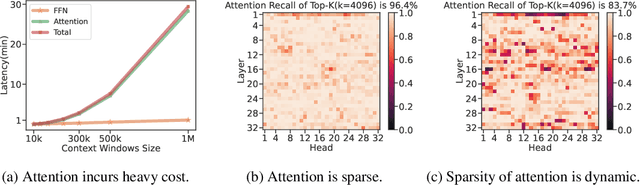
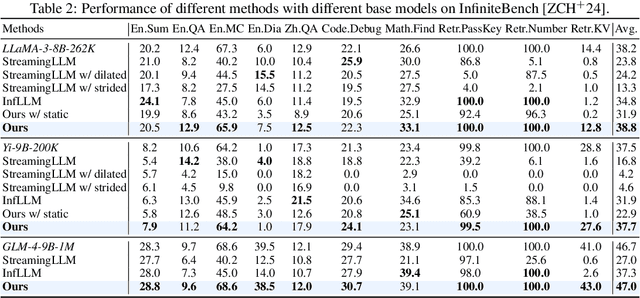
The computational challenges of Large Language Model (LLM) inference remain a significant barrier to their widespread deployment, especially as prompt lengths continue to increase. Due to the quadratic complexity of the attention computation, it takes 30 minutes for an 8B LLM to process a prompt of 1M tokens (i.e., the pre-filling stage) on a single A100 GPU. Existing methods for speeding up prefilling often fail to maintain acceptable accuracy or efficiency when applied to long-context LLMs. To address this gap, we introduce MInference (Milliontokens Inference), a sparse calculation method designed to accelerate pre-filling of long-sequence processing. Specifically, we identify three unique patterns in long-context attention matrices-the A-shape, Vertical-Slash, and Block-Sparsethat can be leveraged for efficient sparse computation on GPUs. We determine the optimal pattern for each attention head offline and dynamically build sparse indices based on the assigned pattern during inference. With the pattern and sparse indices, we perform efficient sparse attention calculations via our optimized GPU kernels to significantly reduce the latency in the pre-filling stage of long-context LLMs. Our proposed technique can be directly applied to existing LLMs without any modifications to the pre-training setup or additional fine-tuning. By evaluating on a wide range of downstream tasks, including InfiniteBench, RULER, PG-19, and Needle In A Haystack, and models including LLaMA-3-1M, GLM4-1M, Yi-200K, Phi-3-128K, and Qwen2-128K, we demonstrate that MInference effectively reduces inference latency by up to 10x for pre-filling on an A100, while maintaining accuracy. Our code is available at https://aka.ms/MInference.
Parrot: Efficient Serving of LLM-based Applications with Semantic Variable
May 30, 2024The rise of large language models (LLMs) has enabled LLM-based applications (a.k.a. AI agents or co-pilots), a new software paradigm that combines the strength of LLM and conventional software. Diverse LLM applications from different tenants could design complex workflows using multiple LLM requests to accomplish one task. However, they have to use the over-simplified request-level API provided by today's public LLM services, losing essential application-level information. Public LLM services have to blindly optimize individual LLM requests, leading to sub-optimal end-to-end performance of LLM applications. This paper introduces Parrot, an LLM service system that focuses on the end-to-end experience of LLM-based applications. Parrot proposes Semantic Variable, a unified abstraction to expose application-level knowledge to public LLM services. A Semantic Variable annotates an input/output variable in the prompt of a request, and creates the data pipeline when connecting multiple LLM requests, providing a natural way to program LLM applications. Exposing Semantic Variables to the public LLM service allows it to perform conventional data flow analysis to uncover the correlation across multiple LLM requests. This correlation opens a brand-new optimization space for the end-to-end performance of LLM-based applications. Extensive evaluations demonstrate that Parrot can achieve up to an order-of-magnitude improvement for popular and practical use cases of LLM applications.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).