 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecurityLingua: Efficient Defense of LLM Jailbreak Attacks via Security-Aware Prompt Compression
Jun 15, 2025Large language models (LLMs) have achieved widespread adoption across numerous applications. However, many LLMs are vulnerable to malicious attacks even after safety alignment. These attacks typically bypass LLMs' safety guardrails by wrapping the original malicious instructions inside adversarial jailbreaks prompts. Previous research has proposed methods such as adversarial training and prompt rephrasing to mitigate these safety vulnerabilities, but these methods often reduce the utility of LLMs or lead to significant computational overhead and online latency. In this paper, we propose SecurityLingua, an effective and efficient approach to defend LLMs against jailbreak attacks via security-oriented prompt compression. Specifically, we train a prompt compressor designed to discern the "true intention" of the input prompt, with a particular focus on detecting the malicious intentions of adversarial prompts. Then, in addition to the original prompt, the intention is passed via the system prompt to the target LLM to help it identify the true intention of the request. SecurityLingua ensures a consistent user experience by leaving the original input prompt intact while revealing the user's potentially malicious intention and stimulating the built-in safety guardrails of the LLM. Moreover, thanks to prompt compression, SecurityLingua incurs only a negligible overhead and extra token cost compared to all existing defense methods, making it an especially practical solution for LLM defense. Experimental results demonstrate that SecurityLingua can effectively defend against malicious attacks and maintain utility of the LLM with negligible compute and latency overhead. Our code is available at https://aka.ms/SecurityLingua.
MMInference: Accelerating Pre-filling for Long-Context VLMs via Modality-Aware Permutation Sparse Attention
Apr 22, 2025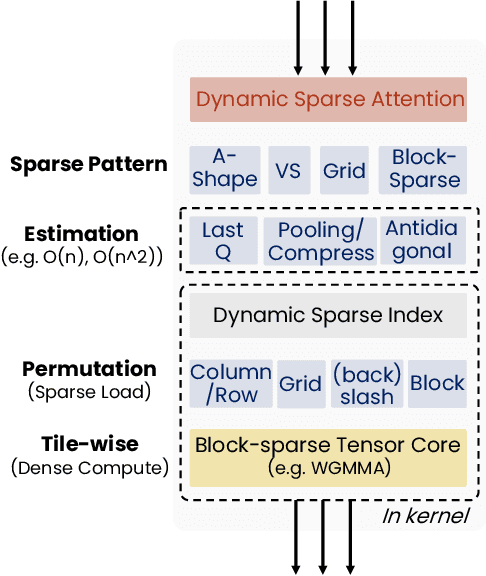
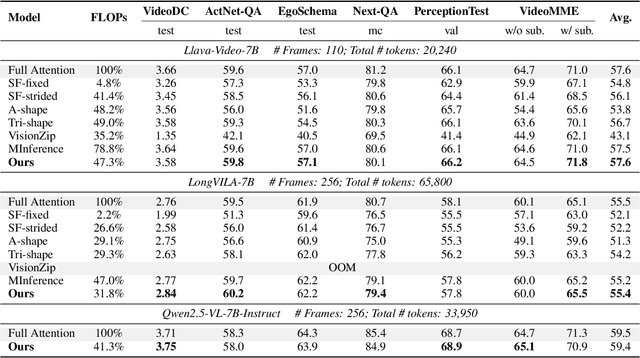
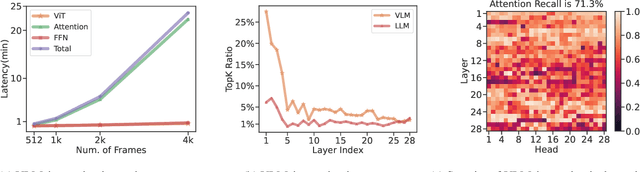

The integration of long-context capabilities with visual understanding unlocks unprecedented potential for Vision Language Models (VLMs). However, the quadratic attention complexity during the pre-filling phase remains a significant obstacle to real-world deployment. To overcome this limitation, we introduce MMInference (Multimodality Million tokens Inference), a dynamic sparse attention method that accelerates the prefilling stage for long-context multi-modal inputs. First, our analysis reveals that the temporal and spatial locality of video input leads to a unique sparse pattern, the Grid pattern. Simultaneously, VLMs exhibit markedly different sparse distributions across different modalities. We introduce a permutation-based method to leverage the unique Grid pattern and handle modality boundary issues. By offline search the optimal sparse patterns for each head, MMInference constructs the sparse distribution dynamically based on the input. We also provide optimized GPU kernels for efficient sparse computations. Notably, MMInference integrates seamlessly into existing VLM pipelines without any model modifications or fine-tuning. Experiments on multi-modal benchmarks-including Video QA, Captioning, VisionNIAH, and Mixed-Modality NIAH-with state-of-the-art long-context VLMs (LongVila, LlavaVideo, VideoChat-Flash, Qwen2.5-VL) show that MMInference accelerates the pre-filling stage by up to 8.3x at 1M tokens while maintaining accuracy. Our code is available at https://aka.ms/MMInference.
SCBench: A KV Cache-Centric Analysis of Long-Context Methods
Dec 13, 2024



Long-context LLMs have enabled numerous downstream applications but also introduced significant challenges related to computational and memory efficiency. To address these challenges, optimizations for long-context inference have been developed, centered around the KV cache. However, existing benchmarks often evaluate in single-request, neglecting the full lifecycle of the KV cache in real-world use. This oversight is particularly critical, as KV cache reuse has become widely adopted in LLMs inference frameworks, such as vLLM and SGLang, as well as by LLM providers, including OpenAI, Microsoft, Google, and Anthropic. To address this gap, we introduce SCBench(SharedContextBench), a comprehensive benchmark for evaluating long-context methods from a KV cachecentric perspective: 1) KV cache generation, 2) KV cache compression, 3) KV cache retrieval, 4) KV cache loading. Specifically, SCBench uses test examples with shared context, ranging 12 tasks with two shared context modes, covering four categories of long-context capabilities: string retrieval, semantic retrieval, global information, and multi-task. With it, we provide an extensive KV cache-centric analysis of eight categories long-context solutions, including Gated Linear RNNs, Mamba-Attention hybrids, and efficient methods such as sparse attention, KV cache dropping, quantization, retrieval, loading, and prompt compression. The evaluation is conducted on 8 long-context LLMs. Our findings show that sub-O(n) memory methods suffer in multi-turn scenarios, while sparse encoding with O(n) memory and sub-O(n^2) pre-filling computation perform robustly. Dynamic sparsity yields more expressive KV caches than static patterns, and layer-level sparsity in hybrid architectures reduces memory usage with strong performance. Additionally, we identify attention distribution shift issues in long-generation scenarios. https://aka.ms/SCBench.
MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention
Jul 02, 2024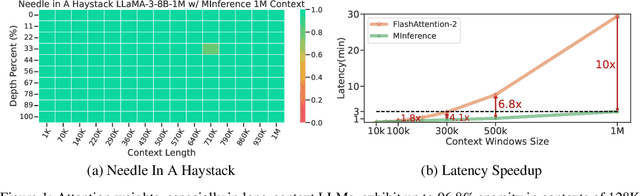

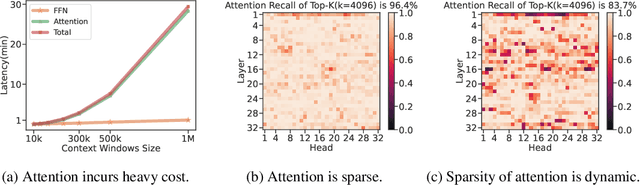
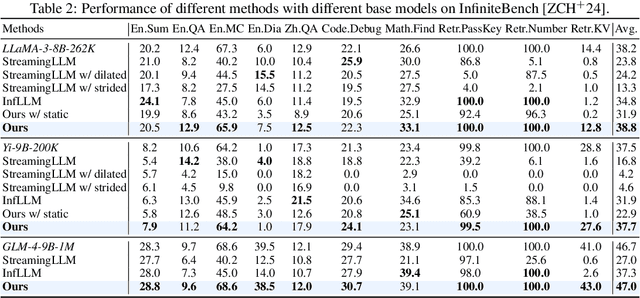
The computational challenges of Large Language Model (LLM) inference remain a significant barrier to their widespread deployment, especially as prompt lengths continue to increase. Due to the quadratic complexity of the attention computation, it takes 30 minutes for an 8B LLM to process a prompt of 1M tokens (i.e., the pre-filling stage) on a single A100 GPU. Existing methods for speeding up prefilling often fail to maintain acceptable accuracy or efficiency when applied to long-context LLMs. To address this gap, we introduce MInference (Milliontokens Inference), a sparse calculation method designed to accelerate pre-filling of long-sequence processing. Specifically, we identify three unique patterns in long-context attention matrices-the A-shape, Vertical-Slash, and Block-Sparsethat can be leveraged for efficient sparse computation on GPUs. We determine the optimal pattern for each attention head offline and dynamically build sparse indices based on the assigned pattern during inference. With the pattern and sparse indices, we perform efficient sparse attention calculations via our optimized GPU kernels to significantly reduce the latency in the pre-filling stage of long-context LLMs. Our proposed technique can be directly applied to existing LLMs without any modifications to the pre-training setup or additional fine-tuning. By evaluating on a wide range of downstream tasks, including InfiniteBench, RULER, PG-19, and Needle In A Haystack, and models including LLaMA-3-1M, GLM4-1M, Yi-200K, Phi-3-128K, and Qwen2-128K, we demonstrate that MInference effectively reduces inference latency by up to 10x for pre-filling on an A100, while maintaining accuracy. Our code is available at https://aka.ms/MInference.
Local Model Explanations and Uncertainty Without Model Access
Jan 24, 2023We present a model-agnostic algorithm for generating post-hoc explanations and uncertainty intervals for a machine learning model when only a sample of inputs and outputs from the model is available, rather than direct access to the model itself. This situation may arise when model evaluations are expensive; when privacy, security and bandwidth constraints are imposed; or when there is a need for real-time, on-device explanations. Our algorithm constructs explanations using local polynomial regression and quantifies the uncertainty of the explanations using a bootstrapping approach. Through a simulation study, we show that the uncertainty intervals generated by our algorithm exhibit a favorable trade-off between interval width and coverage probability compared to the naive confidence intervals from classical regression analysis. We further demonstrate the capabilities of our method by applying it to black-box models trained on two real datasets.
Global Multiclass Classification from Heterogeneous Local Models
May 25, 2020
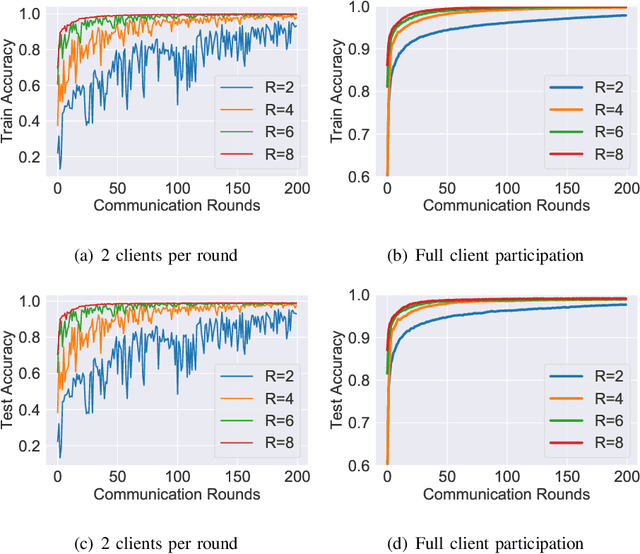
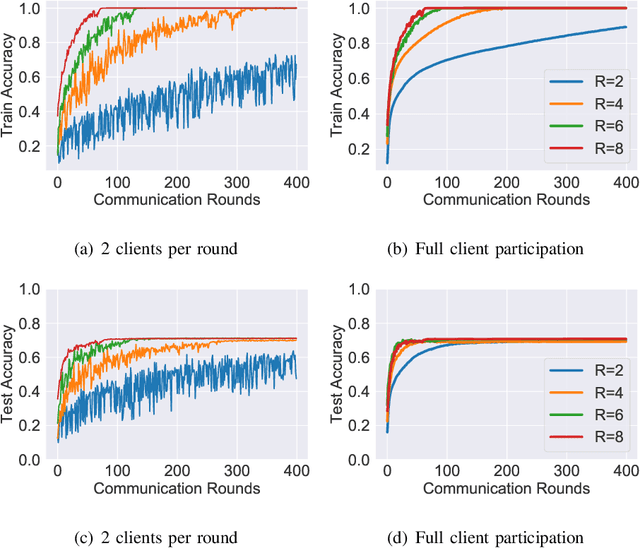
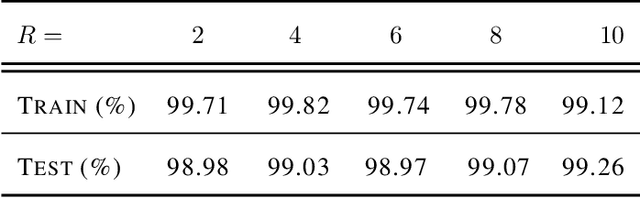
Multiclass classification problems are most often solved by either training a single centralized classifier on all $K$ classes, or by reducing the problem to multiple binary classification tasks. This paper explores the uncharted region between these two extremes: How can we solve the $K$-class classification problem by combining the predictions of smaller classifiers, each trained on an arbitrary number of classes $R \in \{2, 3, \ldots, K\}$? We present a mathematical framework for answering this question, and derive bounds on the number of classifiers (in terms of $K$ and $R$) needed to accurately predict the true class of an unlabeled sample under both adversarial and stochastic assumptions. By exploiting a connection to the classical set cover problem in combinatorics, we produce an efficient, near-optimal scheme (with respect to the number of classifiers) for designing such configurations of classifiers, which recovers the well-known one-vs.-one strategy as a special case when $R=2$. Experiments with the MNIST and CIFAR-10 datasets show that our scheme is capable of matching the performance of centralized classifiers in practice. The results suggest that our approach offers a promising direction for solving the problem of data heterogeneity which plagues current federated learning methods.