 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Models as a Source of Rewards
Dec 14, 2023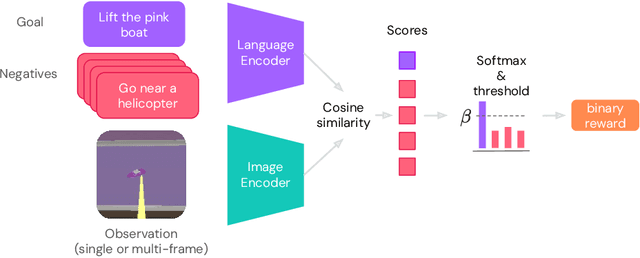
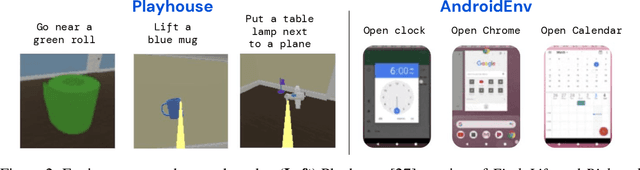
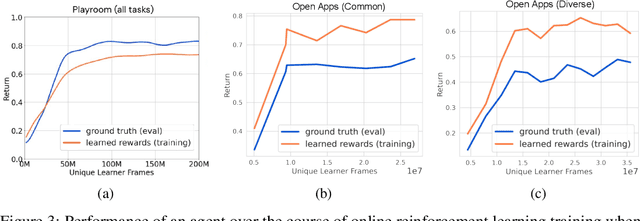
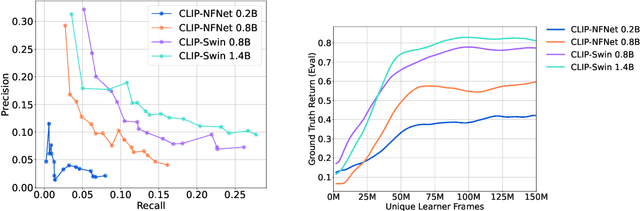
Building generalist agents that can accomplish many goals in rich open-ended environments is one of the research frontiers for reinforcement learning. A key limiting factor for building generalist agents with RL has been the need for a large number of reward functions for achieving different goals. We investigate the feasibility of using off-the-shelf vision-language models, or VLMs, as sources of rewards for reinforcement learning agents. We show how rewards for visual achievement of a variety of language goals can be derived from the CLIP family of models, and used to train RL agents that can achieve a variety of language goals. We showcase this approach in two distinct visual domains and present a scaling trend showing how larger VLMs lead to more accurate rewards for visual goal achievement, which in turn produces more capable RL agents.
Local Model Explanations and Uncertainty Without Model Access
Jan 24, 2023We present a model-agnostic algorithm for generating post-hoc explanations and uncertainty intervals for a machine learning model when only a sample of inputs and outputs from the model is available, rather than direct access to the model itself. This situation may arise when model evaluations are expensive; when privacy, security and bandwidth constraints are imposed; or when there is a need for real-time, on-device explanations. Our algorithm constructs explanations using local polynomial regression and quantifies the uncertainty of the explanations using a bootstrapping approach. Through a simulation study, we show that the uncertainty intervals generated by our algorithm exhibit a favorable trade-off between interval width and coverage probability compared to the naive confidence intervals from classical regression analysis. We further demonstrate the capabilities of our method by applying it to black-box models trained on two real datasets.