 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
DeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference
Jan 09, 2024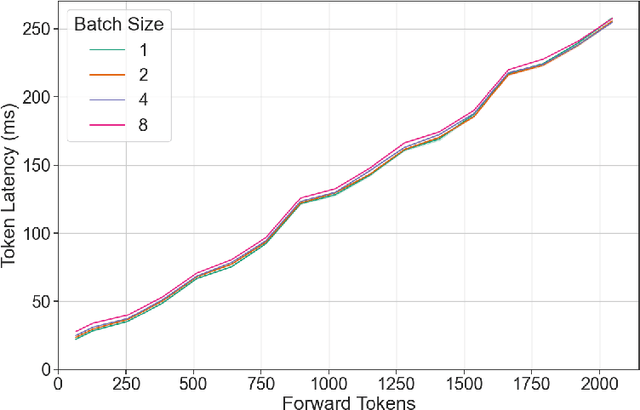
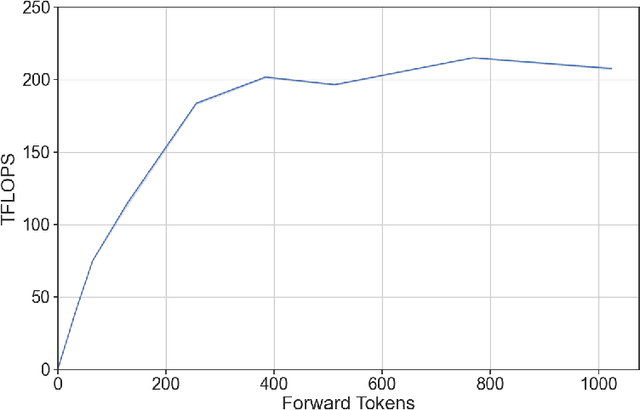
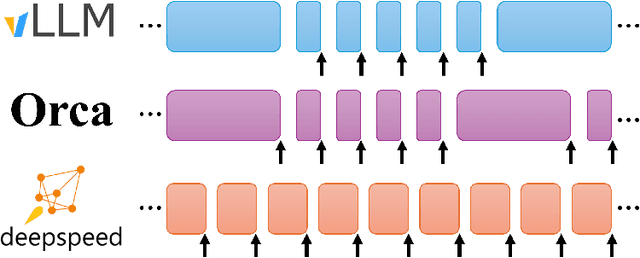
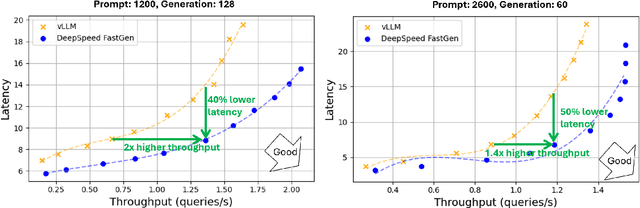
The deployment and scaling of large language models (LLMs) have become critical as they permeate various applications, demanding high-throughput and low-latency serving systems. Existing frameworks struggle to balance these requirements, especially for workloads with long prompts. This paper introduces DeepSpeed-FastGen, a system that employs Dynamic SplitFuse, a novel prompt and generation composition strategy, to deliver up to 2.3x higher effective throughput, 2x lower latency on average, and up to 3.7x lower (token-level) tail latency, compared to state-of-the-art systems like vLLM. We leverage a synergistic combination of DeepSpeed-MII and DeepSpeed-Inference to provide an efficient and easy-to-use serving system for LLMs. DeepSpeed-FastGen's advanced implementation supports a range of models and offers both non-persistent and persistent deployment options, catering to diverse user scenarios from interactive sessions to long-running applications. We present a detailed benchmarking methodology, analyze the performance through latency-throughput curves, and investigate scalability via load balancing. Our evaluations demonstrate substantial improvements in throughput and latency across various models and hardware configurations. We discuss our roadmap for future enhancements, including broader model support and new hardware backends. The DeepSpeed-FastGen code is readily available for community engagement and contribution.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
DeepSpeed-VisualChat: Multi-Round Multi-Image Interleave Chat via Multi-Modal Causal Attention
Sep 29, 2023



Most of the existing multi-modal models, hindered by their incapacity to adeptly manage interleaved image-and-text inputs in multi-image, multi-round dialogues, face substantial constraints in resource allocation for training and data accessibility, impacting their adaptability and scalability across varied interaction realms. To address this, we present the DeepSpeed-VisualChat framework, designed to optimize Large Language Models (LLMs) by incorporating multi-modal capabilities, with a focus on enhancing the proficiency of Large Vision and Language Models in handling interleaved inputs. Our framework is notable for (1) its open-source support for multi-round and multi-image dialogues, (2) introducing an innovative multi-modal causal attention mechanism, and (3) utilizing data blending techniques on existing datasets to assure seamless interactions in multi-round, multi-image conversations. Compared to existing frameworks, DeepSpeed-VisualChat shows superior scalability up to 70B parameter language model size, representing a significant advancement in multi-modal language models and setting a solid foundation for future explorations.
DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales
Aug 02, 2023
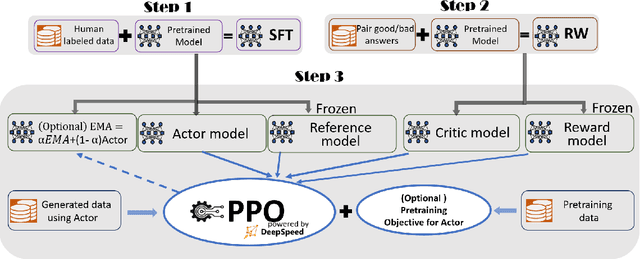

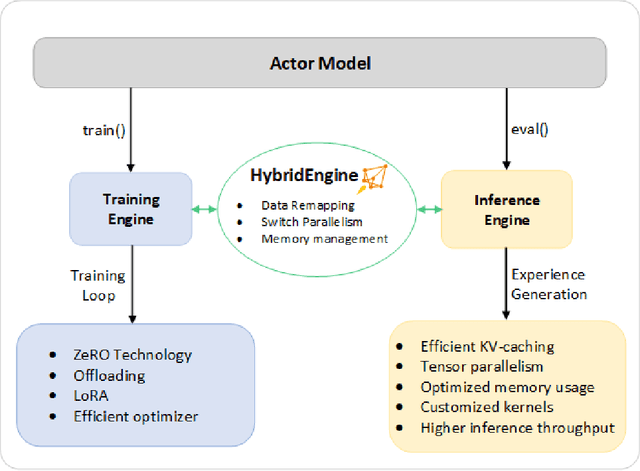
ChatGPT-like models have revolutionized various applications in artificial intelligence, from summarization and coding to translation, matching or even surpassing human performance. However, the current landscape lacks an accessible, efficient, and cost-effective end-to-end RLHF (Reinforcement Learning with Human Feedback) training pipeline for these powerful models, particularly when training at the scale of billions of parameters. This paper introduces DeepSpeed-Chat, a novel system that democratizes RLHF training, making it accessible to the AI community. DeepSpeed-Chat offers three key capabilities: an easy-to-use training and inference experience for ChatGPT-like models, a DeepSpeed-RLHF pipeline that replicates the training pipeline from InstructGPT, and a robust DeepSpeed-RLHF system that combines various optimizations for training and inference in a unified way. The system delivers unparalleled efficiency and scalability, enabling training of models with hundreds of billions of parameters in record time and at a fraction of the cost. With this development, DeepSpeed-Chat paves the way for broader access to advanced RLHF training, even for data scientists with limited resources, thereby fostering innovation and further development in the field of AI.
MCR-DL: Mix-and-Match Communication Runtime for Deep Learning
Mar 15, 2023



In recent years, the training requirements of many state-of-the-art Deep Learning (DL) models have scaled beyond the compute and memory capabilities of a single processor, and necessitated distribution among processors. Training such massive models necessitates advanced parallelism strategies to maintain efficiency. However, such distributed DL parallelism strategies require a varied mixture of collective and point-to-point communication operations across a broad range of message sizes and scales. Examples of models using advanced parallelism strategies include Deep Learning Recommendation Models (DLRM) and Mixture-of-Experts (MoE). Communication libraries' performance varies wildly across different communication operations, scales, and message sizes. We propose MCR-DL: an extensible DL communication framework that supports all point-to-point and collective operations while enabling users to dynamically mix-and-match communication backends for a given operation without deadlocks. MCR-DL also comes packaged with a tuning suite for dynamically selecting the best communication backend for a given input tensor. We select DeepSpeed-MoE and DLRM as candidate DL models and demonstrate a 31% improvement in DS-MoE throughput on 256 V100 GPUs on the Lassen HPC system. Further, we achieve a 20% throughput improvement in a dense Megatron-DeepSpeed model and a 25% throughput improvement in DLRM on 32 A100 GPUs with the Theta-GPU HPC system.
A Novel Tensor-Expert Hybrid Parallelism Approach to Scale Mixture-of-Experts Training
Mar 11, 2023



A new neural network architecture called Mixture-of-Experts (MoE) has been proposed recently that increases the parameters of a neural network (the base model) by adding sparsely activated expert blocks, without changing the total number of floating point operations for training or inference. In theory, this architecture allows us to train arbitrarily large models while keeping the computational costs same as that of the base model. However, beyond 64 to 128 experts blocks, prior work has observed diminishing returns in the test accuracies of these MoE models. Thus, training high quality MoE models requires us to scale the size of the base models, along with the number of expert blocks. In this work, we propose a novel, three-dimensional, hybrid parallel algorithm that combines tensor, expert, and data parallelism to enable the training of MoE models with 4-8x larger base models than the current state-of-the-art -- DeepSpeed-MoE. We propose memory optimizations in the optimizer step, and communication optimizations that eliminate redundant movement of data. Removing these redundancies provides a speedup of nearly 21%. When training a 40 billion parameter MoE model (6.7 billion base model with 16 experts) on 128 V100 GPUs, our optimizations significantly improve the peak half precision flop/s from 20% to 27%.
DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale
Jun 30, 2022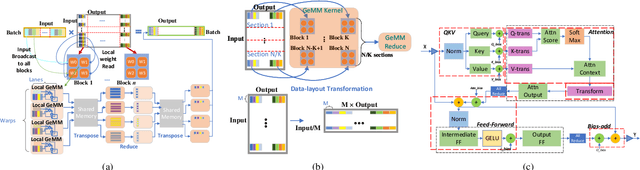
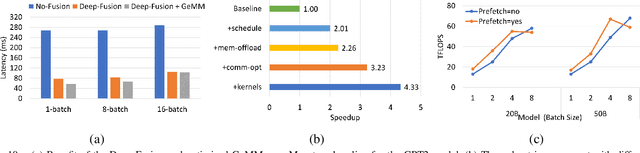
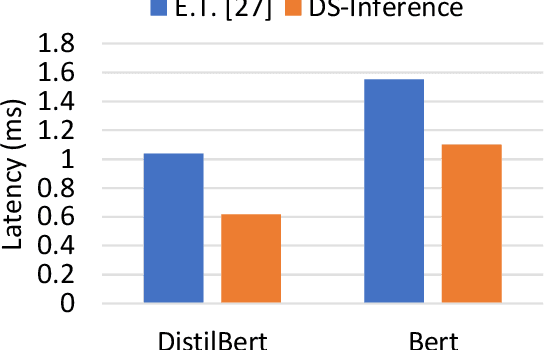
The past several years have witnessed the success of transformer-based models, and their scale and application scenarios continue to grow aggressively. The current landscape of transformer models is increasingly diverse: the model size varies drastically with the largest being of hundred-billion parameters; the model characteristics differ due to the sparsity introduced by the Mixture-of-Experts; the target application scenarios can be latency-critical or throughput-oriented; the deployment hardware could be single- or multi-GPU systems with different types of memory and storage, etc. With such increasing diversity and the fast-evolving pace of transformer models, designing a highly performant and efficient inference system is extremely challenging. In this paper, we present DeepSpeed Inference, a comprehensive system solution for transformer model inference to address the above-mentioned challenges. DeepSpeed Inference consists of (1) a multi-GPU inference solution to minimize latency while maximizing the throughput of both dense and sparse transformer models when they fit in aggregate GPU memory, and (2) a heterogeneous inference solution that leverages CPU and NVMe memory in addition to the GPU memory and compute to enable high inference throughput with large models which do not fit in aggregate GPU memory. DeepSpeed Inference reduces latency by up to 7.3X over the state-of-the-art for latency-oriented scenarios and increases throughput by over 1.5x for throughput-oriented scenarios. Moreover, it enables trillion parameter scale inference under real-time latency constraints by leveraging hundreds of GPUs, an unprecedented scale for inference. It can inference 25x larger models than with GPU-only solutions, while delivering a high throughput of 84 TFLOPS (over $50\%$ of A6000 peak).
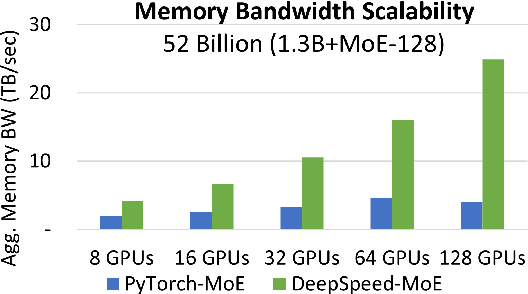
DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale
Jan 14, 2022
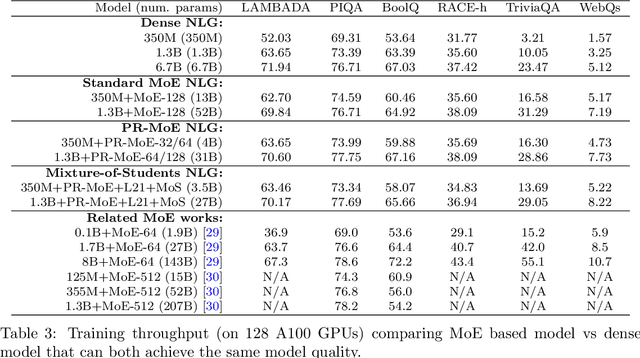
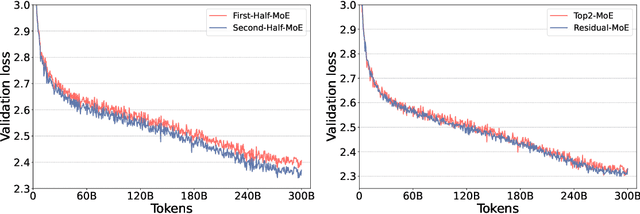
As the training of giant dense models hits the boundary on the availability and capability of the hardware resources today, Mixture-of-Experts (MoE) models become one of the most promising model architectures due to their significant training cost reduction compared to a quality-equivalent dense model. Its training cost saving is demonstrated from encoder-decoder models (prior works) to a 5x saving for auto-aggressive language models (this work along with parallel explorations). However, due to the much larger model size and unique architecture, how to provide fast MoE model inference remains challenging and unsolved, limiting its practical usage. To tackle this, we present DeepSpeed-MoE, an end-to-end MoE training and inference solution as part of the DeepSpeed library, including novel MoE architecture designs and model compression techniques that reduce MoE model size by up to 3.7x, and a highly optimized inference system that provides 7.3x better latency and cost compared to existing MoE inference solutions. DeepSpeed-MoE offers an unprecedented scale and efficiency to serve massive MoE models with up to 4.5x faster and 9x cheaper inference compared to quality-equivalent dense models. We hope our innovations and systems help open a promising path to new directions in the large model landscape, a shift from dense to sparse MoE models, where training and deploying higher-quality models with fewer resources becomes more widely possible.
Scalable and Efficient MoE Training for Multitask Multilingual Models
Sep 22, 2021
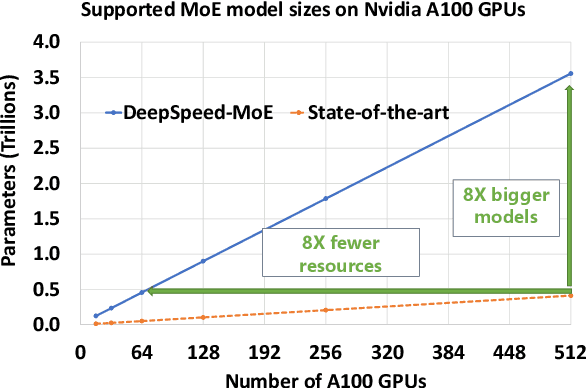
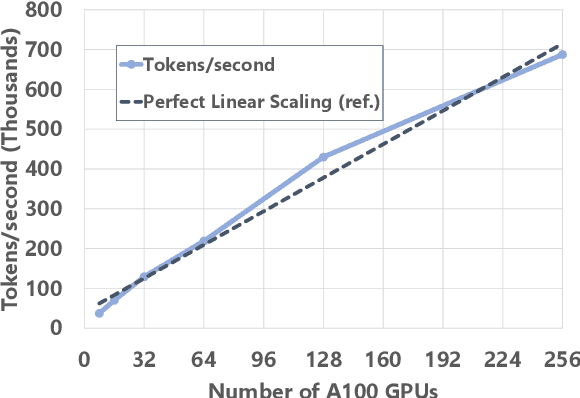
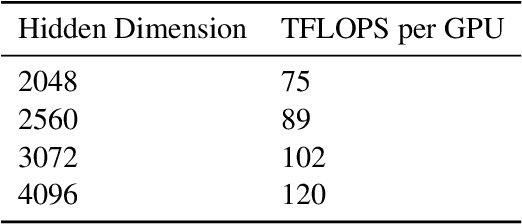
The Mixture of Experts (MoE) models are an emerging class of sparsely activated deep learning models that have sublinear compute costs with respect to their parameters. In contrast with dense models, the sparse architecture of MoE offers opportunities for drastically growing model size with significant accuracy gain while consuming much lower compute budget. However, supporting large scale MoE training also has its own set of system and modeling challenges. To overcome the challenges and embrace the opportunities of MoE, we first develop a system capable of scaling MoE models efficiently to trillions of parameters. It combines multi-dimensional parallelism and heterogeneous memory technologies harmoniously with MoE to empower 8x larger models on the same hardware compared with existing work. Besides boosting system efficiency, we also present new training methods to improve MoE sample efficiency and leverage expert pruning strategy to improve inference time efficiency. By combining the efficient system and training methods, we are able to significantly scale up large multitask multilingual models for language generation which results in a great improvement in model accuracy. A model trained with 10 billion parameters on 50 languages can achieve state-of-the-art performance in Machine Translation (MT) and multilingual natural language generation tasks. The system support of efficient MoE training has been implemented and open-sourced with the DeepSpeed library.