 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying the Communication Characteristics for Distributed Transformer Models
Aug 19, 2024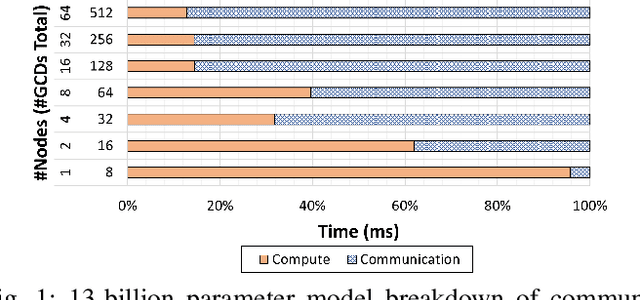
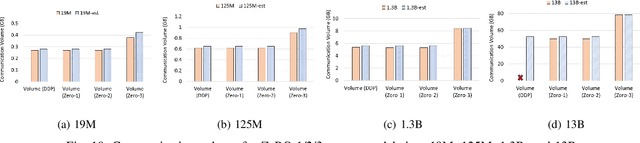
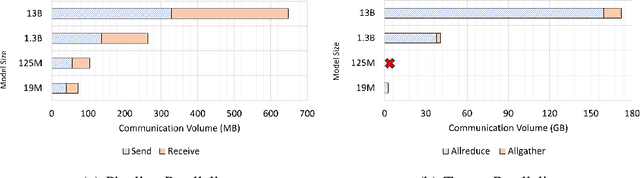
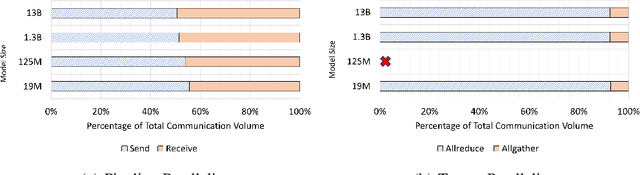
Deep learning (DL) models based on the transformer architecture have revolutionized many DL applications such as large language models (LLMs), vision transformers, audio generation, and time series prediction. Much of this progress has been fueled by distributed training, yet distributed communication remains a substantial bottleneck to training progress. This paper examines the communication behavior of transformer models - that is, how different parallelism schemes used in multi-node/multi-GPU DL Training communicate data in the context of transformers. We use GPT-based language models as a case study of the transformer architecture due to their ubiquity. We validate the empirical results obtained from our communication logs using analytical models. At a high level, our analysis reveals a need to optimize small message point-to-point communication further, correlations between sequence length, per-GPU throughput, model size, and optimizations used, and where to potentially guide further optimizations in framework and HPC middleware design and optimization.
The Case for Co-Designing Model Architectures with Hardware
Jan 30, 2024



While GPUs are responsible for training the vast majority of state-of-the-art deep learning models, the implications of their architecture are often overlooked when designing new deep learning (DL) models. As a consequence, modifying a DL model to be more amenable to the target hardware can significantly improve the runtime performance of DL training and inference. In this paper, we provide a set of guidelines for users to maximize the runtime performance of their transformer models. These guidelines have been created by carefully considering the impact of various model hyperparameters controlling model shape on the efficiency of the underlying computation kernels executed on the GPU. We find the throughput of models with efficient model shapes is up to 39\% higher while preserving accuracy compared to models with a similar number of parameters but with unoptimized shapes.
MCR-DL: Mix-and-Match Communication Runtime for Deep Learning
Mar 15, 2023



In recent years, the training requirements of many state-of-the-art Deep Learning (DL) models have scaled beyond the compute and memory capabilities of a single processor, and necessitated distribution among processors. Training such massive models necessitates advanced parallelism strategies to maintain efficiency. However, such distributed DL parallelism strategies require a varied mixture of collective and point-to-point communication operations across a broad range of message sizes and scales. Examples of models using advanced parallelism strategies include Deep Learning Recommendation Models (DLRM) and Mixture-of-Experts (MoE). Communication libraries' performance varies wildly across different communication operations, scales, and message sizes. We propose MCR-DL: an extensible DL communication framework that supports all point-to-point and collective operations while enabling users to dynamically mix-and-match communication backends for a given operation without deadlocks. MCR-DL also comes packaged with a tuning suite for dynamically selecting the best communication backend for a given input tensor. We select DeepSpeed-MoE and DLRM as candidate DL models and demonstrate a 31% improvement in DS-MoE throughput on 256 V100 GPUs on the Lassen HPC system. Further, we achieve a 20% throughput improvement in a dense Megatron-DeepSpeed model and a 25% throughput improvement in DLRM on 32 A100 GPUs with the Theta-GPU HPC system.