 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Large Language Model Training on Frontier with Low-Bandwidth Partitioning
Jan 08, 2025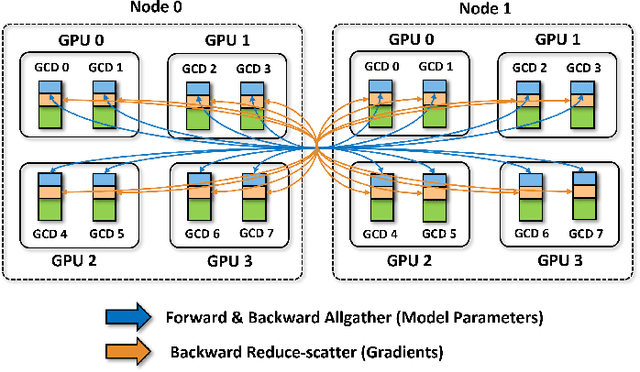
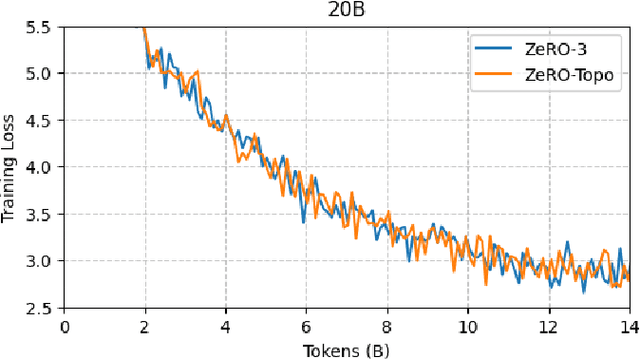
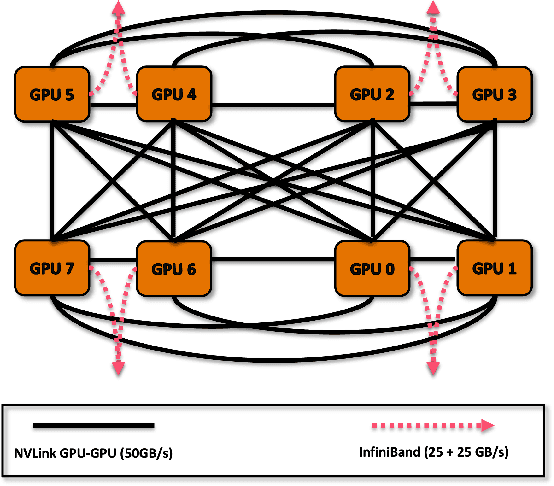
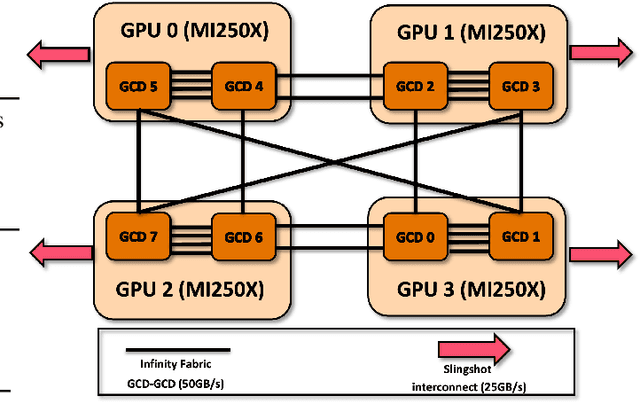
Scaling up Large Language Model(LLM) training involves fitting a tremendous amount of training parameters across a limited number of workers. However, methods like ZeRO-3 that drastically reduce GPU memory pressure often incur heavy communication to ensure global synchronization and consistency. Established efforts such as ZeRO++ use secondary partitions to avoid inter-node communications, given that intra-node GPU-GPU transfer generally has more bandwidth and lower latency than inter-node connections. However, as more capable infrastructure like Frontier, equipped with AMD GPUs, emerged with impressive computing capability, there is a need for investigations on the hardware topology and to develop targeted strategies to improve training efficiency. In this work, we propose a collection of communication and optimization strategies for ZeRO++ to reduce communication costs and improve memory utilization. In this paper, we propose a 3-level hierarchical partitioning specifically for the current Top-1 supercomputing cluster, Frontier, which aims at leveraging various bandwidths across layers of communications (GCD-GCD, GPU-GPU, and inter-node) to reduce communication overhead. For a 20B GPT model, we observe a 1.71x increase in TFLOPS per GPU when compared with ZeRO++ up to 384 GCDs and a scaling efficiency of 0.94 for up to 384 GCDs. To the best of our knowledge, our work is also the first effort to efficiently optimize LLM workloads on Frontier AMD GPUs.
Accelerating Large Language Model Training with Hybrid GPU-based Compression
Sep 04, 2024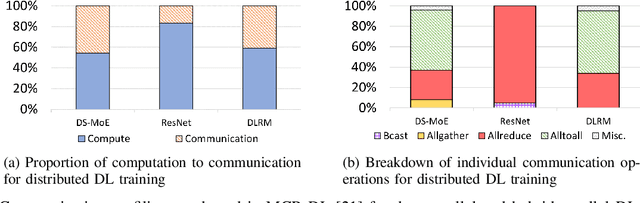
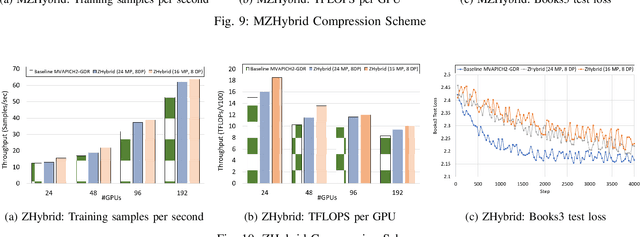
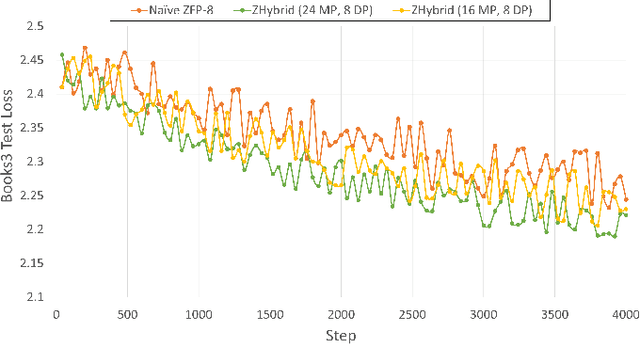
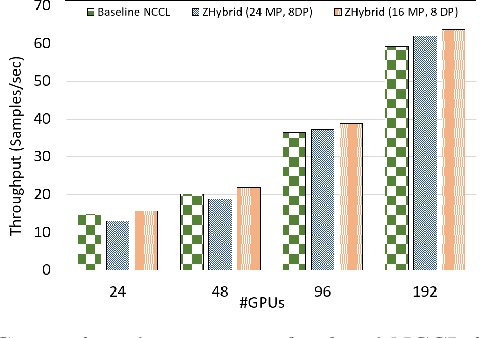
Data Parallelism (DP), Tensor Parallelism (TP), and Pipeline Parallelism (PP) are the three strategies widely adopted to enable fast and efficient Large Language Model (LLM) training. However, these approaches rely on data-intensive communication routines to collect, aggregate, and re-distribute gradients, activations, and other important model information, which pose significant overhead. Co-designed with GPU-based compression libraries, MPI libraries have been proven to reduce message size significantly, and leverage interconnect bandwidth, thus increasing training efficiency while maintaining acceptable accuracy. In this work, we investigate the efficacy of compression-assisted MPI collectives under the context of distributed LLM training using 3D parallelism and ZeRO optimizations. We scaled up to 192 V100 GPUs on the Lassen supercomputer. First, we enabled a na\"ive compression scheme across all collectives and observed a 22.5\% increase in TFLOPS per GPU and a 23.6\% increase in samples per second for GPT-NeoX-20B training. Nonetheless, such a strategy ignores the sparsity discrepancy among messages communicated in each parallelism degree, thus introducing more errors and causing degradation in training loss. Therefore, we incorporated hybrid compression settings toward each parallel dimension and adjusted the compression intensity accordingly. Given their low-rank structure (arXiv:2301.02654), we apply aggressive compression on gradients when performing DP All-reduce. We adopt milder compression to preserve precision while communicating activations, optimizer states, and model parameters in TP and PP. Using the adjusted hybrid compression scheme, we demonstrate a 17.3\% increase in TFLOPS per GPU and a 12.7\% increase in samples per second while reaching baseline loss convergence.
Demystifying the Communication Characteristics for Distributed Transformer Models
Aug 19, 2024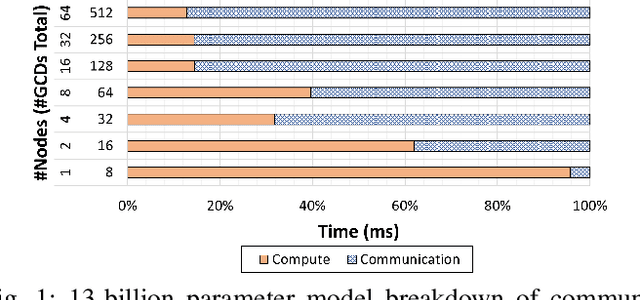
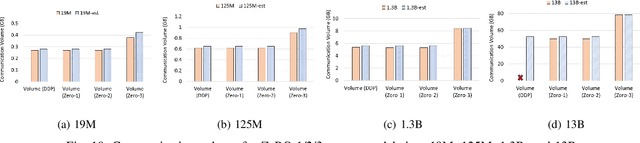
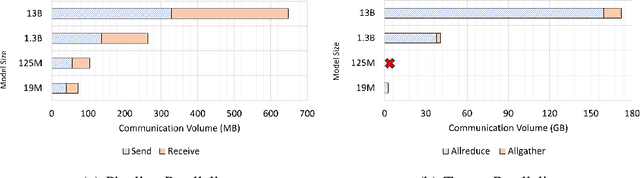
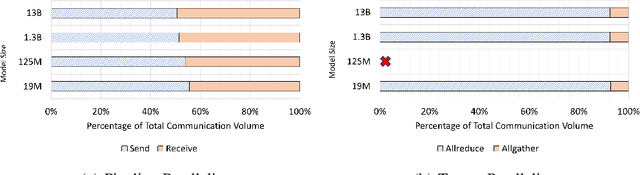
Deep learning (DL) models based on the transformer architecture have revolutionized many DL applications such as large language models (LLMs), vision transformers, audio generation, and time series prediction. Much of this progress has been fueled by distributed training, yet distributed communication remains a substantial bottleneck to training progress. This paper examines the communication behavior of transformer models - that is, how different parallelism schemes used in multi-node/multi-GPU DL Training communicate data in the context of transformers. We use GPT-based language models as a case study of the transformer architecture due to their ubiquity. We validate the empirical results obtained from our communication logs using analytical models. At a high level, our analysis reveals a need to optimize small message point-to-point communication further, correlations between sequence length, per-GPU throughput, model size, and optimizations used, and where to potentially guide further optimizations in framework and HPC middleware design and optimization.