 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Large Language Model Training on Frontier with Low-Bandwidth Partitioning
Jan 08, 2025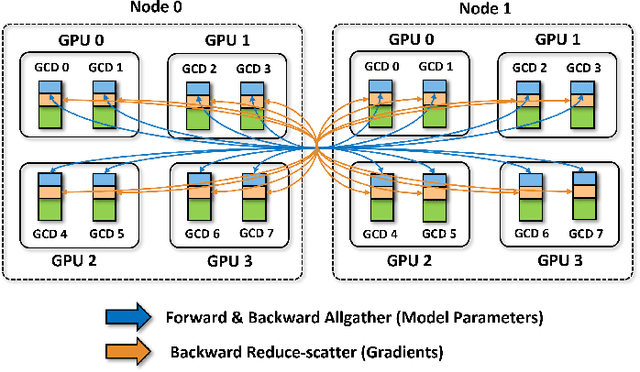
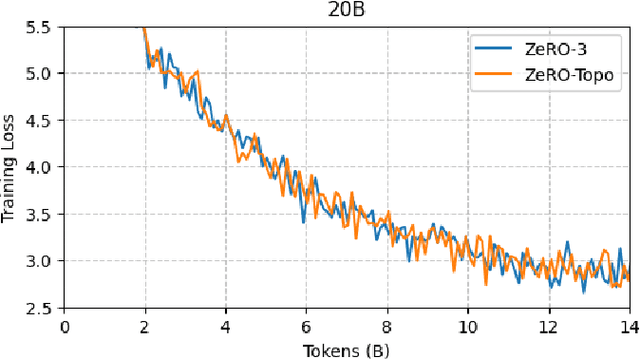
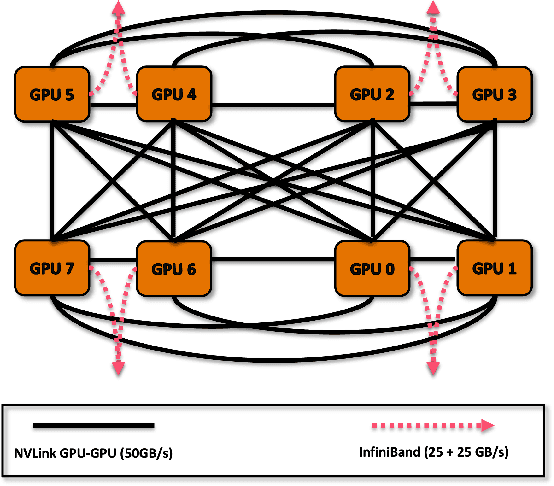
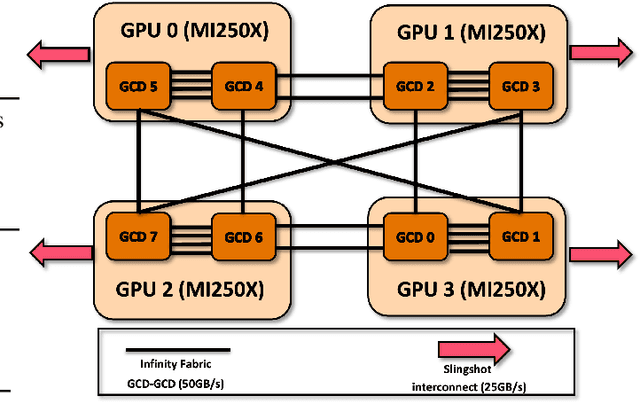
Scaling up Large Language Model(LLM) training involves fitting a tremendous amount of training parameters across a limited number of workers. However, methods like ZeRO-3 that drastically reduce GPU memory pressure often incur heavy communication to ensure global synchronization and consistency. Established efforts such as ZeRO++ use secondary partitions to avoid inter-node communications, given that intra-node GPU-GPU transfer generally has more bandwidth and lower latency than inter-node connections. However, as more capable infrastructure like Frontier, equipped with AMD GPUs, emerged with impressive computing capability, there is a need for investigations on the hardware topology and to develop targeted strategies to improve training efficiency. In this work, we propose a collection of communication and optimization strategies for ZeRO++ to reduce communication costs and improve memory utilization. In this paper, we propose a 3-level hierarchical partitioning specifically for the current Top-1 supercomputing cluster, Frontier, which aims at leveraging various bandwidths across layers of communications (GCD-GCD, GPU-GPU, and inter-node) to reduce communication overhead. For a 20B GPT model, we observe a 1.71x increase in TFLOPS per GPU when compared with ZeRO++ up to 384 GCDs and a scaling efficiency of 0.94 for up to 384 GCDs. To the best of our knowledge, our work is also the first effort to efficiently optimize LLM workloads on Frontier AMD GPUs.
Exploiting Inter-Layer Expert Affinity for Accelerating Mixture-of-Experts Model Inference
Jan 17, 2024



In large language models like the Generative Pre-trained Transformer, the Mixture of Experts paradigm has emerged as a powerful technique for enhancing model expressiveness and accuracy. However, deploying GPT MoE models for parallel inference on distributed systems presents significant challenges, primarily due to the extensive Alltoall communication required for expert routing and aggregation. This communication bottleneck exacerbates the already complex computational landscape, hindering the efficient utilization of high-performance computing resources. In this paper, we propose a lightweight optimization technique called ExFlow, to largely accelerate the inference of these MoE models. We take a new perspective on alleviating the communication overhead by exploiting the inter-layer expert affinity. Unlike previous methods, our solution can be directly applied to pre-trained MoE models without any fine-tuning or accuracy degradation. By proposing a context-coherent expert parallelism on distributed systems, our design only uses one Alltoall communication to deliver the same functionality while previous methods all require two Alltoalls. By carefully examining the conditional probability in tokens' routing across multiple layers, we proved that pre-trained GPT MoE models implicitly exhibit a strong inter-layer expert affinity. We then design an efficient integer programming model to capture such features and show that by properly placing the experts on corresponding GPUs, we can reduce up to 67% cross-GPU routing latency. Our solution beats the cutting-edge MoE implementations with experts from 8 to 64, with up to 2.2x improvement in inference throughput. We further provide a detailed study of how the model implicitly acquires this expert affinity at the very early training stage and how this affinity evolves and stabilizes during training.
Flover: A Temporal Fusion Framework for Efficient Autoregressive Model Parallel Inference
May 24, 2023



In the rapidly evolving field of deep learning, the performance of model inference has become a pivotal aspect as models become more complex and are deployed in diverse applications. Among these, autoregressive models stand out due to their state-of-the-art performance in numerous generative tasks. These models, by design, harness a temporal dependency structure, where the current token's probability distribution is conditioned on preceding tokens. This inherently sequential characteristic, however, adheres to the Markov Chain assumption and lacks temporal parallelism, which poses unique challenges. Particularly in industrial contexts where inference requests, following a Poisson time distribution, necessitate diverse response lengths, this absence of parallelism is more profound. Existing solutions, such as dynamic batching and concurrent model instances, nevertheless, come with severe overheads and a lack of flexibility, these coarse-grained methods fall short of achieving optimal latency and throughput. To address these shortcomings, we propose Flavor -- a temporal fusion framework for efficient inference in autoregressive models, eliminating the need for heuristic settings and applies to a wide range of inference scenarios. By providing more fine-grained parallelism on the temporality of requests and employing an efficient memory shuffle algorithm, Flover achieves up to 11x faster inference on GPT models compared to the cutting-edge solutions provided by NVIDIA Triton FasterTransformer. Crucially, by leveraging the advanced tensor parallel technique, Flover proves efficacious across diverse computational landscapes, from single-GPU setups to multi-node scenarios, thereby offering robust performance optimization that transcends hardware boundaries.
Performance Characterization of using Quantization for DNN Inference on Edge Devices: Extended Version
Mar 09, 2023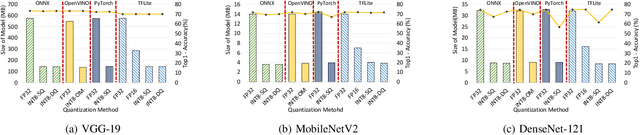

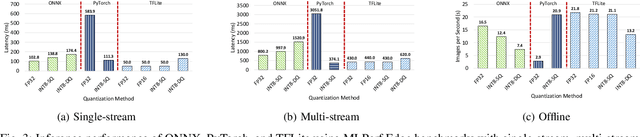
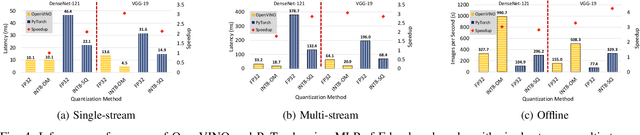
Quantization is a popular technique used in Deep Neural Networks (DNN) inference to reduce the size of models and improve the overall numerical performance by exploiting native hardware. This paper attempts to conduct an elaborate performance characterization of the benefits of using quantization techniques -- mainly FP16/INT8 variants with static and dynamic schemes -- using the MLPerf Edge Inference benchmarking methodology. The study is conducted on Intel x86 processors and Raspberry Pi device with ARM processor. The paper uses a number of DNN inference frameworks, including OpenVINO (for Intel CPUs only), TensorFlow Lite (TFLite), ONNX, and PyTorch with MobileNetV2, VGG-19, and DenseNet-121. The single-stream, multi-stream, and offline scenarios of the MLPerf Edge Inference benchmarks are used for measuring latency and throughput in our experiments. Our evaluation reveals that OpenVINO and TFLite are the most optimized frameworks for Intel CPUs and Raspberry Pi device, respectively. We observe no loss in accuracy except for the static quantization techniques. We also observed the benefits of using quantization for these optimized frameworks. For example, INT8-based quantized models deliver $3.3\times$ and $4\times$ better performance over FP32 using OpenVINO on Intel CPU and TFLite on Raspberry Pi device, respectively, for the MLPerf offline scenario. To the best of our knowledge, this paper is the first one that presents a unique characterization study characterizing the impact of quantization for a range of DNN inference frameworks -- including OpenVINO, TFLite, PyTorch, and ONNX -- on Intel x86 processors and Raspberry Pi device with ARM processor using the MLPerf Edge Inference benchmark methodology.
HyPar-Flow: Exploiting MPI and Keras for Scalable Hybrid-Parallel DNN Training using TensorFlow
Nov 12, 2019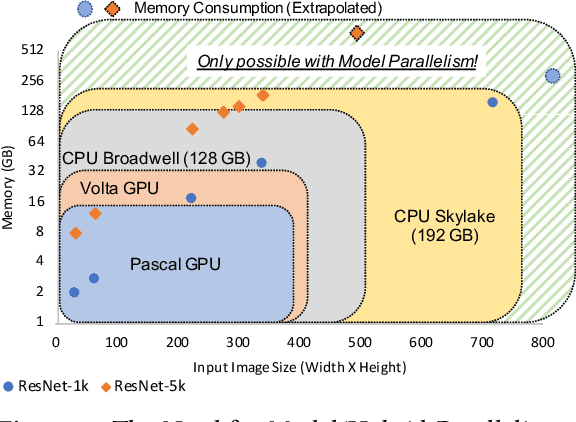
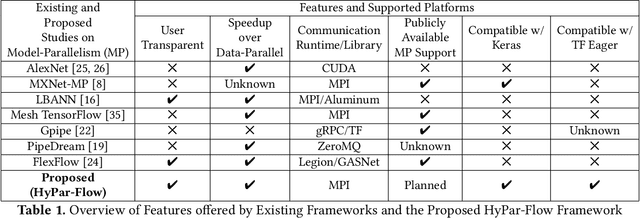
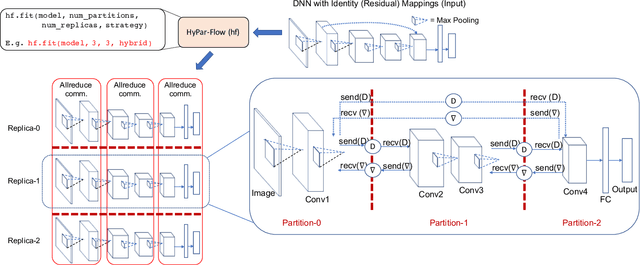

The enormous amount of data and computation required to train DNNs have led to the rise of various parallelization strategies. Broadly, there are two strategies: 1) Data-Parallelism -- replicating the DNN on multiple processes and training on different training samples, and 2) Model-Parallelism -- dividing elements of the DNN itself into partitions across different processes. While data-parallelism has been extensively studied and developed, model-parallelism has received less attention as it is non-trivial to split the model across processes. In this paper, we propose HyPar-Flow: a framework for scalable and user-transparent parallel training of very large DNNs (up to 5,000 layers). We exploit TensorFlow's Eager Execution features and Keras APIs for model definition and distribution. HyPar-Flow exposes a simple API to offer data, model, and hybrid (model + data) parallel training for models defined using the Keras API. Under the hood, we introduce MPI communication primitives like send and recv on layer boundaries for data exchange between model-partitions and allreduce for gradient exchange across model-replicas. Our proposed designs in HyPar-Flow offer up to 3.1x speedup over sequential training for ResNet-110 and up to 1.6x speedup over Horovod-based data-parallel training for ResNet-1001; a model that has 1,001 layers and 30 million parameters. We provide an in-depth performance characterization of the HyPar-Flow framework on multiple HPC systems with diverse CPU architectures including Intel Xeon(s) and AMD EPYC. HyPar-Flow provides 110x speed up on 128 nodes of the Stampede2 cluster at TACC for hybrid-parallel training of ResNet-1001.