 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSARCH: Multimodal Search for Archaeological Archives
Nov 07, 2025In this paper, we describe a multi-modal search system designed to search old archaeological books and reports. This corpus is digitally available as scanned PDFs, but varies widely in the quality of scans. Our pipeline, designed for multi-modal archaeological documents, extracts and indexes text, images (classified into maps, photos, layouts, and others), and tables. We evaluated different retrieval strategies, including keyword-based search, embedding-based models, and a hybrid approach that selects optimal results from both modalities. We report and analyze our preliminary results and discuss future work in this exciting vertical.
OMB-Py: Python Micro-Benchmarks for Evaluating Performance of MPI Libraries on HPC Systems
Oct 20, 2021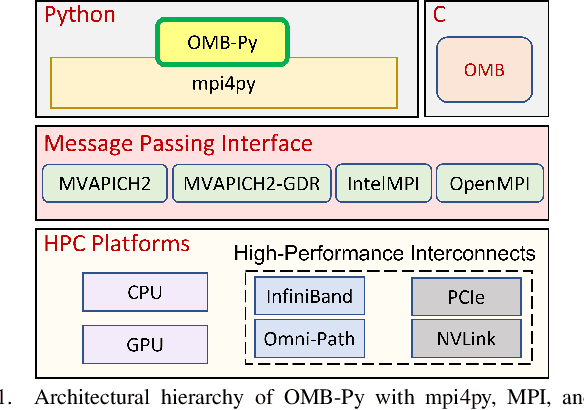
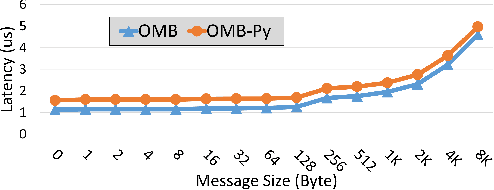
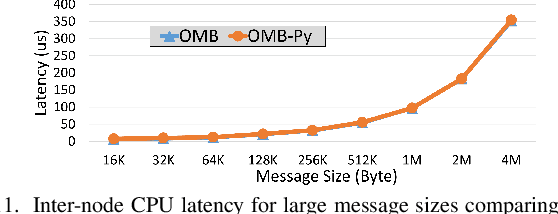
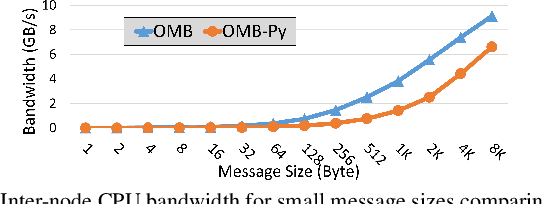
Python has become a dominant programming language for emerging areas like Machine Learning (ML), Deep Learning (DL), and Data Science (DS). An attractive feature of Python is that it provides easy-to-use programming interface while allowing library developers to enhance performance of their applications by harnessing the computing power offered by High Performance Computing (HPC) platforms. Efficient communication is key to scaling applications on parallel systems, which is typically enabled by the Message Passing Interface (MPI) standard and compliant libraries on HPC hardware. mpi4py is a Python-based communication library that provides an MPI-like interface for Python applications allowing application developers to utilize parallel processing elements including GPUs. However, there is currently no benchmark suite to evaluate communication performance of mpi4py -- and Python MPI codes in general -- on modern HPC systems. In order to bridge this gap, we propose OMB-Py -- Python extensions to the open-source OSU Micro-Benchmark (OMB) suite -- aimed to evaluate communication performance of MPI-based parallel applications in Python. To the best of our knowledge, OMB-Py is the first communication benchmark suite for parallel Python applications. OMB-Py consists of a variety of point-to-point and collective communication benchmark tests that are implemented for a range of popular Python libraries including NumPy, CuPy, Numba, and PyCUDA. We also provide Python implementation for several distributed ML algorithms as benchmarks to understand the potential gain in performance for ML/DL workloads. Our evaluation reveals that mpi4py introduces a small overhead when compared to native MPI libraries. We also evaluate the ML/DL workloads and report up to 106x speedup on 224 CPU cores compared to sequential execution. We plan to publicly release OMB-Py to benefit Python HPC community.
HyPar-Flow: Exploiting MPI and Keras for Scalable Hybrid-Parallel DNN Training using TensorFlow
Nov 12, 2019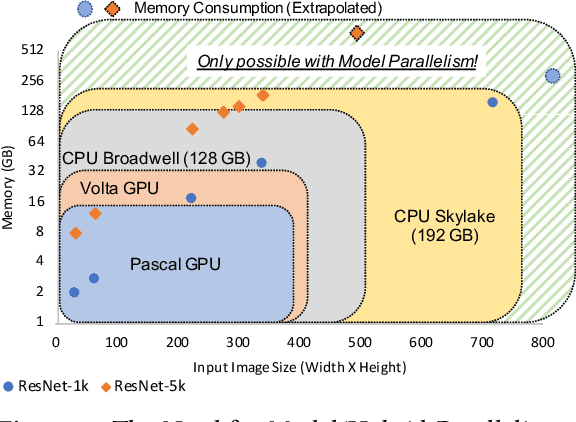
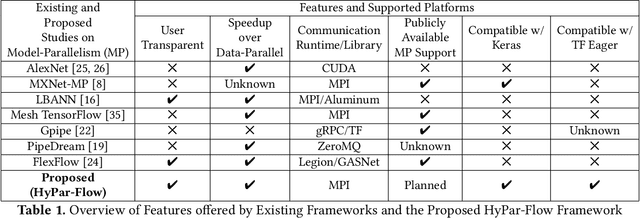
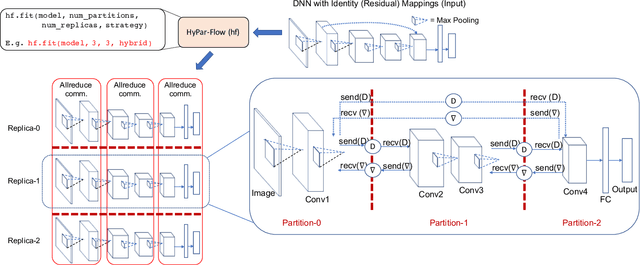

The enormous amount of data and computation required to train DNNs have led to the rise of various parallelization strategies. Broadly, there are two strategies: 1) Data-Parallelism -- replicating the DNN on multiple processes and training on different training samples, and 2) Model-Parallelism -- dividing elements of the DNN itself into partitions across different processes. While data-parallelism has been extensively studied and developed, model-parallelism has received less attention as it is non-trivial to split the model across processes. In this paper, we propose HyPar-Flow: a framework for scalable and user-transparent parallel training of very large DNNs (up to 5,000 layers). We exploit TensorFlow's Eager Execution features and Keras APIs for model definition and distribution. HyPar-Flow exposes a simple API to offer data, model, and hybrid (model + data) parallel training for models defined using the Keras API. Under the hood, we introduce MPI communication primitives like send and recv on layer boundaries for data exchange between model-partitions and allreduce for gradient exchange across model-replicas. Our proposed designs in HyPar-Flow offer up to 3.1x speedup over sequential training for ResNet-110 and up to 1.6x speedup over Horovod-based data-parallel training for ResNet-1001; a model that has 1,001 layers and 30 million parameters. We provide an in-depth performance characterization of the HyPar-Flow framework on multiple HPC systems with diverse CPU architectures including Intel Xeon(s) and AMD EPYC. HyPar-Flow provides 110x speed up on 128 nodes of the Stampede2 cluster at TACC for hybrid-parallel training of ResNet-1001.