 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyPar-Flow: Exploiting MPI and Keras for Scalable Hybrid-Parallel DNN Training using TensorFlow
Paper and Code
Nov 12, 2019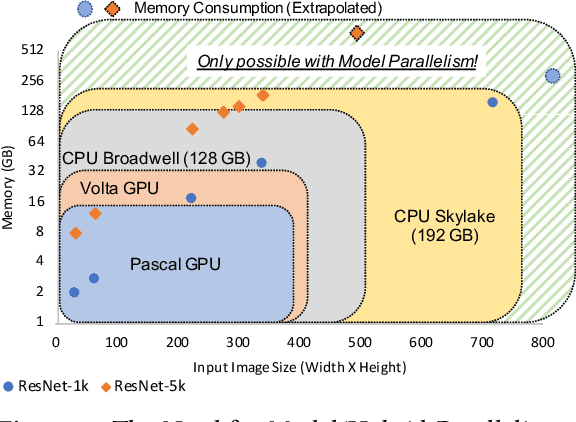
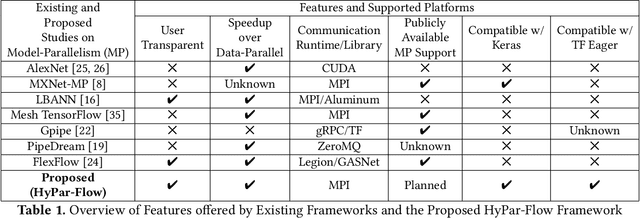
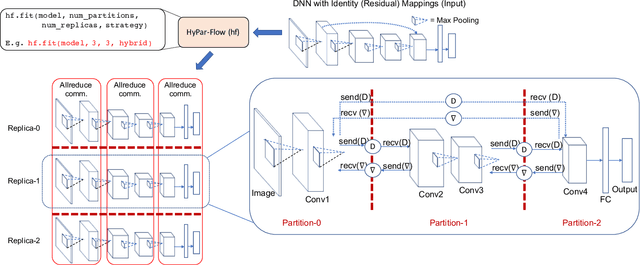

The enormous amount of data and computation required to train DNNs have led to the rise of various parallelization strategies. Broadly, there are two strategies: 1) Data-Parallelism -- replicating the DNN on multiple processes and training on different training samples, and 2) Model-Parallelism -- dividing elements of the DNN itself into partitions across different processes. While data-parallelism has been extensively studied and developed, model-parallelism has received less attention as it is non-trivial to split the model across processes. In this paper, we propose HyPar-Flow: a framework for scalable and user-transparent parallel training of very large DNNs (up to 5,000 layers). We exploit TensorFlow's Eager Execution features and Keras APIs for model definition and distribution. HyPar-Flow exposes a simple API to offer data, model, and hybrid (model + data) parallel training for models defined using the Keras API. Under the hood, we introduce MPI communication primitives like send and recv on layer boundaries for data exchange between model-partitions and allreduce for gradient exchange across model-replicas. Our proposed designs in HyPar-Flow offer up to 3.1x speedup over sequential training for ResNet-110 and up to 1.6x speedup over Horovod-based data-parallel training for ResNet-1001; a model that has 1,001 layers and 30 million parameters. We provide an in-depth performance characterization of the HyPar-Flow framework on multiple HPC systems with diverse CPU architectures including Intel Xeon(s) and AMD EPYC. HyPar-Flow provides 110x speed up on 128 nodes of the Stampede2 cluster at TACC for hybrid-parallel training of ResNet-1001.