 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying the Communication Characteristics for Distributed Transformer Models
Aug 19, 2024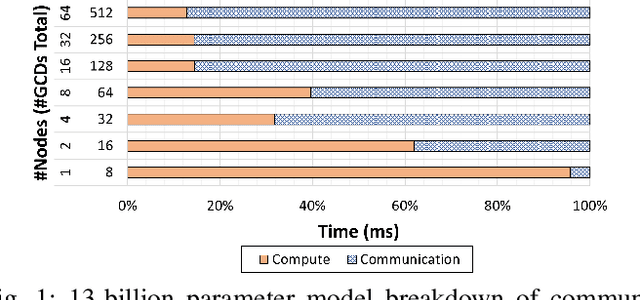
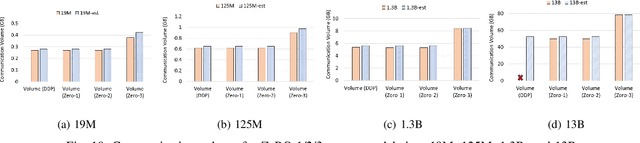
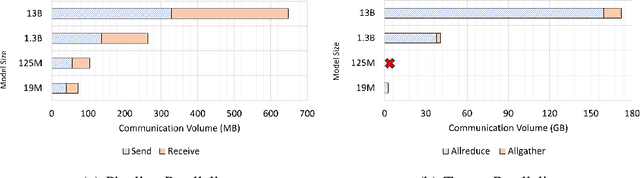
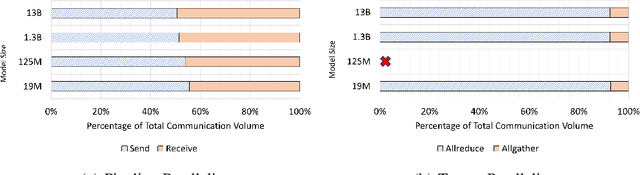
Deep learning (DL) models based on the transformer architecture have revolutionized many DL applications such as large language models (LLMs), vision transformers, audio generation, and time series prediction. Much of this progress has been fueled by distributed training, yet distributed communication remains a substantial bottleneck to training progress. This paper examines the communication behavior of transformer models - that is, how different parallelism schemes used in multi-node/multi-GPU DL Training communicate data in the context of transformers. We use GPT-based language models as a case study of the transformer architecture due to their ubiquity. We validate the empirical results obtained from our communication logs using analytical models. At a high level, our analysis reveals a need to optimize small message point-to-point communication further, correlations between sequence length, per-GPU throughput, model size, and optimizations used, and where to potentially guide further optimizations in framework and HPC middleware design and optimization.
MCR-DL: Mix-and-Match Communication Runtime for Deep Learning
Mar 15, 2023



In recent years, the training requirements of many state-of-the-art Deep Learning (DL) models have scaled beyond the compute and memory capabilities of a single processor, and necessitated distribution among processors. Training such massive models necessitates advanced parallelism strategies to maintain efficiency. However, such distributed DL parallelism strategies require a varied mixture of collective and point-to-point communication operations across a broad range of message sizes and scales. Examples of models using advanced parallelism strategies include Deep Learning Recommendation Models (DLRM) and Mixture-of-Experts (MoE). Communication libraries' performance varies wildly across different communication operations, scales, and message sizes. We propose MCR-DL: an extensible DL communication framework that supports all point-to-point and collective operations while enabling users to dynamically mix-and-match communication backends for a given operation without deadlocks. MCR-DL also comes packaged with a tuning suite for dynamically selecting the best communication backend for a given input tensor. We select DeepSpeed-MoE and DLRM as candidate DL models and demonstrate a 31% improvement in DS-MoE throughput on 256 V100 GPUs on the Lassen HPC system. Further, we achieve a 20% throughput improvement in a dense Megatron-DeepSpeed model and a 25% throughput improvement in DLRM on 32 A100 GPUs with the Theta-GPU HPC system.
Performance Characterization of using Quantization for DNN Inference on Edge Devices: Extended Version
Mar 09, 2023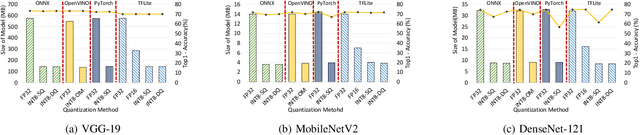

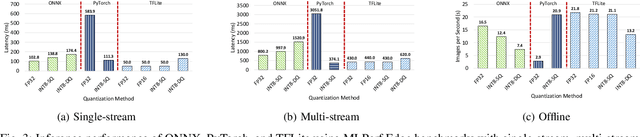
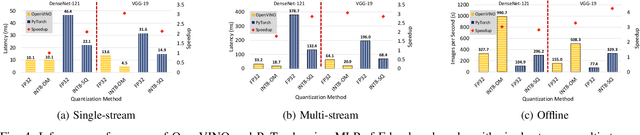
Quantization is a popular technique used in Deep Neural Networks (DNN) inference to reduce the size of models and improve the overall numerical performance by exploiting native hardware. This paper attempts to conduct an elaborate performance characterization of the benefits of using quantization techniques -- mainly FP16/INT8 variants with static and dynamic schemes -- using the MLPerf Edge Inference benchmarking methodology. The study is conducted on Intel x86 processors and Raspberry Pi device with ARM processor. The paper uses a number of DNN inference frameworks, including OpenVINO (for Intel CPUs only), TensorFlow Lite (TFLite), ONNX, and PyTorch with MobileNetV2, VGG-19, and DenseNet-121. The single-stream, multi-stream, and offline scenarios of the MLPerf Edge Inference benchmarks are used for measuring latency and throughput in our experiments. Our evaluation reveals that OpenVINO and TFLite are the most optimized frameworks for Intel CPUs and Raspberry Pi device, respectively. We observe no loss in accuracy except for the static quantization techniques. We also observed the benefits of using quantization for these optimized frameworks. For example, INT8-based quantized models deliver $3.3\times$ and $4\times$ better performance over FP32 using OpenVINO on Intel CPU and TFLite on Raspberry Pi device, respectively, for the MLPerf offline scenario. To the best of our knowledge, this paper is the first one that presents a unique characterization study characterizing the impact of quantization for a range of DNN inference frameworks -- including OpenVINO, TFLite, PyTorch, and ONNX -- on Intel x86 processors and Raspberry Pi device with ARM processor using the MLPerf Edge Inference benchmark methodology.
Shisha: Online scheduling of CNN pipelines on heterogeneous architectures
Feb 23, 2022

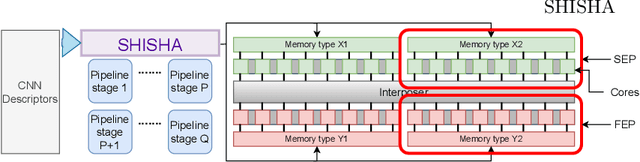
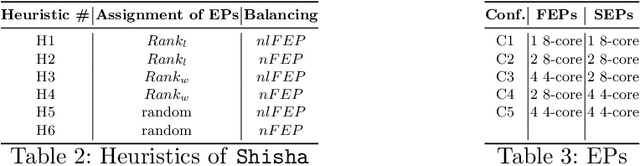
Chiplets have become a common methodology in modern chip design. Chiplets improve yield and enable heterogeneity at the level of cores, memory subsystem and the interconnect. Convolutional Neural Networks (CNNs) have high computational, bandwidth and memory capacity requirements owing to the increasingly large amount of weights. Thus to exploit chiplet-based architectures, CNNs must be optimized in terms of scheduling and workload distribution among computing resources. We propose Shisha, an online approach to generate and schedule parallel CNN pipelines on chiplet architectures. Shisha targets heterogeneity in compute performance and memory bandwidth and tunes the pipeline schedule through a fast online exploration technique. We compare Shisha with Simulated Annealing, Hill Climbing and Pipe-Search. On average, the convergence time is improved by ~35x in Shisha compared to other exploration algorithms. Despite the quick exploration, Shisha's solution is often better than that of other heuristic exploration algorithms.