 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompiler-Assisted Speculative Sampling for Accelerated LLM Inference on Heterogeneous Edge Devices
Feb 08, 2026LLM deployment on resource-constrained edge devices faces severe latency constraints, particularly in real-time applications where delayed responses can compromise safety or usability. Among many approaches to mitigate the inefficiencies of sequential token-by-token generation, Speculative Decoding (SD) has emerged as a promising technique. However, SD at the edge is hindered by two major challenges: (1) integrating SD into a compiler-based workflow without sacrificing performance or programmability, and (2) exploiting the heterogeneous compute resources of modern SoCs through carefully designed partitioning strategies. This work addresses these challenges by using an analytical cost model that explores heterogeneous hardware configurations and guides coarse-grained partitioning of LLM subgraphs, particularly with edge-typical short input sequence lengths. The cost model predicts when speculative sampling and heterogeneous execution are jointly beneficial and is validated on an edge device featuring a hexacore Cortex-A CPU and a Mali GPU, revealing up to 1.68$\times$ speedup for translation tasks, closely matching analytic expectations.
Leveraging Stochastic Depth Training for Adaptive Inference
May 23, 2025Dynamic DNN optimization techniques such as layer-skipping offer increased adaptability and efficiency gains but can lead to i) a larger memory footprint as in decision gates, ii) increased training complexity (e.g., with non-differentiable operations), and iii) less control over performance-quality trade-offs due to its inherent input-dependent execution. To approach these issues, we propose a simpler yet effective alternative for adaptive inference with a zero-overhead, single-model, and time-predictable inference. Central to our approach is the observation that models trained with Stochastic Depth -- a method for faster training of residual networks -- become more resilient to arbitrary layer-skipping at inference time. We propose a method to first select near Pareto-optimal skipping configurations from a stochastically-trained model to adapt the inference at runtime later. Compared to original ResNets, our method shows improvements of up to 2X in power efficiency at accuracy drops as low as 0.71%.
Full-Stack Optimization for CAM-Only DNN Inference
Jan 23, 2024



The accuracy of neural networks has greatly improved across various domains over the past years. Their ever-increasing complexity, however, leads to prohibitively high energy demands and latency in von Neumann systems. Several computing-in-memory (CIM) systems have recently been proposed to overcome this, but trade-offs involving accuracy, hardware reliability, and scalability for large models remain a challenge. Additionally, for some CIM designs, the activation movement still requires considerable time and energy. This paper explores the combination of algorithmic optimizations for ternary weight neural networks and associative processors (APs) implemented using racetrack memory (RTM). We propose a novel compilation flow to optimize convolutions on APs by reducing their arithmetic intensity. By leveraging the benefits of RTM-based APs, this approach substantially reduces data transfers within the memory while addressing accuracy, energy efficiency, and reliability concerns. Concretely, our solution improves the energy efficiency of ResNet-18 inference on ImageNet by 7.5x compared to crossbar in-memory accelerators while retaining software accuracy.
Shisha: Online scheduling of CNN pipelines on heterogeneous architectures
Feb 23, 2022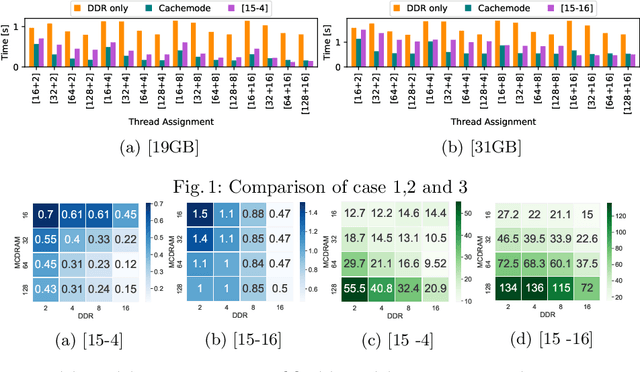

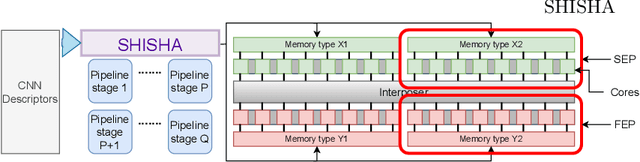
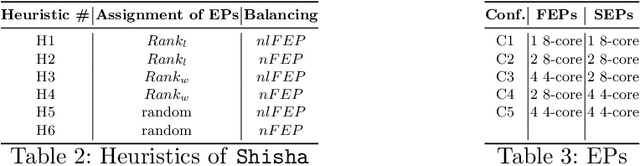
Chiplets have become a common methodology in modern chip design. Chiplets improve yield and enable heterogeneity at the level of cores, memory subsystem and the interconnect. Convolutional Neural Networks (CNNs) have high computational, bandwidth and memory capacity requirements owing to the increasingly large amount of weights. Thus to exploit chiplet-based architectures, CNNs must be optimized in terms of scheduling and workload distribution among computing resources. We propose Shisha, an online approach to generate and schedule parallel CNN pipelines on chiplet architectures. Shisha targets heterogeneity in compute performance and memory bandwidth and tunes the pipeline schedule through a fast online exploration technique. We compare Shisha with Simulated Annealing, Hill Climbing and Pipe-Search. On average, the convergence time is improved by ~35x in Shisha compared to other exploration algorithms. Despite the quick exploration, Shisha's solution is often better than that of other heuristic exploration algorithms.
Brain-inspired Cognition in Next Generation Racetrack Memories
Nov 03, 2021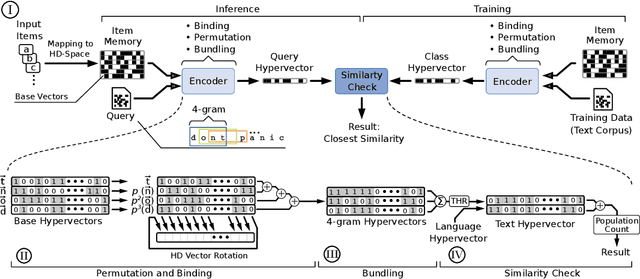
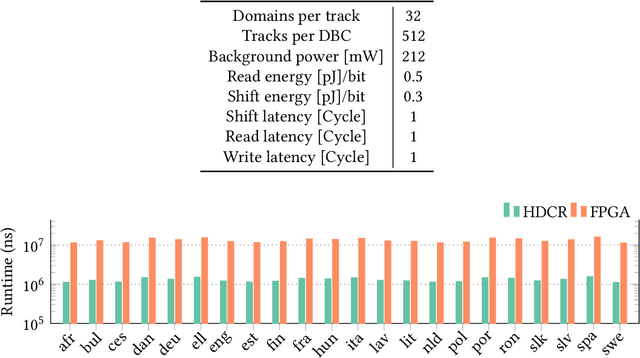
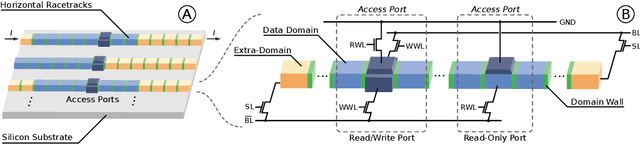
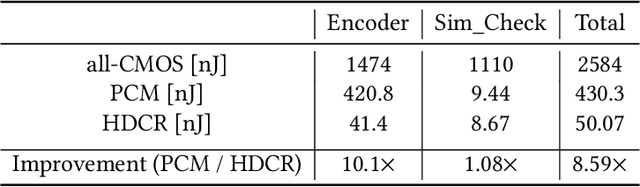
Hyperdimensional computing (HDC) is an emerging computational framework inspired by the brain that operates on vectors with thousands of dimensions to emulate cognition. Unlike conventional computational frameworks that operate on numbers, HDC, like the brain, uses high dimensional random vectors and is capable of one-shot learning. HDC is based on a well-defined set of arithmetic operations and is highly error-resilient. The core operations of HDC manipulate HD vectors in bulk bit-wise fashion, offering many opportunities to leverage parallelism. Unfortunately, on conventional Von-Neuman architectures, the continuous movement of HD vectors among the processor and the memory can make the cognition task prohibitively slow and energy-intensive. Hardware accelerators only marginally improve related metrics. On the contrary, only partial implementation of an HDC framework inside memory, using emerging memristive devices, has reported considerable performance/energy gains. This paper presents an architecture based on racetrack memory (RTM) to conduct and accelerate the entire HDC framework within the memory. The proposed solution requires minimal additional CMOS circuitry and uses a read operation across multiple domains in RTMs called transverse read (TR) to realize exclusive-or (XOR) and addition operations. To minimize the overhead the CMOS circuitry, we propose an RTM nanowires-based counting mechanism that leverages the TR operation and the standard RTM operations. Using language recognition as the use case demonstrates 7.8x and 5.3x reduction in the overall runtime and energy consumption compared to the FPGA design, respectively. Compared to the state-of-the-art in-memory implementation, the proposed HDC system reduces the energy consumption by 8.6x.
A Reinforcement Learning Environment for Polyhedral Optimizations
Apr 29, 2021
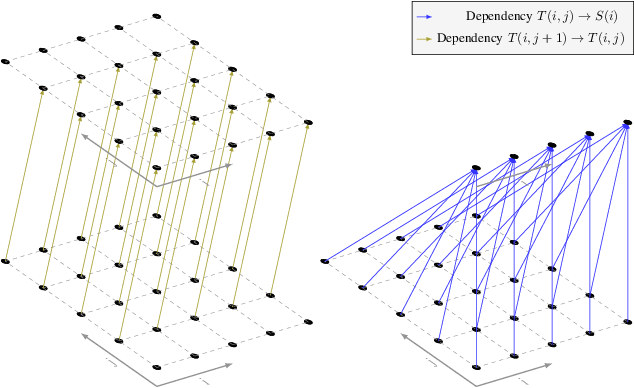


The polyhedral model allows a structured way of defining semantics-preserving transformations to improve the performance of a large class of loops. Finding profitable points in this space is a hard problem which is usually approached by heuristics that generalize from domain-expert knowledge. Existing problem formulations in state-of-the-art heuristics depend on the shape of particular loops, making it hard to leverage generic and more powerful optimization techniques from the machine learning domain. In this paper, we propose PolyGym, a shape-agnostic formulation for the space of legal transformations in the polyhedral model as a Markov Decision Process (MDP). Instead of using transformations, the formulation is based on an abstract space of possible schedules. In this formulation, states model partial schedules, which are constructed by actions that are reusable across different loops. With a simple heuristic to traverse the space, we demonstrate that our formulation is powerful enough to match and outperform state-of-the-art heuristics. On the Polybench benchmark suite, we found transformations that led to a speedup of 3.39x over LLVM O3, which is 1.83x better than the speedup achieved by ISL. Our generic MDP formulation enables using reinforcement learning to learn optimization policies over a wide range of loops. This also contributes to the emerging field of machine learning in compilers, as it exposes a novel problem formulation that can push the limits of existing methods.