 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemlirSynth: Automatic, Retargetable Program Raising in Multi-Level IR using Program Synthesis
Oct 06, 2023MLIR is an emerging compiler infrastructure for modern hardware, but existing programs cannot take advantage of MLIR's high-performance compilation if they are described in lower-level general purpose languages. Consequently, to avoid programs needing to be rewritten manually, this has led to efforts to automatically raise lower-level to higher-level dialects in MLIR. However, current methods rely on manually-defined raising rules, which limit their applicability and make them challenging to maintain as MLIR dialects evolve. We present mlirSynth -- a novel approach which translates programs from lower-level MLIR dialects to high-level ones without manually defined rules. Instead, it uses available dialect definitions to construct a program space and searches it effectively using type constraints and equivalences. We demonstrate its effectiveness \revi{by raising C programs} to two distinct high-level MLIR dialects, which enables us to use existing high-level dialect specific compilation flows. On Polybench, we show a greater coverage than previous approaches, resulting in geomean speedups of 2.5x (Intel) and 3.4x (AMD) over state-of-the-art compilation flows for the C programming language. mlirSynth also enables retargetability to domain-specific accelerators, resulting in a geomean speedup of 21.6x on a TPU.
A Reinforcement Learning Environment for Polyhedral Optimizations
Apr 29, 2021
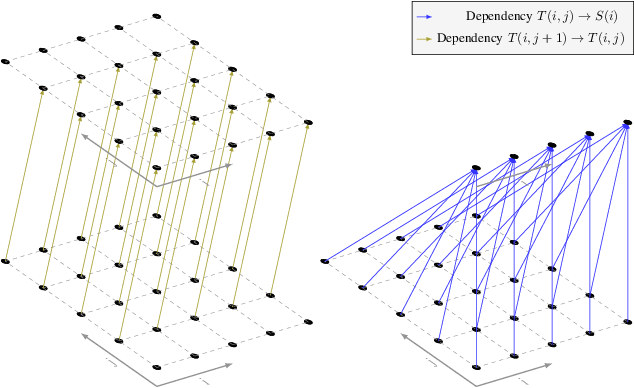


The polyhedral model allows a structured way of defining semantics-preserving transformations to improve the performance of a large class of loops. Finding profitable points in this space is a hard problem which is usually approached by heuristics that generalize from domain-expert knowledge. Existing problem formulations in state-of-the-art heuristics depend on the shape of particular loops, making it hard to leverage generic and more powerful optimization techniques from the machine learning domain. In this paper, we propose PolyGym, a shape-agnostic formulation for the space of legal transformations in the polyhedral model as a Markov Decision Process (MDP). Instead of using transformations, the formulation is based on an abstract space of possible schedules. In this formulation, states model partial schedules, which are constructed by actions that are reusable across different loops. With a simple heuristic to traverse the space, we demonstrate that our formulation is powerful enough to match and outperform state-of-the-art heuristics. On the Polybench benchmark suite, we found transformations that led to a speedup of 3.39x over LLVM O3, which is 1.83x better than the speedup achieved by ISL. Our generic MDP formulation enables using reinforcement learning to learn optimization policies over a wide range of loops. This also contributes to the emerging field of machine learning in compilers, as it exposes a novel problem formulation that can push the limits of existing methods.