 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Structured Tensor Algebra
Jul 18, 2024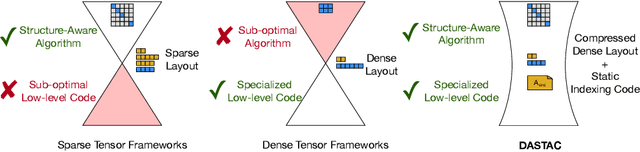


Tensor algebra is a crucial component for data-intensive workloads such as machine learning and scientific computing. As the complexity of data grows, scientists often encounter a dilemma between the highly specialized dense tensor algebra and efficient structure-aware algorithms provided by sparse tensor algebra. In this paper, we introduce DASTAC, a framework to propagate the tensors's captured high-level structure down to low-level code generation by incorporating techniques such as automatic data layout compression, polyhedral analysis, and affine code generation. Our methodology reduces memory footprint by automatically detecting the best data layout, heavily benefits from polyhedral optimizations, leverages further optimizations, and enables parallelization through MLIR. Through extensive experimentation, we show that DASTAC achieves 1 to 2 orders of magnitude speedup over TACO, a state-of-the-art sparse tensor compiler, and StructTensor, a state-of-the-art structured tensor algebra compiler, with a significantly lower memory footprint.
mlirSynth: Automatic, Retargetable Program Raising in Multi-Level IR using Program Synthesis
Oct 06, 2023MLIR is an emerging compiler infrastructure for modern hardware, but existing programs cannot take advantage of MLIR's high-performance compilation if they are described in lower-level general purpose languages. Consequently, to avoid programs needing to be rewritten manually, this has led to efforts to automatically raise lower-level to higher-level dialects in MLIR. However, current methods rely on manually-defined raising rules, which limit their applicability and make them challenging to maintain as MLIR dialects evolve. We present mlirSynth -- a novel approach which translates programs from lower-level MLIR dialects to high-level ones without manually defined rules. Instead, it uses available dialect definitions to construct a program space and searches it effectively using type constraints and equivalences. We demonstrate its effectiveness \revi{by raising C programs} to two distinct high-level MLIR dialects, which enables us to use existing high-level dialect specific compilation flows. On Polybench, we show a greater coverage than previous approaches, resulting in geomean speedups of 2.5x (Intel) and 3.4x (AMD) over state-of-the-art compilation flows for the C programming language. mlirSynth also enables retargetability to domain-specific accelerators, resulting in a geomean speedup of 21.6x on a TPU.
Compiling Neural Networks for a Computational Memory Accelerator
Mar 05, 2020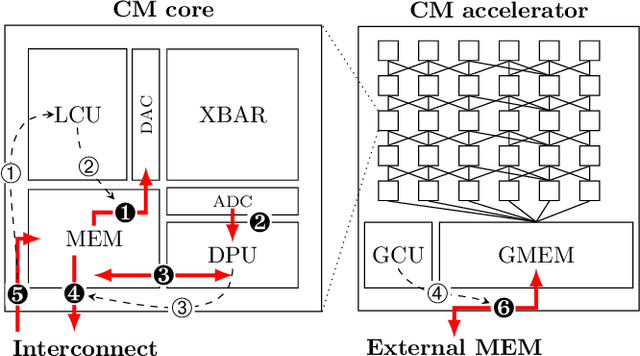

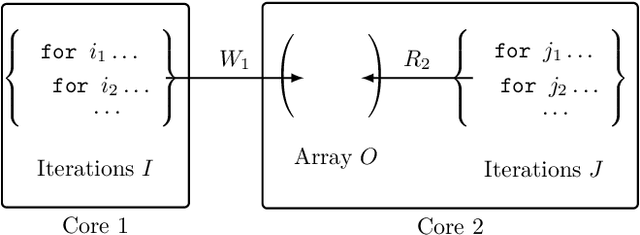
Computational memory (CM) is a promising approach for accelerating inference on neural networks (NN) by using enhanced memories that, in addition to storing data, allow computations on them. One of the main challenges of this approach is defining a hardware/software interface that allows a compiler to map NN models for efficient execution on the underlying CM accelerator. This is a non-trivial task because efficiency dictates that the CM accelerator is explicitly programmed as a dataflow engine where the execution of the different NN layers form a pipeline. In this paper, we present our work towards a software stack for executing ML models on such a multi-core CM accelerator. We describe an architecture for the hardware and software, and focus on the problem of implementing the appropriate control logic so that data dependencies are respected. We propose a solution to the latter that is based on polyhedral compilation.