 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompiling Neural Networks for a Computational Memory Accelerator
Mar 05, 2020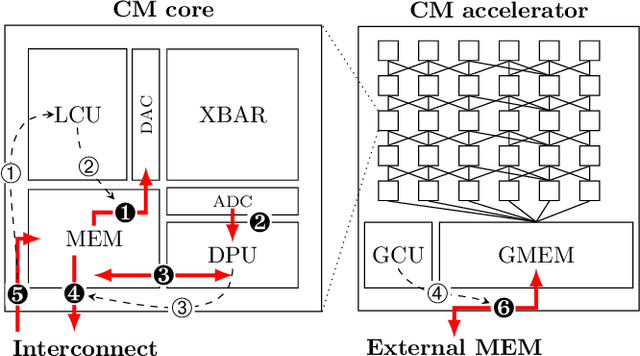

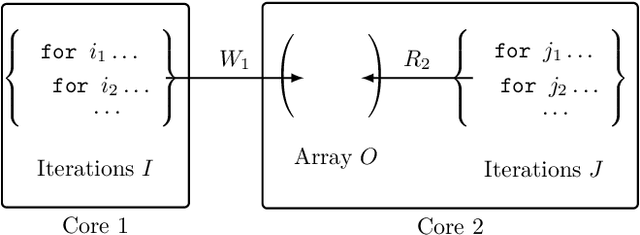
Computational memory (CM) is a promising approach for accelerating inference on neural networks (NN) by using enhanced memories that, in addition to storing data, allow computations on them. One of the main challenges of this approach is defining a hardware/software interface that allows a compiler to map NN models for efficient execution on the underlying CM accelerator. This is a non-trivial task because efficiency dictates that the CM accelerator is explicitly programmed as a dataflow engine where the execution of the different NN layers form a pipeline. In this paper, we present our work towards a software stack for executing ML models on such a multi-core CM accelerator. We describe an architecture for the hardware and software, and focus on the problem of implementing the appropriate control logic so that data dependencies are respected. We propose a solution to the latter that is based on polyhedral compilation.
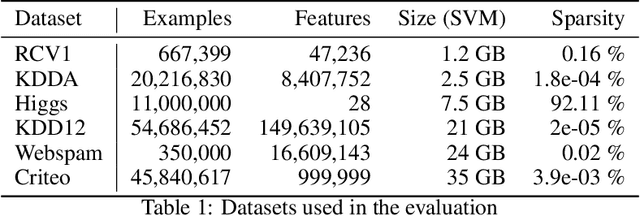
Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle
Sep 11, 2019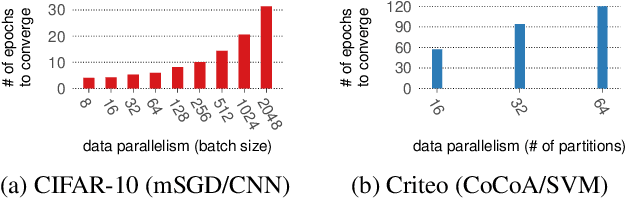
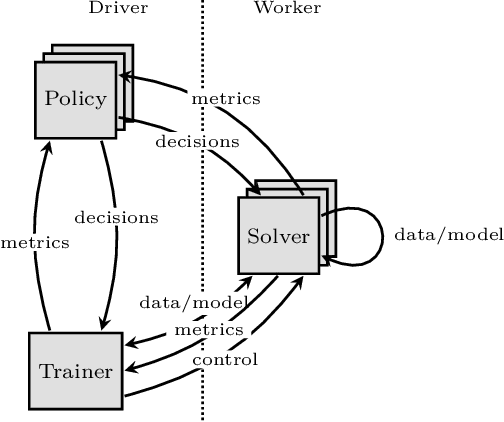
Distributed machine learning training is one of the most common and important workloads running on data centers today, but it is rarely executed alone. Instead, to reduce costs, computing resources are consolidated and shared by different applications. In this scenario, elasticity and proper load balancing are vital to maximize efficiency, fairness, and utilization. Currently, most distributed training frameworks do not support the aforementioned properties. A few exceptions that do support elasticity, imitate generic distributed frameworks and use micro-tasks. In this paper we illustrate that micro-tasks are problematic for machine learning applications, because they require a high degree of parallelism which hinders the convergence of distributed training at a pure algorithmic level (i.e., ignoring overheads and scalability limitations). To address this, we propose Chicle, a new elastic distributed training framework which exploits the nature of machine learning algorithms to implement elasticity and load balancing without micro-tasks. We use Chicle to train deep neural network as well as generalized linear models, and show that Chicle achieves performance competitive with state of the art rigid frameworks, while efficiently enabling elastic execution and dynamic load balancing.
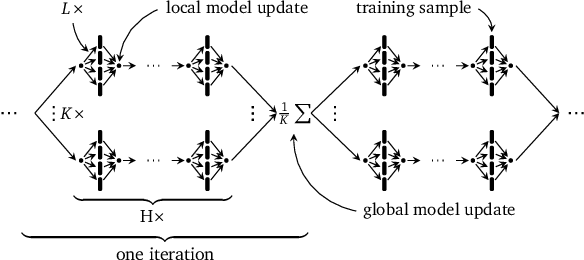
Elastic CoCoA: Scaling In to Improve Convergence
Nov 06, 2018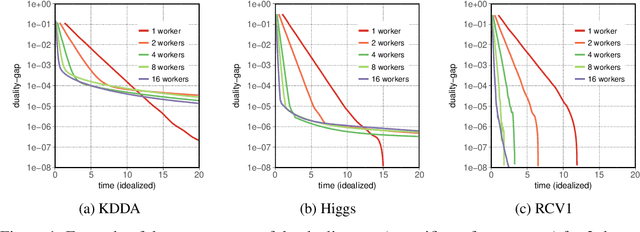
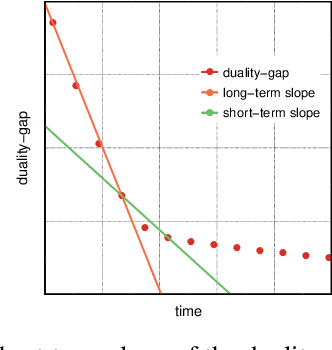

In this paper we experimentally analyze the convergence behavior of CoCoA and show, that the number of workers required to achieve the highest convergence rate at any point in time, changes over the course of the training. Based on this observation, we build Chicle, an elastic framework that dynamically adjusts the number of workers based on feedback from the training algorithm, in order to select the number of workers that results in the highest convergence rate. In our evaluation of 6 datasets, we show that Chicle is able to accelerate the time-to-accuracy by a factor of up to 5.96x compared to the best static setting, while being robust enough to find an optimal or near-optimal setting automatically in most cases.
Parallel training of linear models without compromising convergence
Nov 05, 2018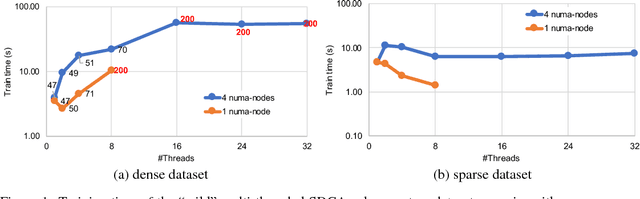
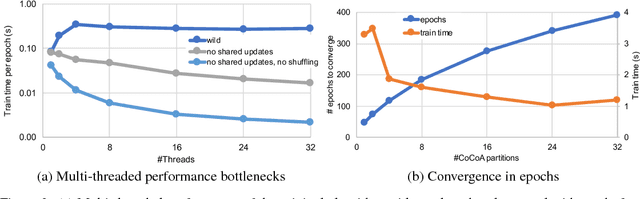
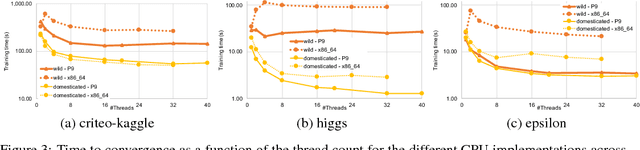
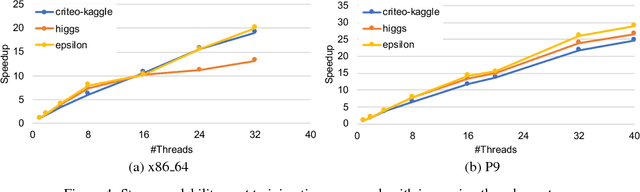
In this paper we analyze, evaluate, and improve the performance of training generalized linear models on modern CPUs. We start with a state-of-the-art asynchronous parallel training algorithm, identify system-level performance bottlenecks, and apply optimizations that improve data parallelism, cache line locality, and cache line prefetching of the algorithm. These modifications reduce the per-epoch run-time significantly, but take a toll on algorithm convergence in terms of the required number of epochs. To alleviate these shortcomings of our systems-optimized version, we propose a novel, dynamic data partitioning scheme across threads which allows us to approach the convergence of the sequential version. The combined set of optimizations result in a consistent bottom line speedup in convergence of up to $\times12$ compared to the initial asynchronous parallel training algorithm and up to $\times42$, compared to state of the art implementations (scikit-learn and h2o) on a range of multi-core CPU architectures.