 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Lokahi Prototype: Toward the automatic Extraction of Entity Relationship Models from Text
Jan 14, 2022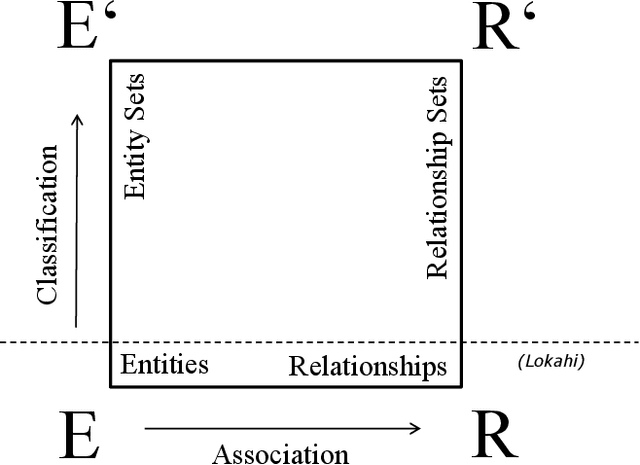
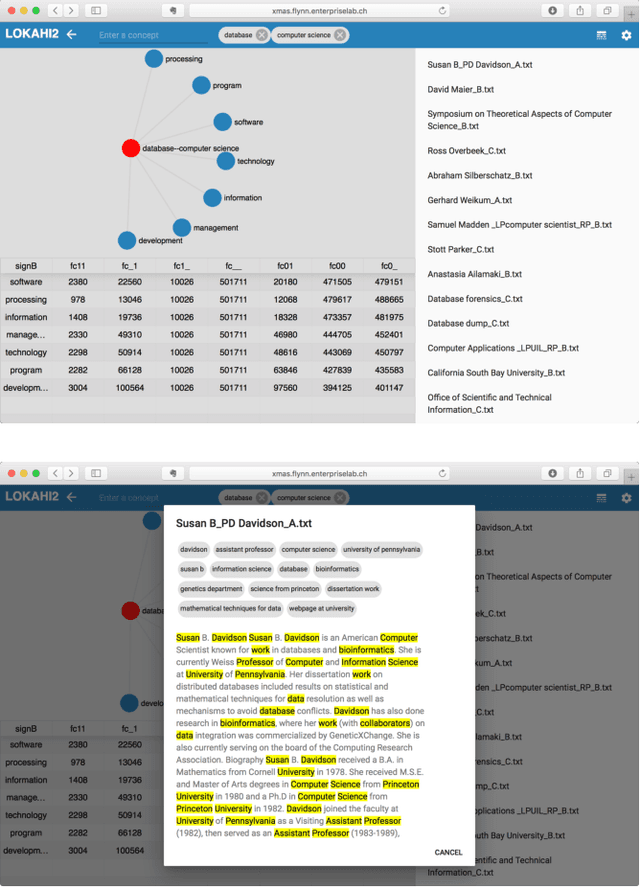
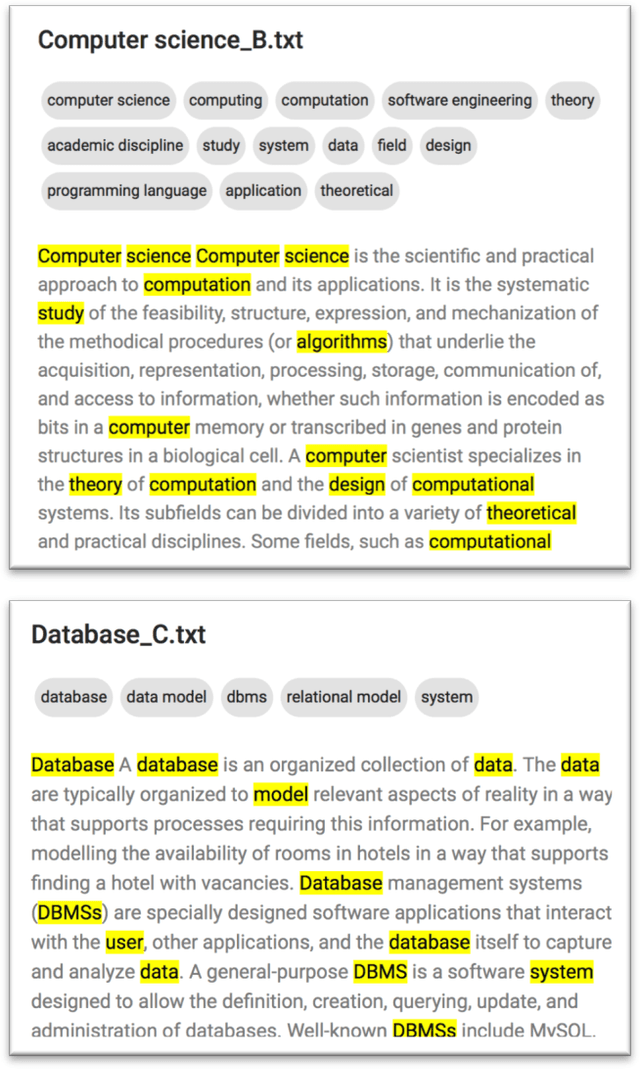
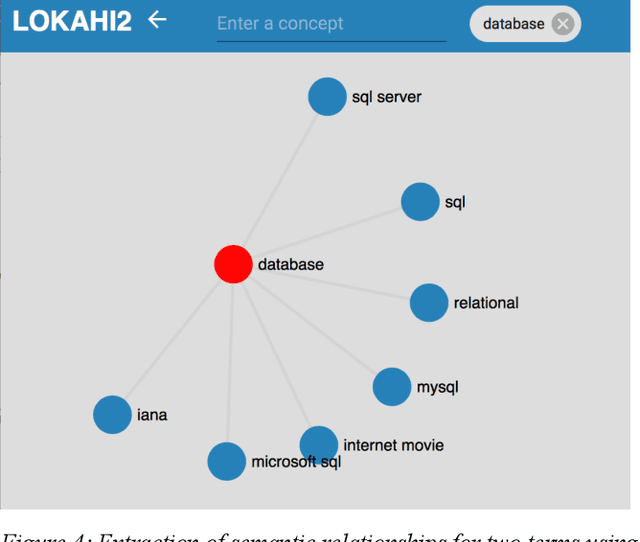
Entity relationship extraction envisions the automatic generation of semantic data models from collections of text, by automatic recognition of entities, by association of entities to form relationships, and by classifying these instances to assign them to entity sets (or classes) and relationship sets (or associations). As a first step in this direction, the Lokahi prototype can extract entities based on the TF*IDF measure, and generate semantic relationships based on document-level co-occurrence statistics, for example with likelihood ratios and pointwise mutual information. This paper presents results of an explorative, prototypical, qualitative and synthetic research, summarizes insights from two research projects and, based on this, indicates an outline for further research in the field of entity relationship extraction from text.
Efficient and Accurate In-Database Machine Learning with SQL Code Generation in Python
Apr 07, 2021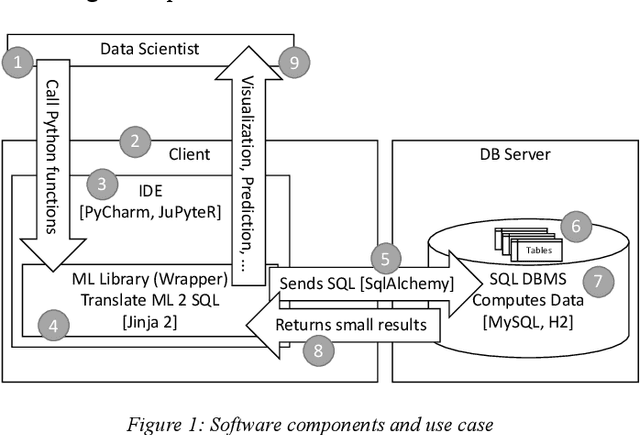
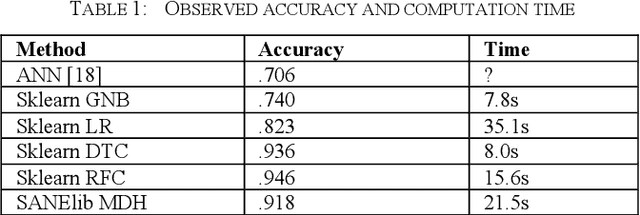


Following an analysis of the advantages of SQL-based Machine Learning (ML) and a short literature survey of the field, we describe a novel method for In-Database Machine Learning (IDBML). We contribute a process for SQL-code generation in Python using template macros in Jinja2 as well as the prototype implementation of the process. We describe our implementation of the process to compute multidimensional histogram (MDH) probability estimation in SQL. For this, we contribute and implement a novel discretization method called equal quantized rank (EQR) variable-width binning. Based on this, we provide data gathered in a benchmarking experiment for the quantitative empirical evaluation of our method and system using the Covertype dataset. We measured accuracy and computation time. Our multidimensional probability estimation was significantly more accurate than Naive Bayes, which assumes independent one-dimensional probabilities and/or densities. Also, our method was significantly more accurate and faster than logistic regression. However, our method was 2-3% less accurate than the best current state-of-the-art methods we found (decision trees and random forests) and 2-3 times slower for one in-memory dataset. Yet, this fact motivates for further research in accuracy improvement and in IDBML with SQL code generation for big data and larger-than-memory datasets.
Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle
Sep 11, 2019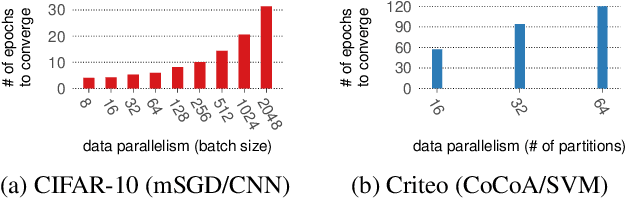
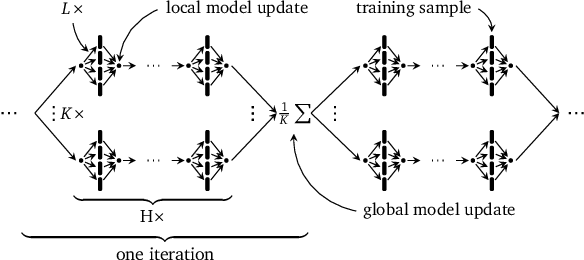
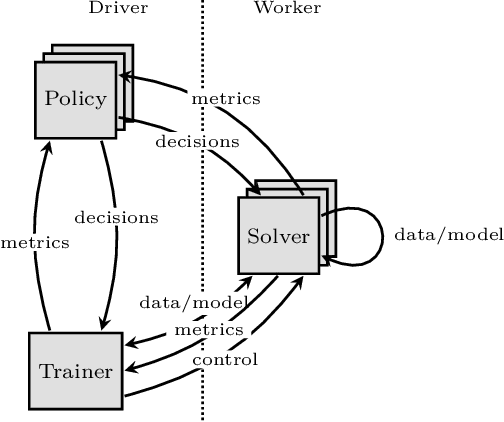
Distributed machine learning training is one of the most common and important workloads running on data centers today, but it is rarely executed alone. Instead, to reduce costs, computing resources are consolidated and shared by different applications. In this scenario, elasticity and proper load balancing are vital to maximize efficiency, fairness, and utilization. Currently, most distributed training frameworks do not support the aforementioned properties. A few exceptions that do support elasticity, imitate generic distributed frameworks and use micro-tasks. In this paper we illustrate that micro-tasks are problematic for machine learning applications, because they require a high degree of parallelism which hinders the convergence of distributed training at a pure algorithmic level (i.e., ignoring overheads and scalability limitations). To address this, we propose Chicle, a new elastic distributed training framework which exploits the nature of machine learning algorithms to implement elasticity and load balancing without micro-tasks. We use Chicle to train deep neural network as well as generalized linear models, and show that Chicle achieves performance competitive with state of the art rigid frameworks, while efficiently enabling elastic execution and dynamic load balancing.
Elastic CoCoA: Scaling In to Improve Convergence
Nov 06, 2018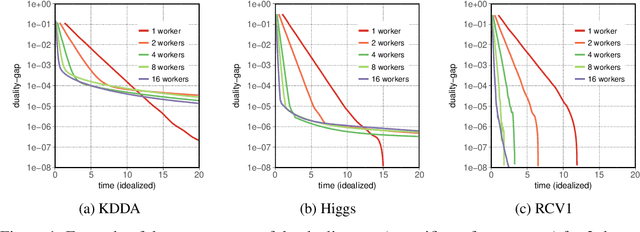
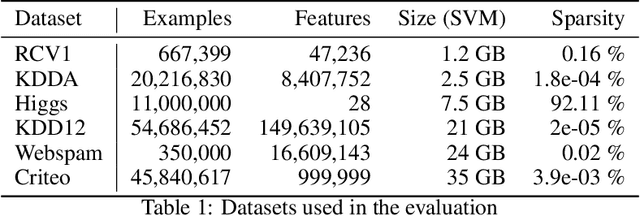
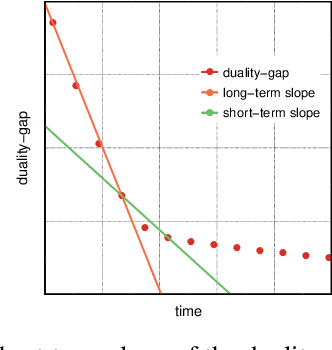

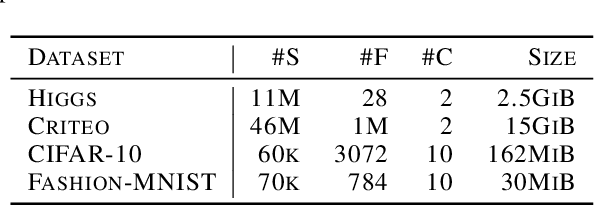
In this paper we experimentally analyze the convergence behavior of CoCoA and show, that the number of workers required to achieve the highest convergence rate at any point in time, changes over the course of the training. Based on this observation, we build Chicle, an elastic framework that dynamically adjusts the number of workers based on feedback from the training algorithm, in order to select the number of workers that results in the highest convergence rate. In our evaluation of 6 datasets, we show that Chicle is able to accelerate the time-to-accuracy by a factor of up to 5.96x compared to the best static setting, while being robust enough to find an optimal or near-optimal setting automatically in most cases.