 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Women's Health Benchmark for Large Language Models
Dec 18, 2025As large language models (LLMs) become primary sources of health information for millions, their accuracy in women's health remains critically unexamined. We introduce the Women's Health Benchmark (WHB), the first benchmark evaluating LLM performance specifically in women's health. Our benchmark comprises 96 rigorously validated model stumps covering five medical specialties (obstetrics and gynecology, emergency medicine, primary care, oncology, and neurology), three query types (patient query, clinician query, and evidence/policy query), and eight error types (dosage/medication errors, missing critical information, outdated guidelines/treatment recommendations, incorrect treatment advice, incorrect factual information, missing/incorrect differential diagnosis, missed urgency, and inappropriate recommendations). We evaluated 13 state-of-the-art LLMs and revealed alarming gaps: current models show approximately 60\% failure rates on the women's health benchmark, with performance varying dramatically across specialties and error types. Notably, models universally struggle with "missed urgency" indicators, while newer models like GPT-5 show significant improvements in avoiding inappropriate recommendations. Our findings underscore that AI chatbots are not yet fully able of providing reliable advice in women's health.
Efficient and Accurate In-Database Machine Learning with SQL Code Generation in Python
Apr 07, 2021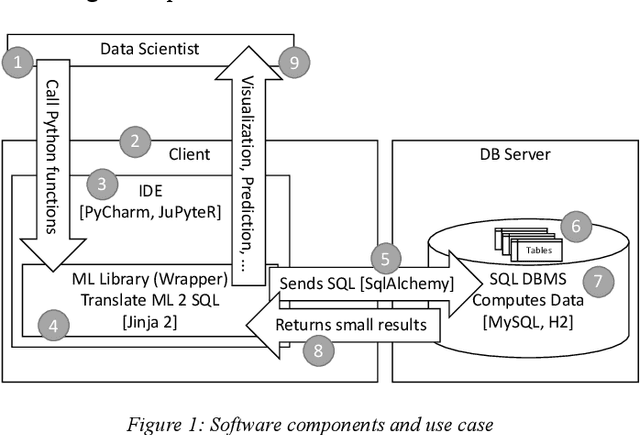
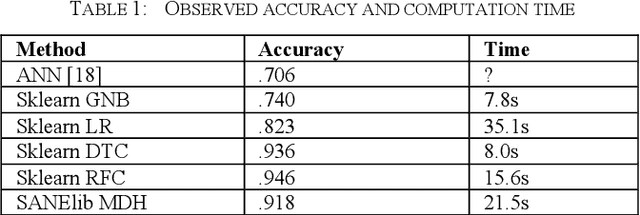


Following an analysis of the advantages of SQL-based Machine Learning (ML) and a short literature survey of the field, we describe a novel method for In-Database Machine Learning (IDBML). We contribute a process for SQL-code generation in Python using template macros in Jinja2 as well as the prototype implementation of the process. We describe our implementation of the process to compute multidimensional histogram (MDH) probability estimation in SQL. For this, we contribute and implement a novel discretization method called equal quantized rank (EQR) variable-width binning. Based on this, we provide data gathered in a benchmarking experiment for the quantitative empirical evaluation of our method and system using the Covertype dataset. We measured accuracy and computation time. Our multidimensional probability estimation was significantly more accurate than Naive Bayes, which assumes independent one-dimensional probabilities and/or densities. Also, our method was significantly more accurate and faster than logistic regression. However, our method was 2-3% less accurate than the best current state-of-the-art methods we found (decision trees and random forests) and 2-3 times slower for one in-memory dataset. Yet, this fact motivates for further research in accuracy improvement and in IDBML with SQL code generation for big data and larger-than-memory datasets.