 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Lokahi Prototype: Toward the automatic Extraction of Entity Relationship Models from Text
Paper and Code
Jan 14, 2022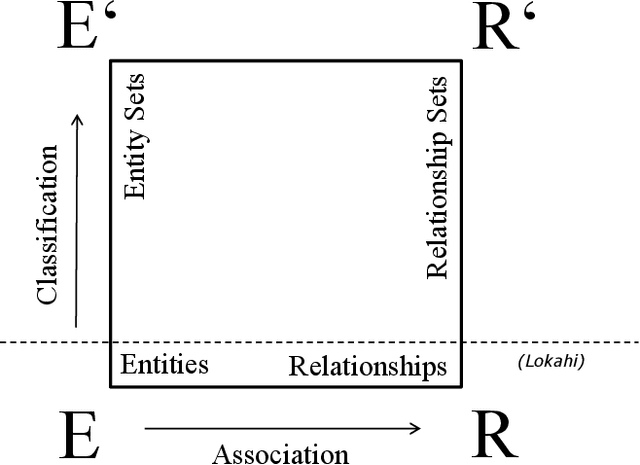
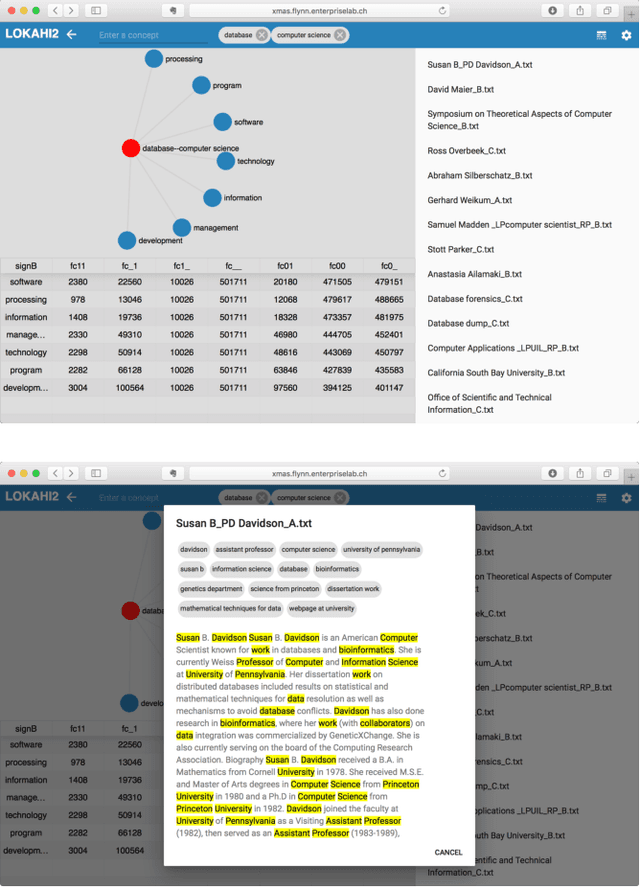
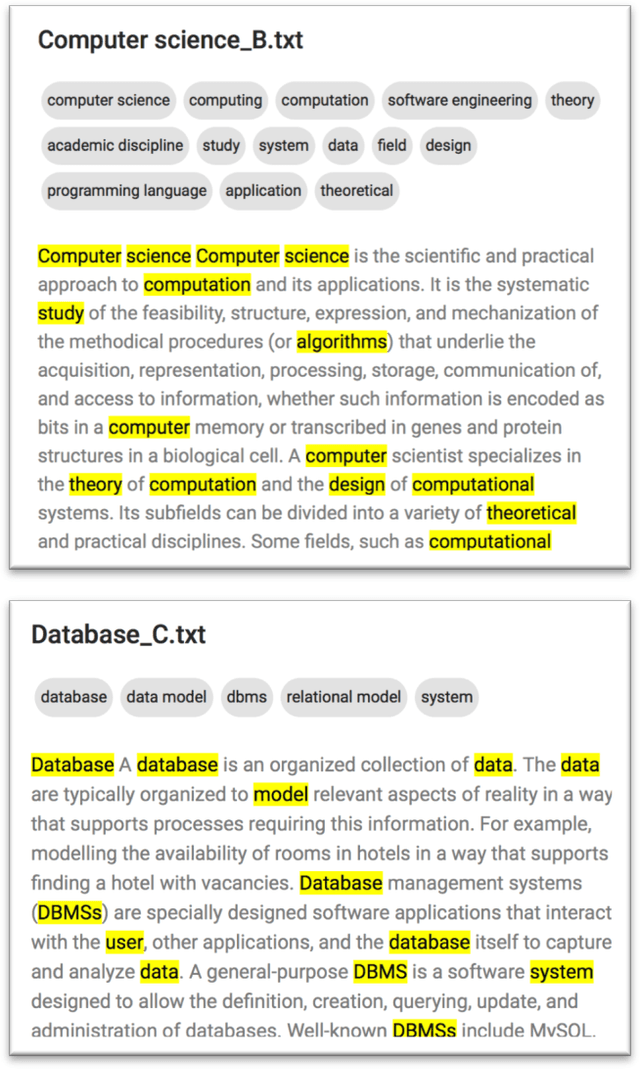
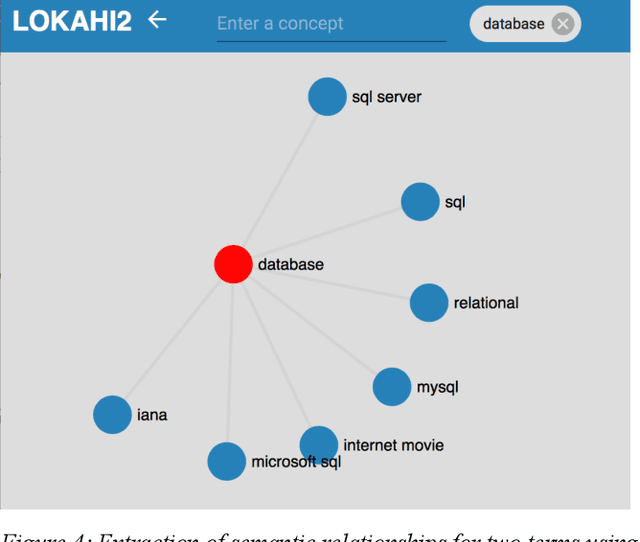
Entity relationship extraction envisions the automatic generation of semantic data models from collections of text, by automatic recognition of entities, by association of entities to form relationships, and by classifying these instances to assign them to entity sets (or classes) and relationship sets (or associations). As a first step in this direction, the Lokahi prototype can extract entities based on the TF*IDF measure, and generate semantic relationships based on document-level co-occurrence statistics, for example with likelihood ratios and pointwise mutual information. This paper presents results of an explorative, prototypical, qualitative and synthetic research, summarizes insights from two research projects and, based on this, indicates an outline for further research in the field of entity relationship extraction from text.