 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKurTail : Kurtosis-based LLM Quantization
Mar 03, 2025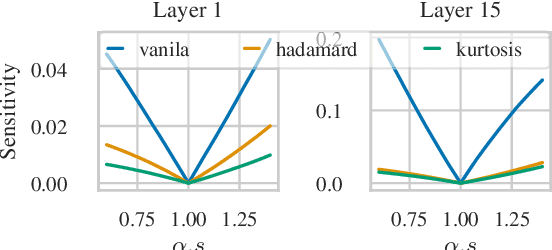
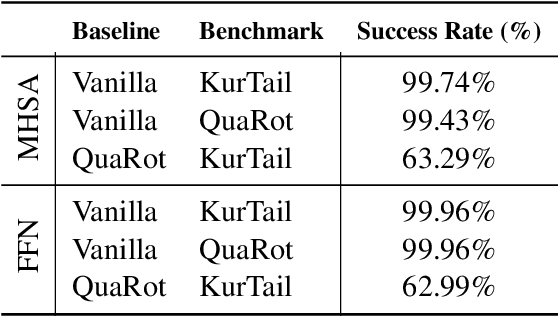
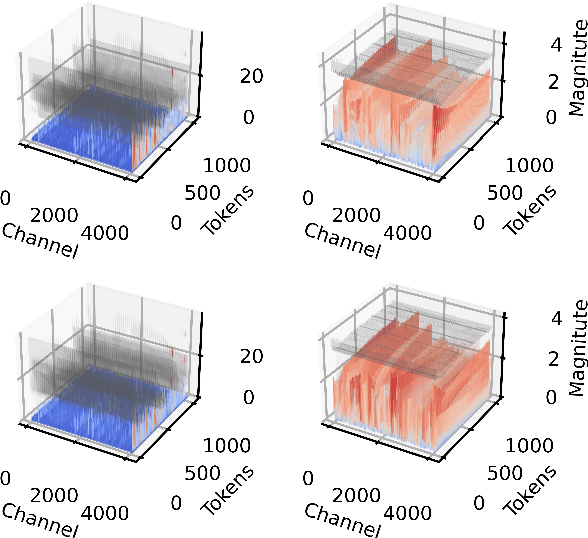
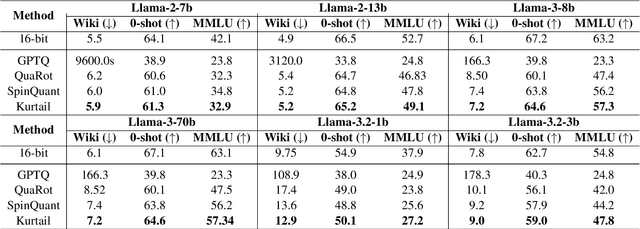
One of the challenges of quantizing a large language model (LLM) is the presence of outliers. Outliers often make uniform quantization schemes less effective, particularly in extreme cases such as 4-bit quantization. We introduce KurTail, a new post-training quantization (PTQ) scheme that leverages Kurtosis-based rotation to mitigate outliers in the activations of LLMs. Our method optimizes Kurtosis as a measure of tailedness. This approach enables the quantization of weights, activations, and the KV cache in 4 bits. We utilize layer-wise optimization, ensuring memory efficiency. KurTail outperforms existing quantization methods, offering a 13.3\% boost in MMLU accuracy and a 15.5\% drop in Wiki perplexity compared to QuaRot. It also outperforms SpinQuant with a 2.6\% MMLU gain and reduces perplexity by 2.9\%, all while reducing the training cost. For comparison, learning the rotation using SpinQuant for Llama3-70B requires at least four NVIDIA H100 80GB GPUs, whereas our method requires only a single GPU, making it a more accessible solution for consumer GPU.
EfQAT: An Efficient Framework for Quantization-Aware Training
Nov 17, 2024



Quantization-aware training (QAT) schemes have been shown to achieve near-full precision accuracy. They accomplish this by training a quantized model for multiple epochs. This is computationally expensive, mainly because of the full precision backward pass. On the other hand, post-training quantization (PTQ) schemes do not involve training and are therefore computationally cheap, but they usually result in a significant accuracy drop. We address these challenges by proposing EfQAT, which generalizes both schemes by optimizing only a subset of the parameters of a quantized model. EfQAT starts by applying a PTQ scheme to a pre-trained model and only updates the most critical network parameters while freezing the rest, accelerating the backward pass. We demonstrate the effectiveness of EfQAT on various CNNs and Transformer-based models using different GPUs. Specifically, we show that EfQAT is significantly more accurate than PTQ with little extra compute. Furthermore, EfQAT can accelerate the QAT backward pass between 1.44-1.64x while retaining most accuracy.
A Fully-Integrated 5mW, 0.8Gbps Energy-Efficient Chip-to-Chip Data Link for Ultra-Low-Power IoT End-Nodes in 65-nm CMOS
Sep 05, 2021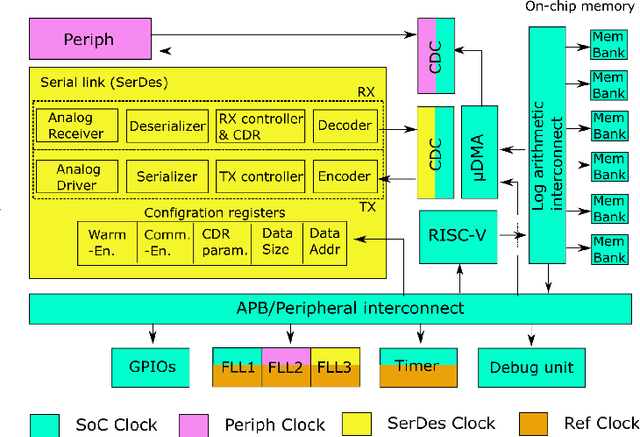


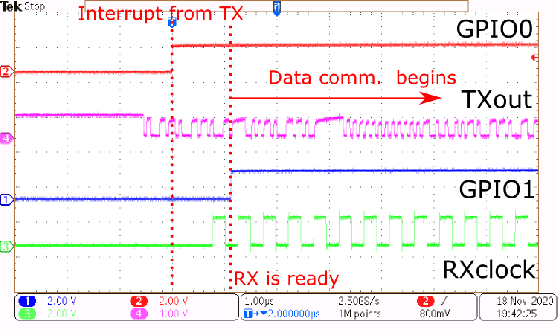
The increasing complexity of Internet-of-Things (IoT) applications and near-sensor processing algorithms is pushing the computational power of low-power, battery-operated end-node systems. This trend also reveals growing demands for high-speed and energy-efficient inter-chip communications to manage the increasing amount of data coming from off-chip sensors and memories. While traditional micro-controller interfaces such as SPIs cannot cope with tight energy and large bandwidth requirements, low-voltage swing transceivers can tackle this challenge thanks to their capability to achieve several Gbps of the communication speed at milliwatt power levels. However, recent research on high-speed serial links focused on high-performance systems, with a power consumption significantly larger than the one of low-power IoT end-nodes, or on stand-alone designs not integrated at a system level. This paper presents a low-swing transceiver for the energy-efficient and low power chip-to-chip communication fully integrated within an IoT end-node System-on-Chip, fabricated in CMOS 65nm technology. The transceiver can be easily controlled via a software interface; thus, we can consider realistic scenarios for the data communication, which cannot be assessed in stand-alone prototypes. Chip measurements show that the transceiver achieves 8.46x higher energy efficiency at 15.9x higher performance than a traditional microcontroller interface such as a single-SPI.
Compiling Neural Networks for a Computational Memory Accelerator
Mar 05, 2020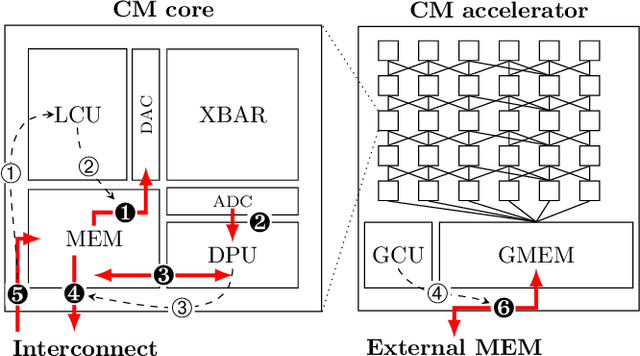

Computational memory (CM) is a promising approach for accelerating inference on neural networks (NN) by using enhanced memories that, in addition to storing data, allow computations on them. One of the main challenges of this approach is defining a hardware/software interface that allows a compiler to map NN models for efficient execution on the underlying CM accelerator. This is a non-trivial task because efficiency dictates that the CM accelerator is explicitly programmed as a dataflow engine where the execution of the different NN layers form a pipeline. In this paper, we present our work towards a software stack for executing ML models on such a multi-core CM accelerator. We describe an architecture for the hardware and software, and focus on the problem of implementing the appropriate control logic so that data dependencies are respected. We propose a solution to the latter that is based on polyhedral compilation.
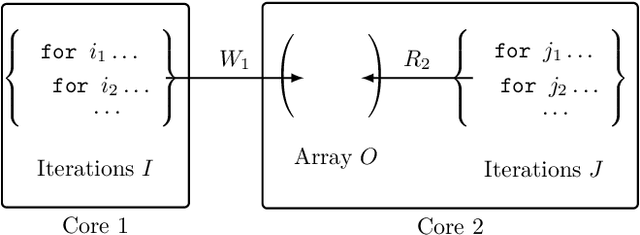
5 Parallel Prism: A topology for pipelined implementations of convolutional neural networks using computational memory
Jun 08, 2019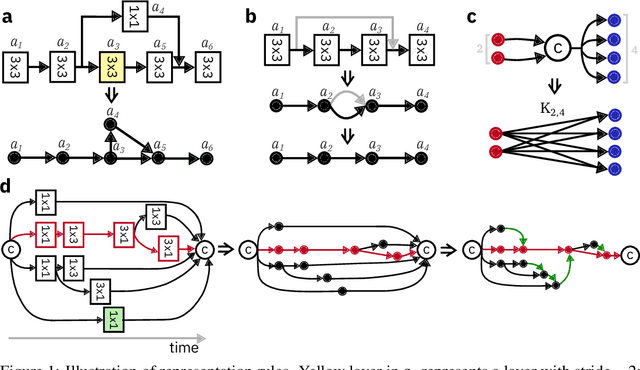
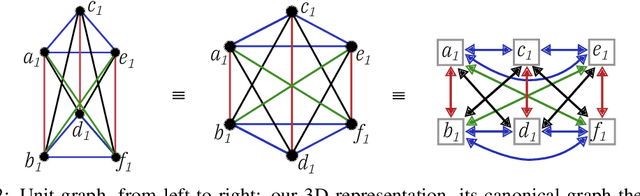
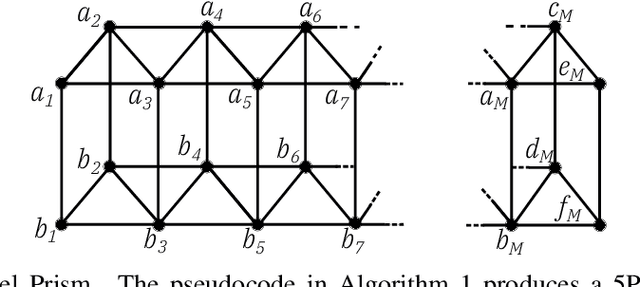
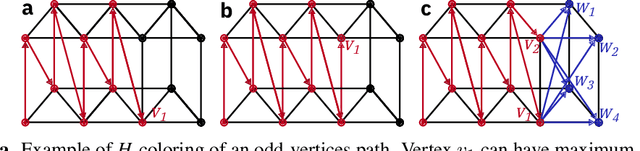
In-memory computing is an emerging computing paradigm that could enable deeplearning inference at significantly higher energy efficiency and reduced latency. The essential idea is to map the synaptic weights corresponding to each layer to one or more computational memory (CM) cores. During inference, these cores perform the associated matrix-vector multiply operations in place with O(1) time complexity, thus obviating the need to move the synaptic weights to an additional processing unit. Moreover, this architecture could enable the execution of these networks in a highly pipelined fashion. However, a key challenge is to design an efficient communication fabric for the CM cores. Here, we present one such communication fabric based on a graph topology that is well suited for the widely successful convolutional neural networks (CNNs). We show that this communication fabric facilitates the pipelined execution of all state of-the-art CNNs by proving the existence of a homomorphism between one graph representation of these networks and the proposed graph topology. We then present a quantitative comparison with established communication topologies and show that our proposed topology achieves the lowest bandwidth requirements per communication channel. Finally, we present a concrete example of mapping ResNet-32 onto an array of CM cores.