 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe-NEureka: a Hybrid Modular Redundant DNN Accelerator for On-board Satellite AI Processing
Feb 04, 2026Low Earth Orbit (LEO) constellations are revolutionizing the space sector, with on-board Artificial Intelligence (AI) becoming pivotal for next-generation satellites. AI acceleration is essential for safety-critical functions such as autonomous Guidance, Navigation, and Control (GNC), where errors cannot be tolerated, and performance-critical processing of high-bandwidth sensor data, where occasional errors are tolerable. Consequently, AI accelerators for satellites must combine robust protection against radiation-induced faults with high throughput. This paper presents Safe-NEureka, a Hybrid Modular Redundant Deep Neural Network (DNN) accelerator for heterogeneous RISC-V systems. It operates in two modes: a redundancy mode utilizing Dual Modular Redundancy (DMR) with hardware-based recovery, and a performance mode repurposing redundant datapaths to maximize parallel throughput. Furthermore, its memory interface is protected by Error Correction Codes (ECCs), and the controller by Triple Modular Redundancy (TMR). Implementation in GlobalFoundries 12nm technology shows a 96 reduction in faulty executions in redundancy mode, with a manageable 15 area overhead. In performance mode, the architecture achieves near-baseline speeds on 3x3 dense convolutions with a 5 throughput and 11 efficiency reduction, compared to 48 and 53 in redundancy mode. This flexibility ensures high overheads are limited to critical tasks, establishing Safe-NEureka as a versatile solution for space applications.
Parallelization is All System Identification Needs: End-to-end Vibration Diagnostics on a multi-core RISC-V edge device
Apr 07, 2025The early detection of structural malfunctions requires the installation of real-time monitoring systems ensuring continuous access to the damage-sensitive information; nevertheless, it can generate bottlenecks in terms of bandwidth and storage. Deploying data reduction techniques at the edge is recognized as a proficient solution to reduce the system's network traffic. However, the most effective solutions currently employed for the purpose are based on memory and power-hungry algorithms, making their embedding on resource-constrained devices very challenging; this is the case of vibration data reduction based on System Identification models. This paper presents PARSY-VDD, a fully optimized PArallel end-to-end software framework based on SYstem identification for Vibration-based Damage Detection, as a suitable solution to perform damage detection at the edge in a time and energy-efficient manner, avoiding streaming raw data to the cloud. We evaluate the damage detection capabilities of PARSY-VDD with two benchmarks: a bridge and a wind turbine blade, showcasing the robustness of the end-to-end approach. Then, we deploy PARSY-VDD on both commercial single-core and a specific multi-core edge device. We introduce an architecture-agnostic algorithmic optimization for SysId, improving the execution by 90x and reducing the consumption by 85x compared with the state-of-the-art SysId implementation on GAP9. Results show that by utilizing the unique parallel computing capabilities of GAP9, the execution time is 751{\mu}s with the high-performance multi-core solution operating at 370MHz and 0.8V, while the energy consumption is 37{\mu}J with the low-power solution operating at 240MHz and 0.65V. Compared with other single-core implementations based on STM32 microcontrollers, the GAP9 high-performance configuration is 76x faster, while the low-power configuration is 360x more energy efficient.
Open-Source Heterogeneous SoCs for AI: The PULP Platform Experience
Dec 29, 2024



Since 2013, the PULP (Parallel Ultra-Low Power) Platform project has been one of the most active and successful initiatives in designing research IPs and releasing them as open-source. Its portfolio now ranges from processor cores to network-on-chips, peripherals, SoC templates, and full hardware accelerators. In this article, we focus on the PULP experience designing heterogeneous AI acceleration SoCs - an endeavour encompassing SoC architecture definition; development, verification, and integration of acceleration IPs; front- and back-end VLSI design; testing; development of AI deployment software.
Unleashing OpenTitan's Potential: a Silicon-Ready Embedded Secure Element for Root of Trust and Cryptographic Offloading
Jun 17, 2024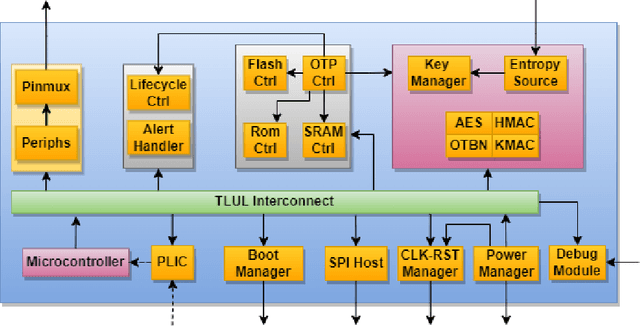

The rapid advancement and exploration of open-hardware RISC-V platforms are driving significant changes in sectors like autonomous vehicles, smart-city infrastructure, and medical devices. OpenTitan stands out as a groundbreaking open-source RISC-V design with a comprehensive security toolkit as a standalone system-on-chip (SoC). OpenTitan includes Earl Grey, a fully implemented and silicon-proven SoC, and Darjeeling, announced but not yet fully implemented. Earl Grey targets standalone SoC implementations, while Darjeeling is for integrable implementations. The literature lacks a silicon-ready embedded implementation of an open-source Root of Trust, despite lowRISC's efforts on Darjeeling. We address the limitations of existing implementations by optimizing data transfer latency between memory and cryptographic accelerators to prevent under-utilization and ensure efficient task acceleration. Our contributions include a comprehensive methodology for integrating custom extensions and IPs into the Earl Grey architecture, architectural enhancements for system-level integration, support for varied boot modes, and improved data movement across the platform. These advancements facilitate deploying OpenTitan in broader SoCs, even without specific technology-dependent IPs, providing a deployment-ready research vehicle for the community. We integrated the extended Earl Grey architecture into a reference architecture in a 22nm FDX technology node, benchmarking the enhanced architecture's performance. The results show significant improvements in cryptographic processing speed, achieving up to 2.7x speedup for SHA-256/HMAC and 1.6x for AES accelerators compared to the baseline Earl Grey architecture.
A Heterogeneous RISC-V based SoC for Secure Nano-UAV Navigation
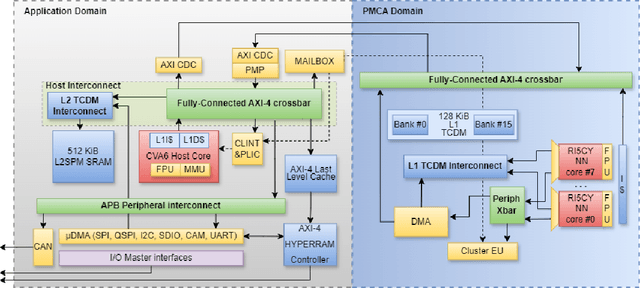
Jan 07, 2024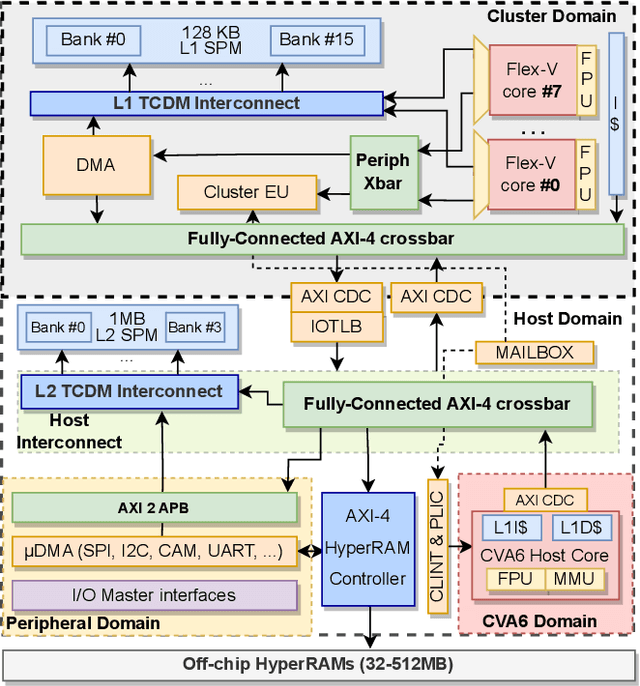
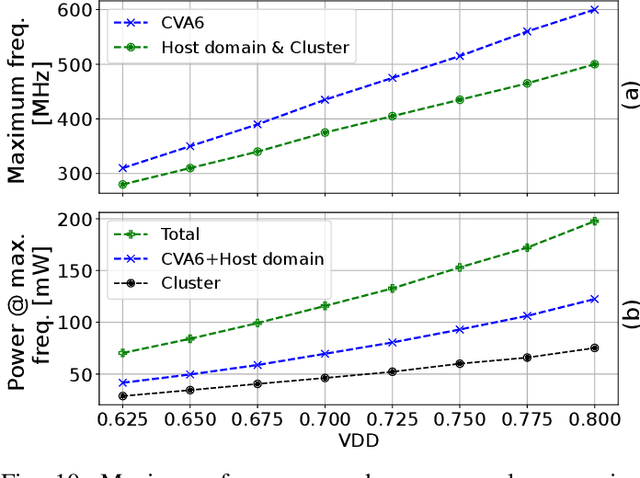
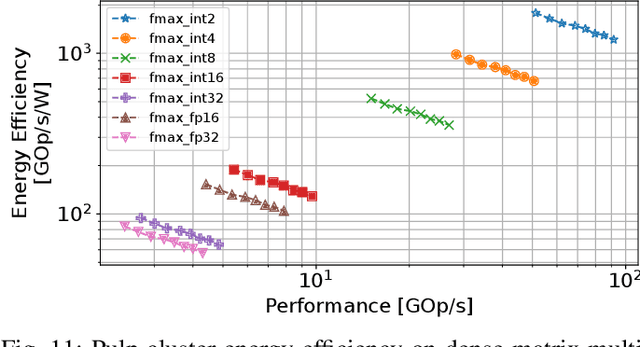
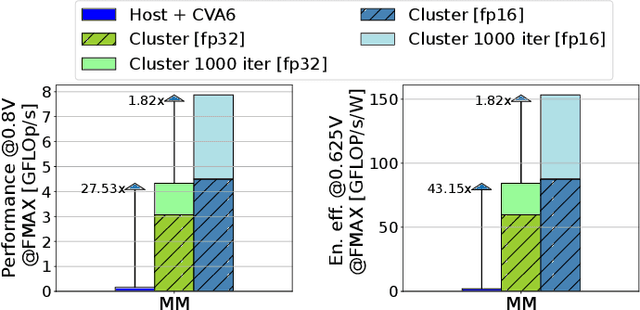
The rapid advancement of energy-efficient parallel ultra-low-power (ULP) ucontrollers units (MCUs) is enabling the development of autonomous nano-sized unmanned aerial vehicles (nano-UAVs). These sub-10cm drones represent the next generation of unobtrusive robotic helpers and ubiquitous smart sensors. However, nano-UAVs face significant power and payload constraints while requiring advanced computing capabilities akin to standard drones, including real-time Machine Learning (ML) performance and the safe co-existence of general-purpose and real-time OSs. Although some advanced parallel ULP MCUs offer the necessary ML computing capabilities within the prescribed power limits, they rely on small main memories (<1MB) and ucontroller-class CPUs with no virtualization or security features, and hence only support simple bare-metal runtimes. In this work, we present Shaheen, a 9mm2 200mW SoC implemented in 22nm FDX technology. Differently from state-of-the-art MCUs, Shaheen integrates a Linux-capable RV64 core, compliant with the v1.0 ratified Hypervisor extension and equipped with timing channel protection, along with a low-cost and low-power memory controller exposing up to 512MB of off-chip low-cost low-power HyperRAM directly to the CPU. At the same time, it integrates a fully programmable energy- and area-efficient multi-core cluster of RV32 cores optimized for general-purpose DSP as well as reduced- and mixed-precision ML. To the best of the authors' knowledge, it is the first silicon prototype of a ULP SoC coupling the RV64 and RV32 cores in a heterogeneous host+accelerator architecture fully based on the RISC-V ISA. We demonstrate the capabilities of the proposed SoC on a wide range of benchmarks relevant to nano-UAV applications. The cluster can deliver up to 90GOp/s and up to 1.8TOp/s/W on 2-bit integer kernels and up to 7.9GFLOp/s and up to 150GFLOp/s/W on 16-bit FP kernels.
Marsellus: A Heterogeneous RISC-V AI-IoT End-Node SoC with 2-to-8b DNN Acceleration and 30%-Boost Adaptive Body Biasing
May 15, 2023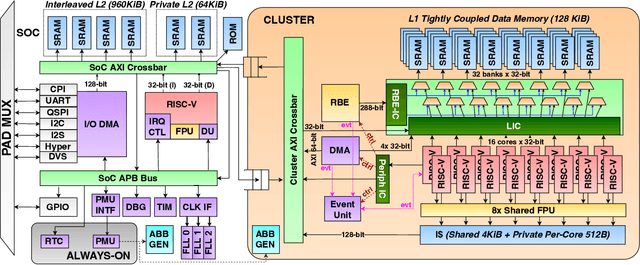
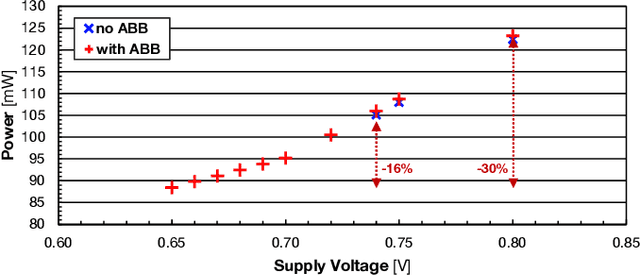
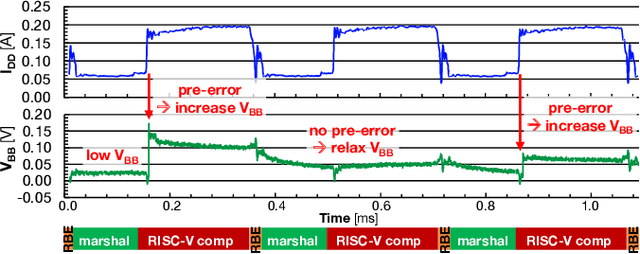
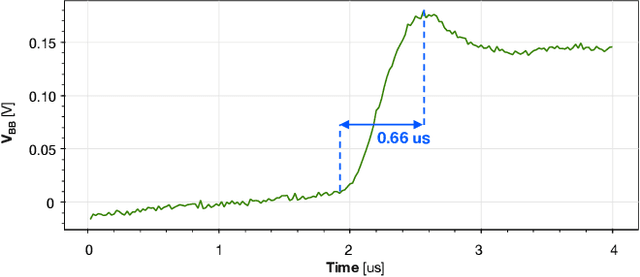
Emerging Artificial Intelligence-enabled Internet-of-Things (AI-IoT) System-on-a-Chip (SoC) for augmented reality, personalized healthcare, and nano-robotics need to run many diverse tasks within a power envelope of a few tens of mW over a wide range of operating conditions: compute-intensive but strongly quantized Deep Neural Network (DNN) inference, as well as signal processing and control requiring high-precision floating-point. We present Marsellus, an all-digital heterogeneous SoC for AI-IoT end-nodes fabricated in GlobalFoundries 22nm FDX that combines 1) a general-purpose cluster of 16 RISC-V Digital Signal Processing (DSP) cores attuned for the execution of a diverse range of workloads exploiting 4-bit and 2-bit arithmetic extensions (XpulpNN), combined with fused MAC&LOAD operations and floating-point support; 2) a 2-8bit Reconfigurable Binary Engine (RBE) to accelerate 3x3 and 1x1 (pointwise) convolutions in DNNs; 3) a set of On-Chip Monitoring (OCM) blocks connected to an Adaptive Body Biasing (ABB) generator and a hardware control loop, enabling on-the-fly adaptation of transistor threshold voltages. Marsellus achieves up to 180 Gop/s or 3.32 Top/s/W on 2-bit precision arithmetic in software, and up to 637 Gop/s or 12.4 Top/s/W on hardware-accelerated DNN layers.
RedMule: A Mixed-Precision Matrix-Matrix Operation Engine for Flexible and Energy-Efficient On-Chip Linear Algebra and TinyML Training Acceleration
Jan 10, 2023
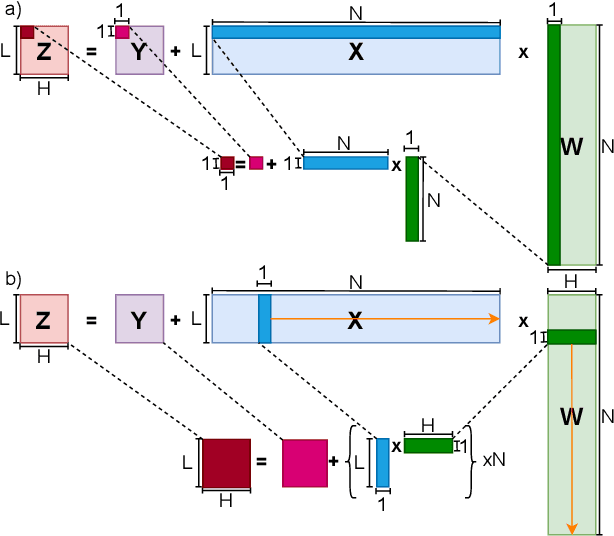
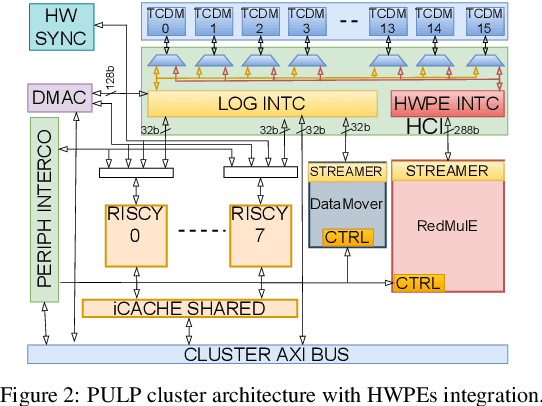
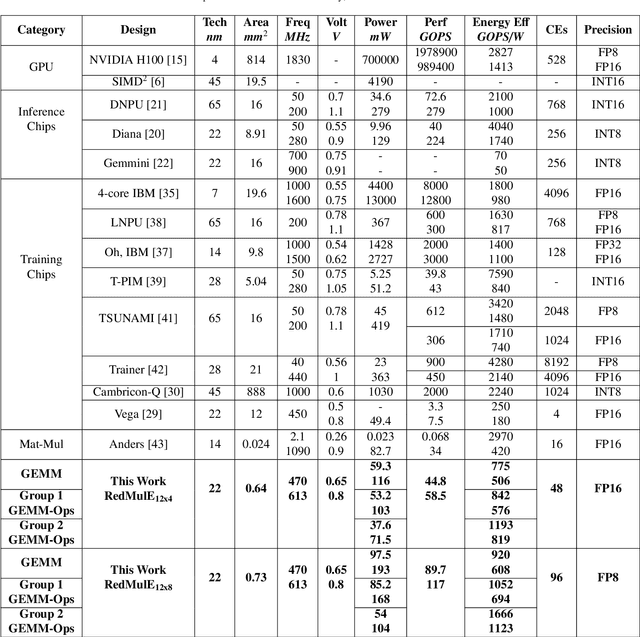
The increasing interest in TinyML, i.e., near-sensor machine learning on power budgets of a few tens of mW, is currently pushing toward enabling TinyML-class training as opposed to inference only. Current training algorithms, based on various forms of error and gradient backpropagation, rely on floating-point matrix operations to meet the precision and dynamic range requirements. So far, the energy and power cost of these operations has been considered too high for TinyML scenarios. This paper addresses the open challenge of near-sensor training on a few mW power budget and presents RedMulE - Reduced-Precision Matrix Multiplication Engine, a low-power specialized accelerator conceived for multi-precision floating-point General Matrix-Matrix Operations (GEMM-Ops) acceleration, supporting FP16, as well as hybrid FP8 formats, with {sign, exponent, mantissa}=({1,4,3}, {1,5,2}). We integrate RedMule into a Parallel Ultra-Low-Power (PULP) cluster containing eight energy-efficient RISC-V cores sharing a tightly-coupled data memory and implement the resulting system in a 22 nm technology. At its best efficiency point (@ 470 MHz, 0.65 V), the RedMulE-augmented PULP cluster achieves 755 GFLOPS/W and 920 GFLOPS/W during regular General Matrix-Matrix Multiplication (GEMM), and up to 1.19 TFLOPS/W and 1.67 TFLOPS/W when executing GEMM-Ops, respectively, for FP16 and FP8 input/output tensors. In its best performance point (@ 613 MHz, 0.8 V), RedMulE achieves up to 58.5 GFLOPS and 117 GFLOPS for FP16 and FP8, respectively, with 99.4% utilization of the array of Computing Elements and consuming less than 60 mW on average, thus enabling on-device training of deep learning models in TinyML application scenarios while retaining the flexibility to tackle other classes of common linear algebra problems efficiently.
A Heterogeneous In-Memory Computing Cluster For Flexible End-to-End Inference of Real-World Deep Neural Networks
Jan 04, 2022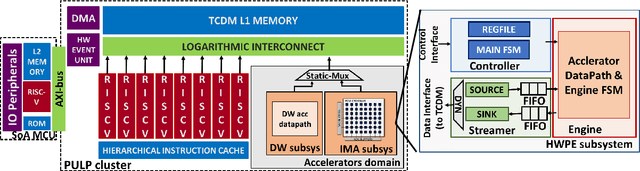
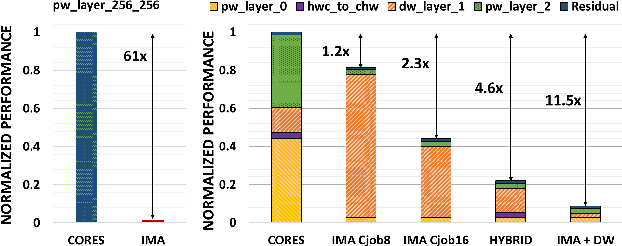
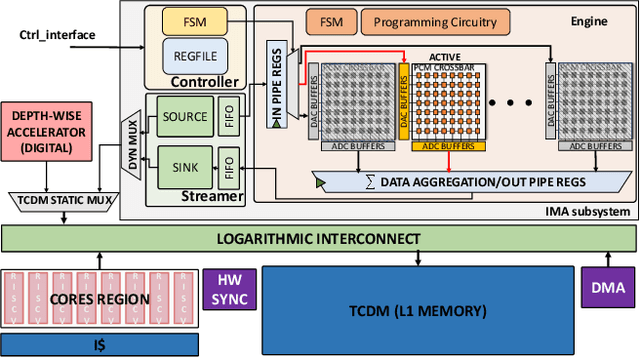
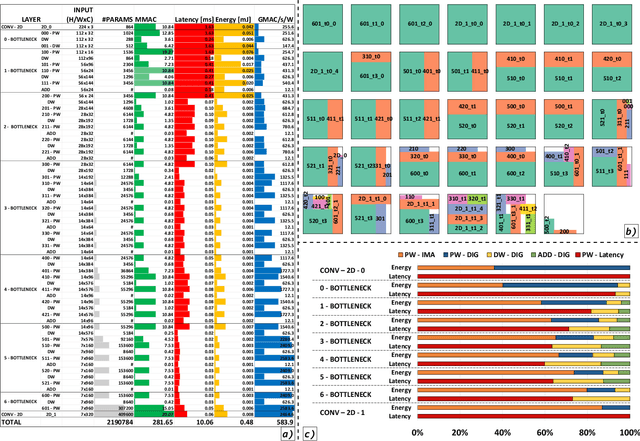
Deployment of modern TinyML tasks on small battery-constrained IoT devices requires high computational energy efficiency. Analog In-Memory Computing (IMC) using non-volatile memory (NVM) promises major efficiency improvements in deep neural network (DNN) inference and serves as on-chip memory storage for DNN weights. However, IMC's functional flexibility limitations and their impact on performance, energy, and area efficiency are not yet fully understood at the system level. To target practical end-to-end IoT applications, IMC arrays must be enclosed in heterogeneous programmable systems, introducing new system-level challenges which we aim at addressing in this work. We present a heterogeneous tightly-coupled clustered architecture integrating 8 RISC-V cores, an in-memory computing accelerator (IMA), and digital accelerators. We benchmark the system on a highly heterogeneous workload such as the Bottleneck layer from a MobileNetV2, showing 11.5x performance and 9.5x energy efficiency improvements, compared to highly optimized parallel execution on the cores. Furthermore, we explore the requirements for end-to-end inference of a full mobile-grade DNN (MobileNetV2) in terms of IMC array resources, by scaling up our heterogeneous architecture to a multi-array accelerator. Our results show that our solution, on the end-to-end inference of the MobileNetV2, is one order of magnitude better in terms of execution latency than existing programmable architectures and two orders of magnitude better than state-of-the-art heterogeneous solutions integrating in-memory computing analog cores.
Vega: A 10-Core SoC for IoT End-Nodes with DNN Acceleration and Cognitive Wake-Up From MRAM-Based State-Retentive Sleep Mode
Oct 18, 2021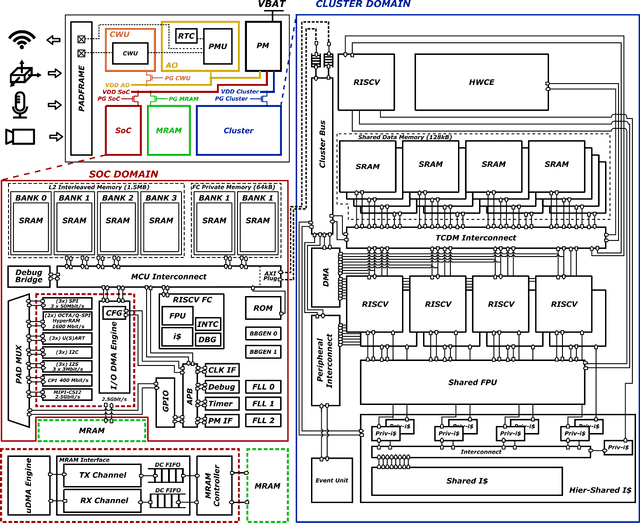
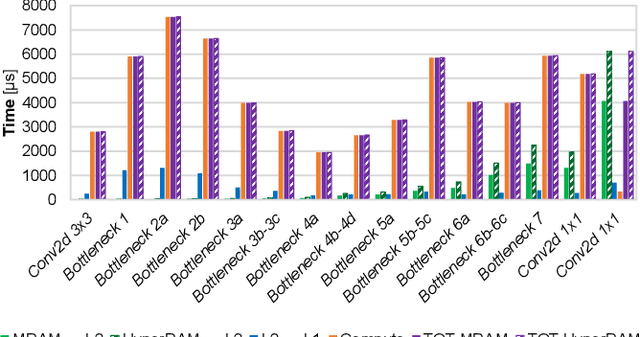
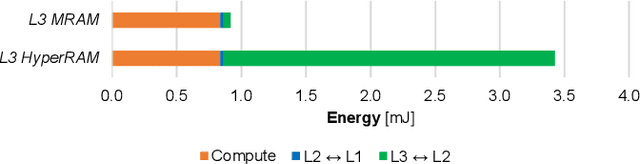
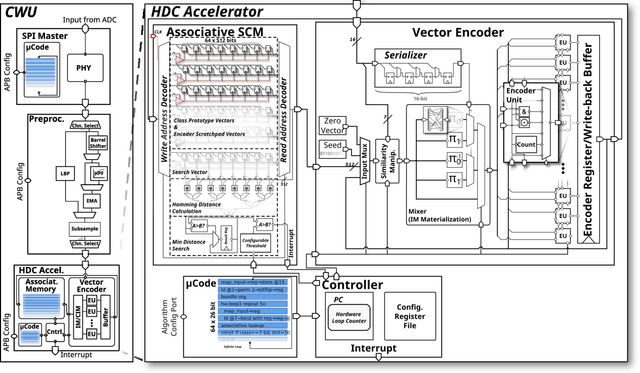
The Internet-of-Things requires end-nodes with ultra-low-power always-on capability for a long battery lifetime, as well as high performance, energy efficiency, and extreme flexibility to deal with complex and fast-evolving near-sensor analytics algorithms (NSAAs). We present Vega, an IoT end-node SoC capable of scaling from a 1.7 $\mathrm{\mu}$W fully retentive cognitive sleep mode up to 32.2 GOPS (@ 49.4 mW) peak performance on NSAAs, including mobile DNN inference, exploiting 1.6 MB of state-retentive SRAM, and 4 MB of non-volatile MRAM. To meet the performance and flexibility requirements of NSAAs, the SoC features 10 RISC-V cores: one core for SoC and IO management and a 9-cores cluster supporting multi-precision SIMD integer and floating-point computation. Vega achieves SoA-leading efficiency of 615 GOPS/W on 8-bit INT computation (boosted to 1.3TOPS/W for 8-bit DNN inference with hardware acceleration). On floating-point (FP) compuation, it achieves SoA-leading efficiency of 79 and 129 GFLOPS/W on 32- and 16-bit FP, respectively. Two programmable machine-learning (ML) accelerators boost energy efficiency in cognitive sleep and active states, respectively.
A Fully-Integrated 5mW, 0.8Gbps Energy-Efficient Chip-to-Chip Data Link for Ultra-Low-Power IoT End-Nodes in 65-nm CMOS
Sep 05, 2021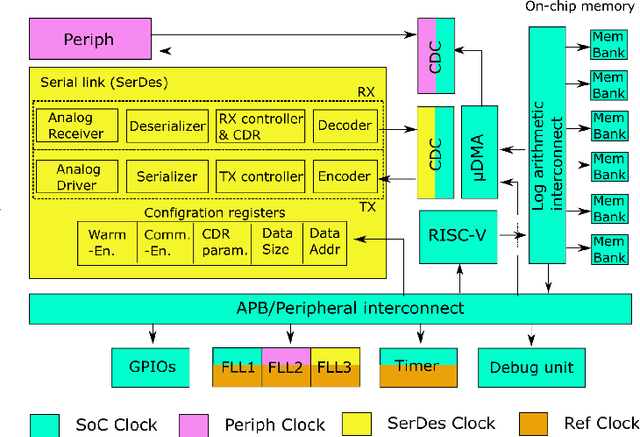


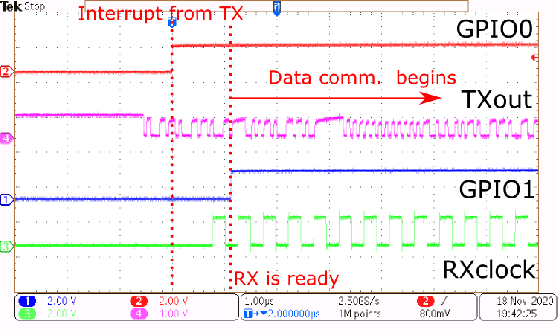
The increasing complexity of Internet-of-Things (IoT) applications and near-sensor processing algorithms is pushing the computational power of low-power, battery-operated end-node systems. This trend also reveals growing demands for high-speed and energy-efficient inter-chip communications to manage the increasing amount of data coming from off-chip sensors and memories. While traditional micro-controller interfaces such as SPIs cannot cope with tight energy and large bandwidth requirements, low-voltage swing transceivers can tackle this challenge thanks to their capability to achieve several Gbps of the communication speed at milliwatt power levels. However, recent research on high-speed serial links focused on high-performance systems, with a power consumption significantly larger than the one of low-power IoT end-nodes, or on stand-alone designs not integrated at a system level. This paper presents a low-swing transceiver for the energy-efficient and low power chip-to-chip communication fully integrated within an IoT end-node System-on-Chip, fabricated in CMOS 65nm technology. The transceiver can be easily controlled via a software interface; thus, we can consider realistic scenarios for the data communication, which cannot be assessed in stand-alone prototypes. Chip measurements show that the transceiver achieves 8.46x higher energy efficiency at 15.9x higher performance than a traditional microcontroller interface such as a single-SPI.