 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColibriUAV: An Ultra-Fast, Energy-Efficient Neuromorphic Edge Processing UAV-Platform with Event-Based and Frame-Based Cameras
May 27, 2023The interest in dynamic vision sensor (DVS)-powered unmanned aerial vehicles (UAV) is raising, especially due to the microsecond-level reaction time of the bio-inspired event sensor, which increases robustness and reduces latency of the perception tasks compared to a RGB camera. This work presents ColibriUAV, a UAV platform with both frame-based and event-based cameras interfaces for efficient perception and near-sensor processing. The proposed platform is designed around Kraken, a novel low-power RISC-V System on Chip with two hardware accelerators targeting spiking neural networks and deep ternary neural networks.Kraken is capable of efficiently processing both event data from a DVS camera and frame data from an RGB camera. A key feature of Kraken is its integrated, dedicated interface with a DVS camera. This paper benchmarks the end-to-end latency and power efficiency of the neuromorphic and event-based UAV subsystem, demonstrating state-of-the-art event data with a throughput of 7200 frames of events per second and a power consumption of 10.7 \si{\milli\watt}, which is over 6.6 times faster and a hundred times less power-consuming than the widely-used data reading approach through the USB interface. The overall sensing and processing power consumption is below 50 mW, achieving latency in the milliseconds range, making the platform suitable for low-latency autonomous nano-drones as well.
Marsellus: A Heterogeneous RISC-V AI-IoT End-Node SoC with 2-to-8b DNN Acceleration and 30%-Boost Adaptive Body Biasing
May 15, 2023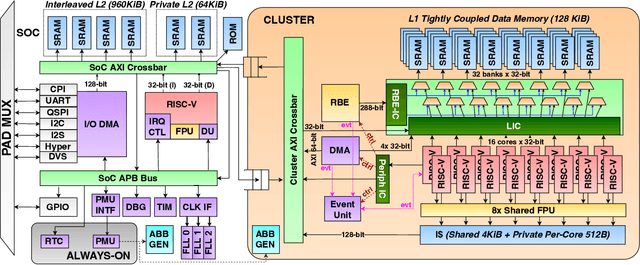
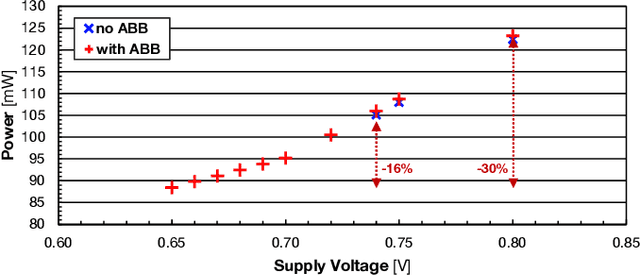
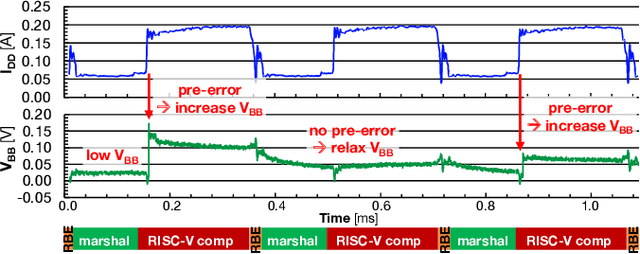
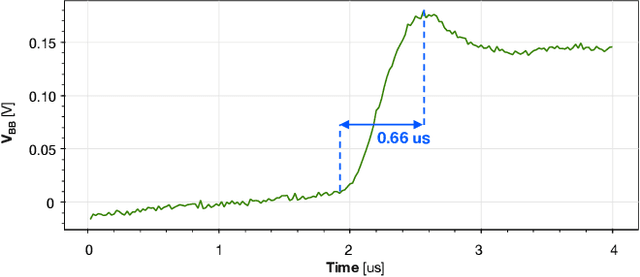
Emerging Artificial Intelligence-enabled Internet-of-Things (AI-IoT) System-on-a-Chip (SoC) for augmented reality, personalized healthcare, and nano-robotics need to run many diverse tasks within a power envelope of a few tens of mW over a wide range of operating conditions: compute-intensive but strongly quantized Deep Neural Network (DNN) inference, as well as signal processing and control requiring high-precision floating-point. We present Marsellus, an all-digital heterogeneous SoC for AI-IoT end-nodes fabricated in GlobalFoundries 22nm FDX that combines 1) a general-purpose cluster of 16 RISC-V Digital Signal Processing (DSP) cores attuned for the execution of a diverse range of workloads exploiting 4-bit and 2-bit arithmetic extensions (XpulpNN), combined with fused MAC&LOAD operations and floating-point support; 2) a 2-8bit Reconfigurable Binary Engine (RBE) to accelerate 3x3 and 1x1 (pointwise) convolutions in DNNs; 3) a set of On-Chip Monitoring (OCM) blocks connected to an Adaptive Body Biasing (ABB) generator and a hardware control loop, enabling on-the-fly adaptation of transistor threshold voltages. Marsellus achieves up to 180 Gop/s or 3.32 Top/s/W on 2-bit precision arithmetic in software, and up to 637 Gop/s or 12.4 Top/s/W on hardware-accelerated DNN layers.
An Energy-Efficient Spiking Neural Network for Finger Velocity Decoding for Implantable Brain-Machine Interface
Oct 07, 2022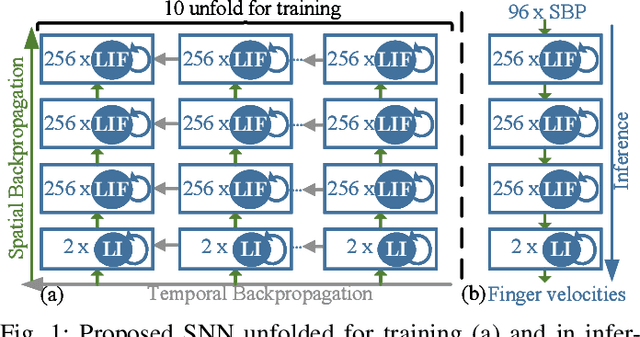
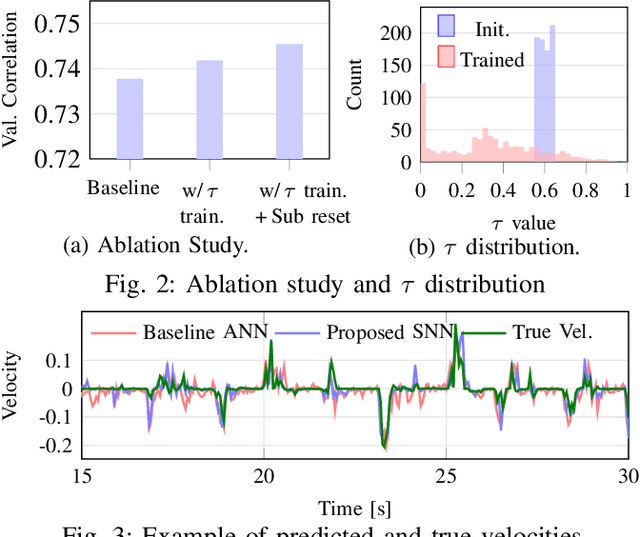
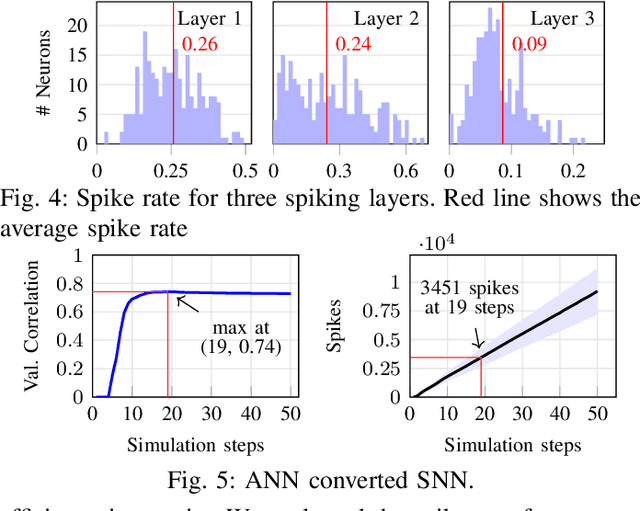
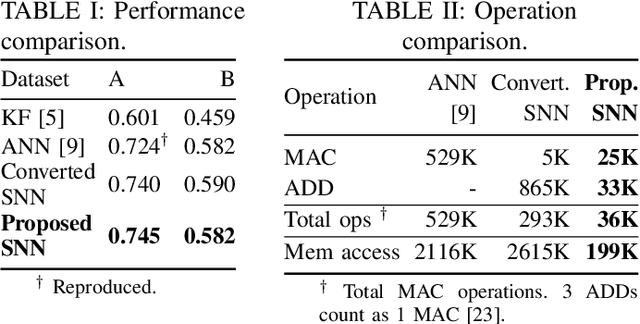
Brain-machine interfaces (BMIs) are promising for motor rehabilitation and mobility augmentation. High-accuracy and low-power algorithms are required to achieve implantable BMI systems. In this paper, we propose a novel spiking neural network (SNN) decoder for implantable BMI regression tasks. The SNN is trained with enhanced spatio-temporal backpropagation to fully leverage its ability in handling temporal problems. The proposed SNN decoder achieves the same level of correlation coefficient as the state-of-the-art ANN decoder in offline finger velocity decoding tasks, while it requires only 6.8% of the computation operations and 9.4% of the memory access.
Vega: A 10-Core SoC for IoT End-Nodes with DNN Acceleration and Cognitive Wake-Up From MRAM-Based State-Retentive Sleep Mode
Oct 18, 2021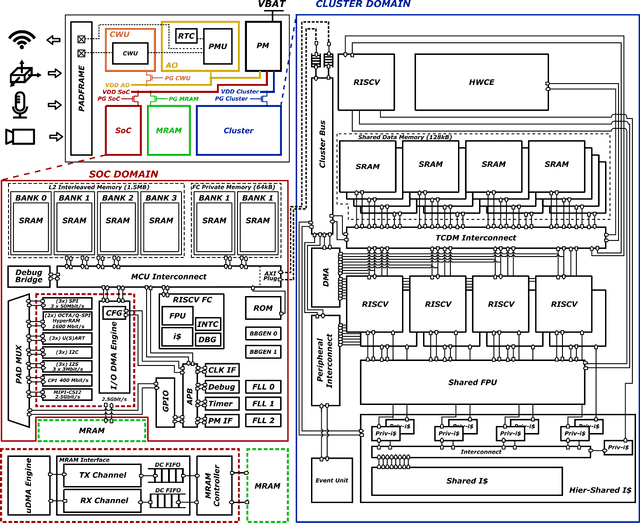
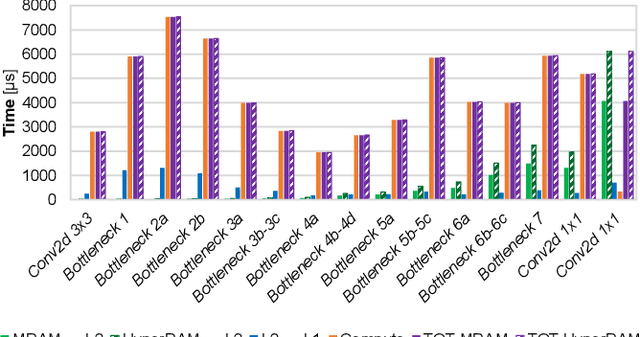
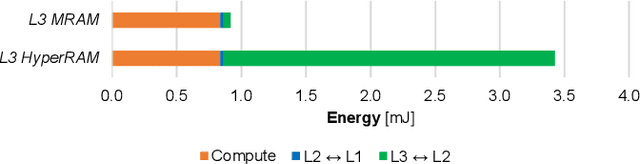
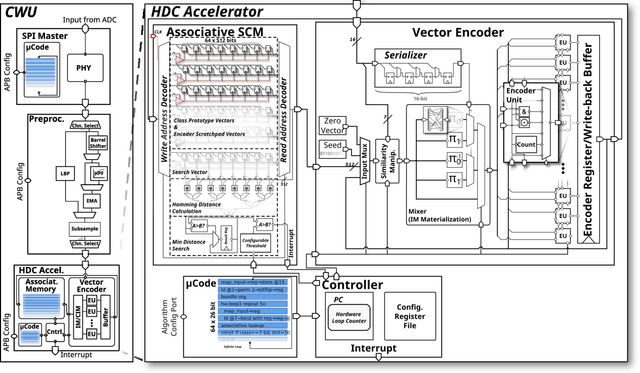
The Internet-of-Things requires end-nodes with ultra-low-power always-on capability for a long battery lifetime, as well as high performance, energy efficiency, and extreme flexibility to deal with complex and fast-evolving near-sensor analytics algorithms (NSAAs). We present Vega, an IoT end-node SoC capable of scaling from a 1.7 $\mathrm{\mu}$W fully retentive cognitive sleep mode up to 32.2 GOPS (@ 49.4 mW) peak performance on NSAAs, including mobile DNN inference, exploiting 1.6 MB of state-retentive SRAM, and 4 MB of non-volatile MRAM. To meet the performance and flexibility requirements of NSAAs, the SoC features 10 RISC-V cores: one core for SoC and IO management and a 9-cores cluster supporting multi-precision SIMD integer and floating-point computation. Vega achieves SoA-leading efficiency of 615 GOPS/W on 8-bit INT computation (boosted to 1.3TOPS/W for 8-bit DNN inference with hardware acceleration). On floating-point (FP) compuation, it achieves SoA-leading efficiency of 79 and 129 GFLOPS/W on 32- and 16-bit FP, respectively. Two programmable machine-learning (ML) accelerators boost energy efficiency in cognitive sleep and active states, respectively.
Always-On 674uW @ 4GOP/s Error Resilient Binary Neural Networks with Aggressive SRAM Voltage Scaling on a 22nm IoT End-Node
Jul 17, 2020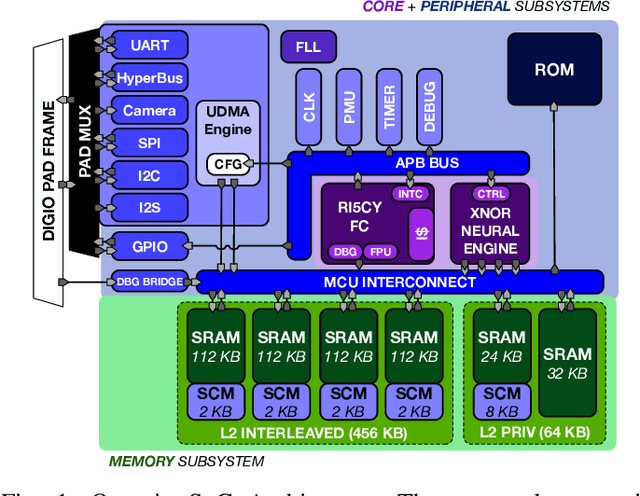
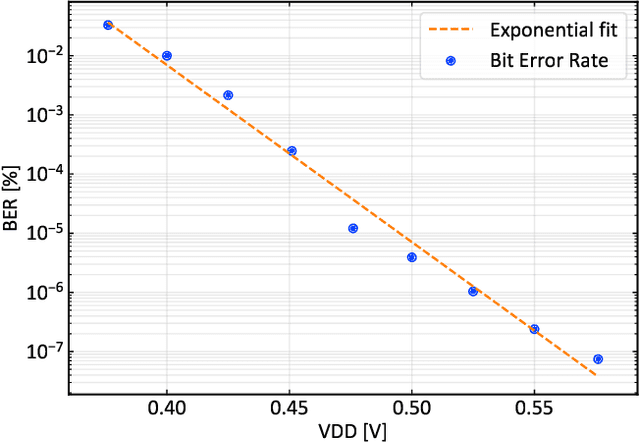
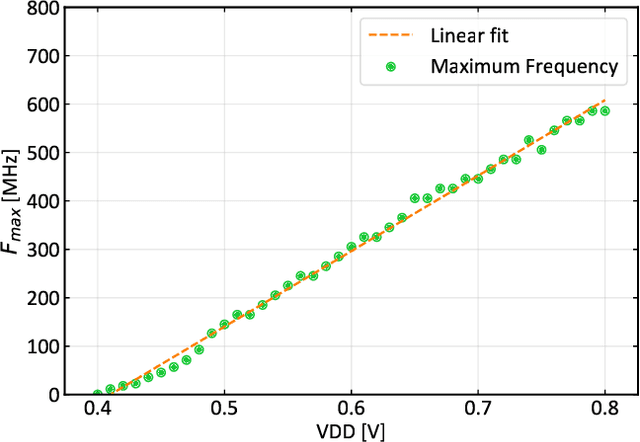
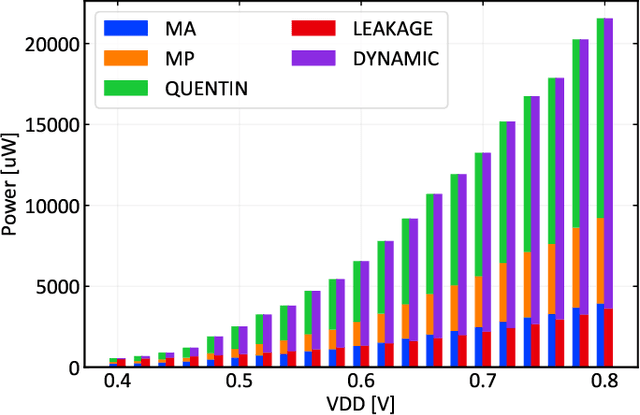
Binary Neural Networks (BNNs) have been shown to be robust to random bit-level noise, making aggressive voltage scaling attractive as a power-saving technique for both logic and SRAMs. In this work, we introduce the first fully programmable IoT end-node system-on-chip (SoC) capable of executing software-defined, hardware-accelerated BNNs at ultra-low voltage. Our SoC exploits a hybrid memory scheme where error-vulnerable SRAMs are complemented by reliable standard-cell memories to safely store critical data under aggressive voltage scaling. On a prototype in 22nm FDX technology, we demonstrate that both the logic and SRAM voltage can be dropped to 0.5Vwithout any accuracy penalty on a BNN trained for the CIFAR-10 dataset, improving energy efficiency by 2.2X w.r.t. nominal conditions. Furthermore, we show that the supply voltage can be dropped to 0.42V (50% of nominal) while keeping more than99% of the nominal accuracy (with a bit error rate ~1/1000). In this operating point, our prototype performs 4Gop/s (15.4Inference/s on the CIFAR-10 dataset) by computing up to 13binary ops per pJ, achieving 22.8 Inference/s/mW while keeping within a peak power envelope of 674uW - low enough to enable always-on operation in ultra-low power smart cameras, long-lifetime environmental sensors, and insect-sized pico-drones.