 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Efficient Wearables: An Analysis of Low-Power Microcontrollers for Biomedical Applications
Nov 14, 2024

Breakthroughs in ultra-low-power chip technology are transforming biomedical wearables, making it possible to monitor patients in real time with devices operating on mere {\mu}W. Although many studies have examined the power performance of commercial microcontrollers, it remains unclear which ones perform best across diverse application profiles and which hardware features are most crucial for minimizing energy consumption under varying computational loads. Identifying these features for typical wearable applications and understanding their effects on performance and energy efficiency are essential for optimizing deployment strategies and informing future hardware designs. In this work, we conduct an in-depth study of state-of-the-art (SoA) micro-controller units(MCUs) in terms of processing capability and energy efficiency using representative end-to-end SoA wearable applications. We systematically benchmark each platform across three primary application phases: idle, data acquisition, and processing, allowing a holistic assessment of the platform processing capability and overall energy efficiency across varying patient-monitoring application profiles. Our detailed analysis of performance and energy discrepancies across different platforms reveals key strengths and limitations of the current low-power hardware design and pinpoints the strengths and weaknesses of SoA MCUs. We conclude with actionable insights for wearable application designers and hardware engineers, aiming to inform future hardware design improvements and support optimal platform selection for energy-constrained biomedical applications.
MetaWearS: A Shortcut in Wearable Systems Lifecycle with Only a Few Shots
Aug 04, 2024


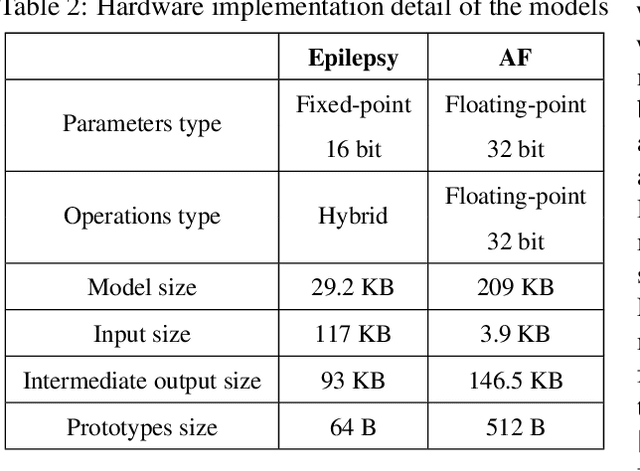
Wearable systems provide continuous health monitoring and can lead to early detection of potential health issues. However, the lifecycle of wearable systems faces several challenges. First, effective model training for new wearable devices requires substantial labeled data from various subjects collected directly by the wearable. Second, subsequent model updates require further extensive labeled data for retraining. Finally, frequent model updating on the wearable device can decrease the battery life in long-term data monitoring. Addressing these challenges, in this paper, we propose MetaWearS, a meta-learning method to reduce the amount of initial data collection required. Moreover, our approach incorporates a prototypical updating mechanism, simplifying the update process by modifying the class prototype rather than retraining the entire model. We explore the performance of MetaWearS in two case studies, namely, the detection of epileptic seizures and the detection of atrial fibrillation. We show that by fine-tuning with just a few samples, we achieve 70% and 82% AUC for the detection of epileptic seizures and the detection of atrial fibrillation, respectively. Compared to a conventional approach, our proposed method performs better with up to 45% AUC. Furthermore, updating the model with only 16 minutes of additional labeled data increases the AUC by up to 5.3%. Finally, MetaWearS reduces the energy consumption for model updates by 456x and 418x for epileptic seizure and AF detection, respectively.
BiomedBench: A benchmark suite of TinyML biomedical applications for low-power wearables
Jun 06, 2024The design of low-power wearables for the biomedical domain has received a lot of attention in recent decades, as technological advances in chip manufacturing have allowed real-time monitoring of patients using low-complexity ML within the mW range. Despite advances in application and hardware design research, the domain lacks a systematic approach to hardware evaluation. In this work, we propose BiomedBench, a new benchmark suite composed of complete end-to-end TinyML biomedical applications for real-time monitoring of patients using wearable devices. Each application presents different requirements during typical signal acquisition and processing phases, including varying computational workloads and relations between active and idle times. Furthermore, our evaluation of five state-of-the-art low-power platforms in terms of energy efficiency shows that modern platforms cannot effectively target all types of biomedical applications. BiomedBench will be released as an open-source suite to enable future improvements in the entire domain of bioengineering systems and TinyML application design.
Always-On 674uW @ 4GOP/s Error Resilient Binary Neural Networks with Aggressive SRAM Voltage Scaling on a 22nm IoT End-Node
Jul 17, 2020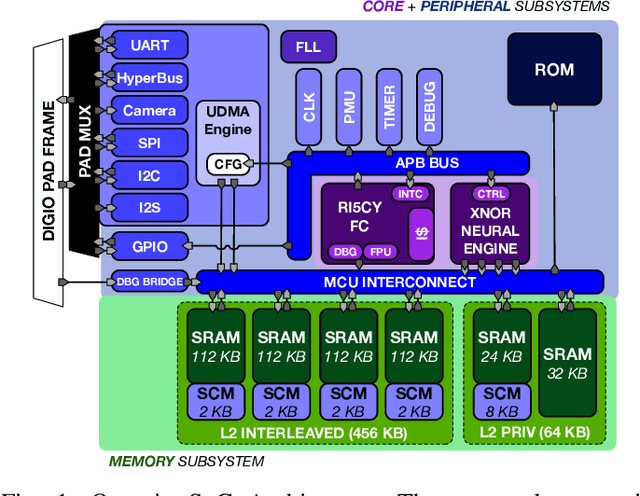
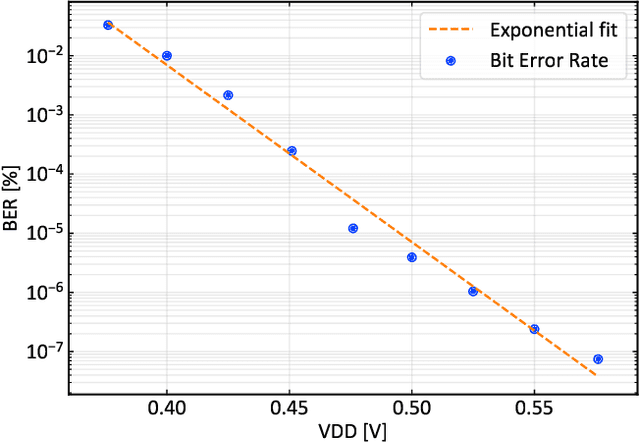
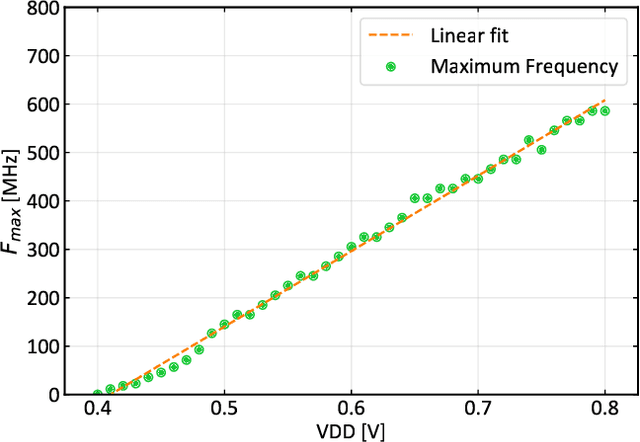
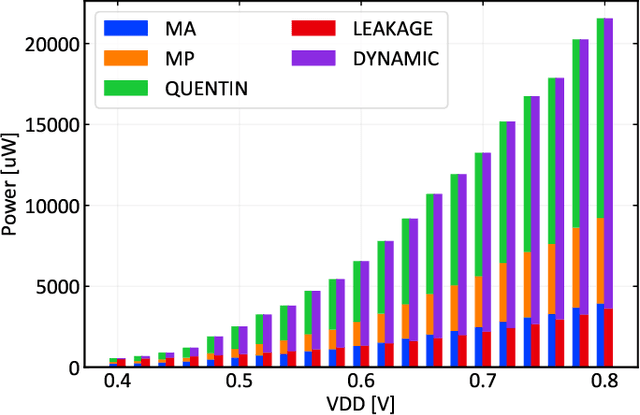
Binary Neural Networks (BNNs) have been shown to be robust to random bit-level noise, making aggressive voltage scaling attractive as a power-saving technique for both logic and SRAMs. In this work, we introduce the first fully programmable IoT end-node system-on-chip (SoC) capable of executing software-defined, hardware-accelerated BNNs at ultra-low voltage. Our SoC exploits a hybrid memory scheme where error-vulnerable SRAMs are complemented by reliable standard-cell memories to safely store critical data under aggressive voltage scaling. On a prototype in 22nm FDX technology, we demonstrate that both the logic and SRAM voltage can be dropped to 0.5Vwithout any accuracy penalty on a BNN trained for the CIFAR-10 dataset, improving energy efficiency by 2.2X w.r.t. nominal conditions. Furthermore, we show that the supply voltage can be dropped to 0.42V (50% of nominal) while keeping more than99% of the nominal accuracy (with a bit error rate ~1/1000). In this operating point, our prototype performs 4Gop/s (15.4Inference/s on the CIFAR-10 dataset) by computing up to 13binary ops per pJ, achieving 22.8 Inference/s/mW while keeping within a peak power envelope of 674uW - low enough to enable always-on operation in ultra-low power smart cameras, long-lifetime environmental sensors, and insect-sized pico-drones.
XNOR Neural Engine: a Hardware Accelerator IP for 21.6 fJ/op Binary Neural Network Inference
Jul 09, 2018
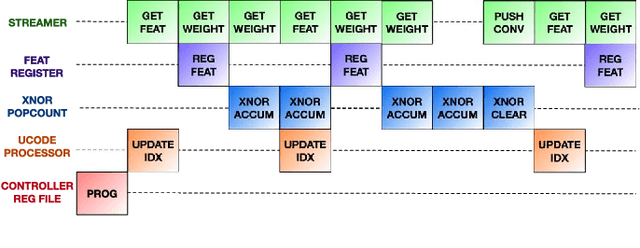
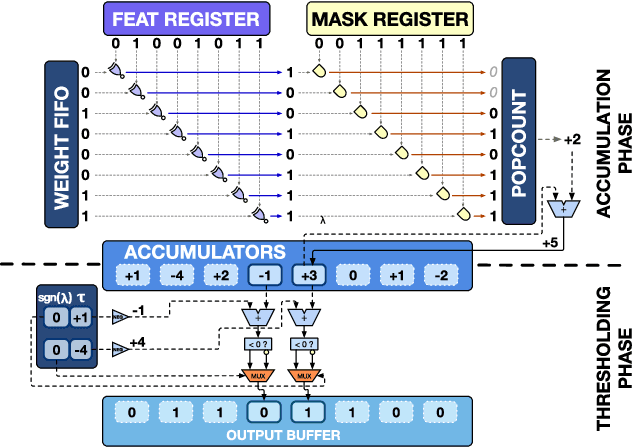
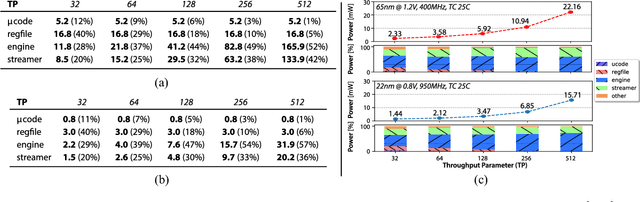
Binary Neural Networks (BNNs) are promising to deliver accuracy comparable to conventional deep neural networks at a fraction of the cost in terms of memory and energy. In this paper, we introduce the XNOR Neural Engine (XNE), a fully digital configurable hardware accelerator IP for BNNs, integrated within a microcontroller unit (MCU) equipped with an autonomous I/O subsystem and hybrid SRAM / standard cell memory. The XNE is able to fully compute convolutional and dense layers in autonomy or in cooperation with the core in the MCU to realize more complex behaviors. We show post-synthesis results in 65nm and 22nm technology for the XNE IP and post-layout results in 22nm for the full MCU indicating that this system can drop the energy cost per binary operation to 21.6fJ per operation at 0.4V, and at the same time is flexible and performant enough to execute state-of-the-art BNN topologies such as ResNet-34 in less than 2.2mJ per frame at 8.9 fps.
An IoT Endpoint System-on-Chip for Secure and Energy-Efficient Near-Sensor Analytics
Apr 23, 2017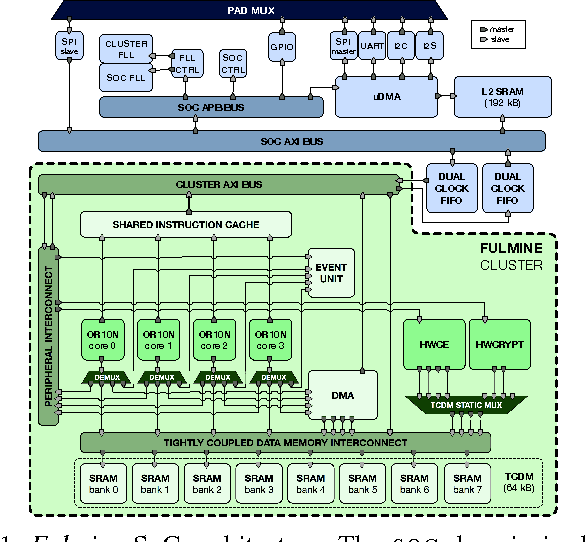
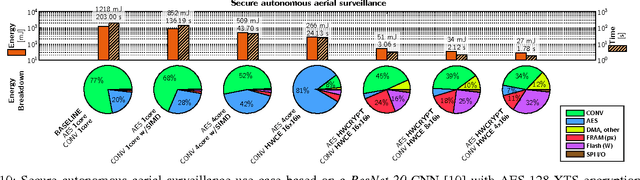
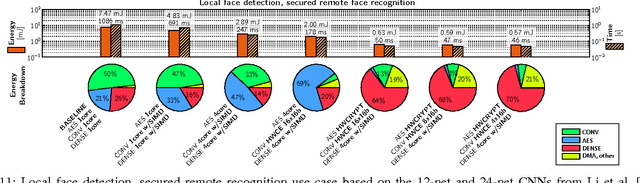
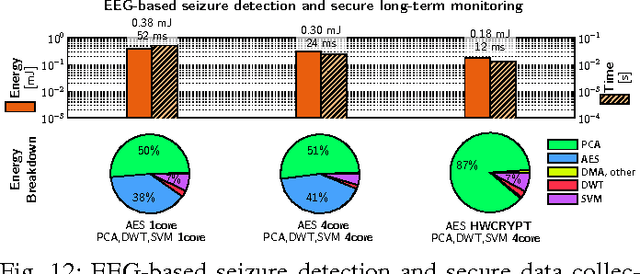
Near-sensor data analytics is a promising direction for IoT endpoints, as it minimizes energy spent on communication and reduces network load - but it also poses security concerns, as valuable data is stored or sent over the network at various stages of the analytics pipeline. Using encryption to protect sensitive data at the boundary of the on-chip analytics engine is a way to address data security issues. To cope with the combined workload of analytics and encryption in a tight power envelope, we propose Fulmine, a System-on-Chip based on a tightly-coupled multi-core cluster augmented with specialized blocks for compute-intensive data processing and encryption functions, supporting software programmability for regular computing tasks. The Fulmine SoC, fabricated in 65nm technology, consumes less than 20mW on average at 0.8V achieving an efficiency of up to 70pJ/B in encryption, 50pJ/px in convolution, or up to 25MIPS/mW in software. As a strong argument for real-life flexible application of our platform, we show experimental results for three secure analytics use cases: secure autonomous aerial surveillance with a state-of-the-art deep CNN consuming 3.16pJ per equivalent RISC op; local CNN-based face detection with secured remote recognition in 5.74pJ/op; and seizure detection with encrypted data collection from EEG within 12.7pJ/op.