 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalization on a Budget: Minimally-Labeled Continual Learning for Resource-Efficient Seizure Detection
Sep 17, 2025Objective: Epilepsy, a prevalent neurological disease, demands careful diagnosis and continuous care. Seizure detection remains challenging, as current clinical practice relies on expert analysis of electroencephalography, which is a time-consuming process and requires specialized knowledge. Addressing this challenge, this paper explores automated epileptic seizure detection using deep learning, focusing on personalized continual learning models that adapt to each patient's unique electroencephalography signal features, which evolve over time. Methods: In this context, our approach addresses the challenge of integrating new data into existing models without catastrophic forgetting, a common issue in static deep learning models. We propose EpiSMART, a continual learning framework for seizure detection that uses a size-constrained replay buffer and an informed sample selection strategy to incrementally adapt to patient-specific electroencephalography signals. By selectively retaining high-entropy and seizure-predicted samples, our method preserves critical past information while maintaining high performance with minimal memory and computational requirements. Results: Validation on the CHB-MIT dataset, shows that EpiSMART achieves a 21% improvement in the F1 score over a trained baseline without updates in all other patients. On average, EpiSMART requires only 6.46 minutes of labeled data and 6.28 updates per day, making it suitable for real-time deployment in wearable systems. Conclusion:EpiSMART enables robust and personalized seizure detection under realistic and resource-constrained conditions by effectively integrating new data into existing models without degrading past knowledge. Significance: This framework advances automated seizure detection by providing a continual learning approach that supports patient-specific adaptation and practical deployment in wearable healthcare systems.
Mathematical model of parameters relevance in adaptive level-crossing sampling for electrocardiogram signals
Jan 18, 2025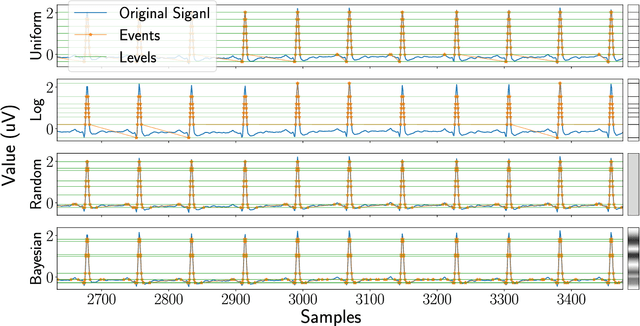

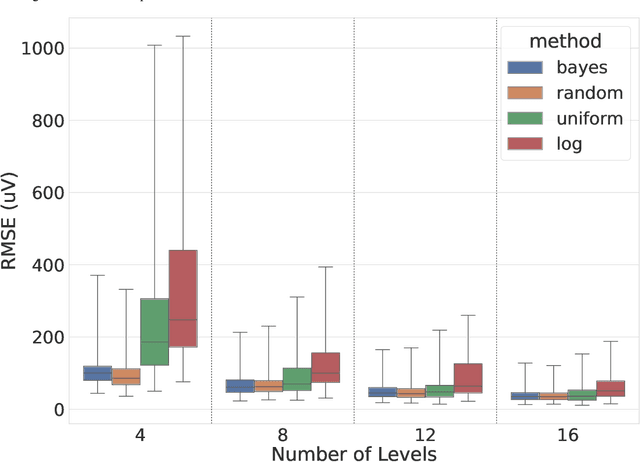

Digital acquisition of bio-signals has been mostly dominated by uniform time sampling following the Nyquist theorem. However, in recent years, new approaches have emerged, focused on sampling a signal only when certain events happen. Currently, the most prominent of these approaches is Level Crossing (LC) sampling. Conventional level crossing analog-to-digital converters (LC-ADC) are often designed to make use of statically defined and uniformly spaced levels. However, a different positioning of the levels, optimized for bio-signals monitoring, can potentially lead to better performing solutions. In this work, we compare multiple LC-level definitions, including statically defined (uniform and logarithmic) configurations and optimization-driven designs (randomized and Bayesian optimization), assessing their ability to maintain signal fidelity while minimizing the sampling rate. In this paper, we analyze the performance of these different methodologies, which is evaluated using the root mean square error (RMSE), the sampling reduction factor (SRF) -- a metric evaluating the sampling compression ratio -- , and error per event metrics to gauge the trade-offs between signal fidelity and data compression. Our findings reveal that optimization-driven LC-sampling, particularly those using Bayesian methods, achieve a lower RMSE without substantially impacting the error per event compared to static configurations, but at the cost of an increase in the sampling rate.
Systolic Arrays and Structured Pruning Co-design for Efficient Transformers in Edge Systems
Nov 15, 2024



Efficient deployment of resource-intensive transformers on edge devices necessitates cross-stack optimization. We thus study the interrelation between structured pruning and systolic acceleration, matching the size of pruned blocks with the systolic array dimensions. In this setting, computations of pruned weight blocks can be skipped, reducing run-time and energy consumption, but potentially impacting quality of service (QoS). To evaluate the trade-offs between systolic array size and sparsity opportunities, we present a novel co-design framework that integrates algorithmic optimization, system simulation, and hardware design. Targeting speech recognition using transformers as a case study, we analyze how configuration choices across the stack affect performance metrics. Results demonstrate that structured pruning on systems featuring systolic array acceleration can effectively increase performance, while maintaining high QoS levels. Up to 26% system-wide speedups due to structured pruning were measured, with only 1.4% word error rate degradation on the standard Librispeech dataset.
MetaWearS: A Shortcut in Wearable Systems Lifecycle with Only a Few Shots
Aug 04, 2024


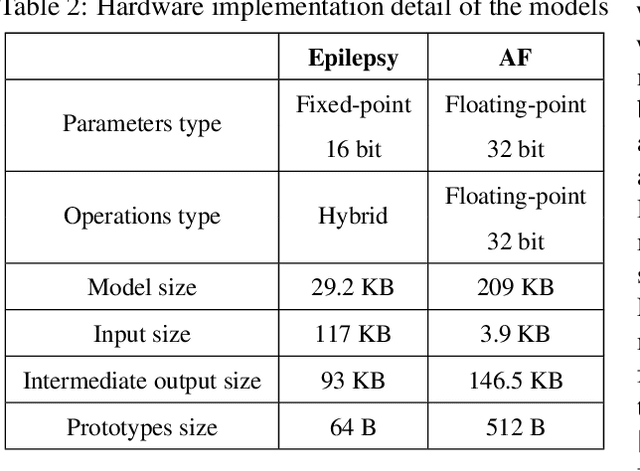
Wearable systems provide continuous health monitoring and can lead to early detection of potential health issues. However, the lifecycle of wearable systems faces several challenges. First, effective model training for new wearable devices requires substantial labeled data from various subjects collected directly by the wearable. Second, subsequent model updates require further extensive labeled data for retraining. Finally, frequent model updating on the wearable device can decrease the battery life in long-term data monitoring. Addressing these challenges, in this paper, we propose MetaWearS, a meta-learning method to reduce the amount of initial data collection required. Moreover, our approach incorporates a prototypical updating mechanism, simplifying the update process by modifying the class prototype rather than retraining the entire model. We explore the performance of MetaWearS in two case studies, namely, the detection of epileptic seizures and the detection of atrial fibrillation. We show that by fine-tuning with just a few samples, we achieve 70% and 82% AUC for the detection of epileptic seizures and the detection of atrial fibrillation, respectively. Compared to a conventional approach, our proposed method performs better with up to 45% AUC. Furthermore, updating the model with only 16 minutes of additional labeled data increases the AUC by up to 5.3%. Finally, MetaWearS reduces the energy consumption for model updates by 456x and 418x for epileptic seizure and AF detection, respectively.
Accelerator-driven Data Arrangement to Minimize Transformers Run-time on Multi-core Architectures
Dec 20, 2023



The increasing complexity of transformer models in artificial intelligence expands their computational costs, memory usage, and energy consumption. Hardware acceleration tackles the ensuing challenges by designing processors and accelerators tailored for transformer models, supporting their computation hotspots with high efficiency. However, memory bandwidth can hinder improvements in hardware accelerators. Against this backdrop, in this paper we propose a novel memory arrangement strategy, governed by the hardware accelerator's kernel size, which effectively minimizes off-chip data access. This arrangement is particularly beneficial for end-to-end transformer model inference, where most of the computation is based on general matrix multiplication (GEMM) operations. Additionally, we address the overhead of non-GEMM operations in transformer models within the scope of this memory data arrangement. Our study explores the implementation and effectiveness of the proposed accelerator-driven data arrangement approach in both single- and multi-core systems. Our evaluation demonstrates that our approach can achieve up to a 2.8x speed increase when executing inferences employing state-of-the-art transformers.
Bit-Line Computing for CNN Accelerators Co-Design in Edge AI Inference
Sep 12, 2022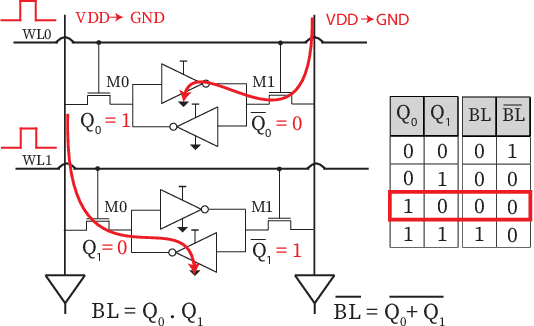
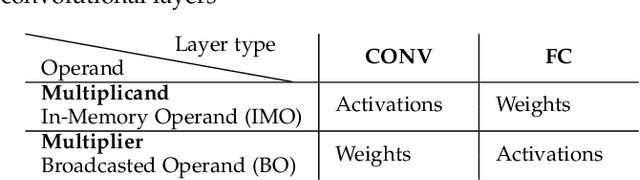

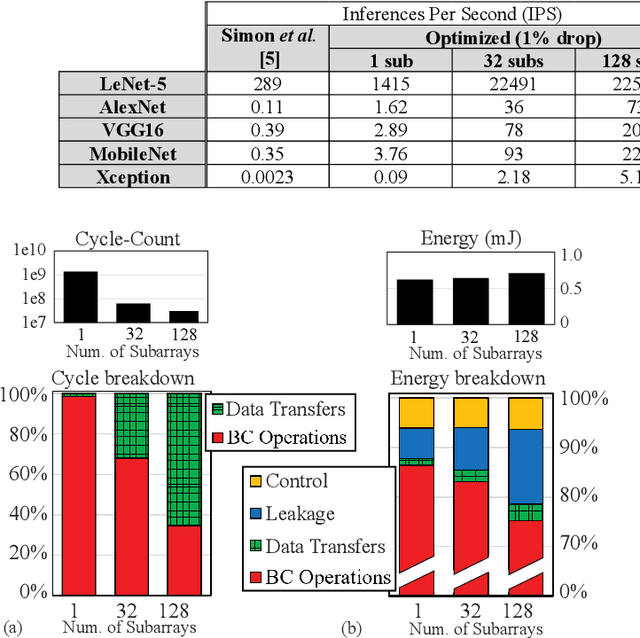
By supporting the access of multiple memory words at the same time, Bit-line Computing (BC) architectures allow the parallel execution of bit-wise operations in-memory. At the array periphery, arithmetic operations are then derived with little additional overhead. Such a paradigm opens novel opportunities for Artificial Intelligence (AI) at the edge, thanks to the massive parallelism inherent in memory arrays and the extreme energy efficiency of computing in-situ, hence avoiding data transfers. Previous works have shown that BC brings disruptive efficiency gains when targeting AI workloads, a key metric in the context of emerging edge AI scenarios. This manuscript builds on these findings by proposing an end-to-end framework that leverages BC-specific optimizations to enable high parallelism and aggressive compression of AI models. Our approach is supported by a novel hardware module performing real-time decoding, as well as new algorithms to enable BC-friendly model compression. Our hardware/software approach results in a 91% energy savings (for a 1% accuracy degradation constraint) regarding state-of-the-art BC computing approaches.
Event-based sampled ECG morphology reconstruction through self-similarity
Jul 05, 2022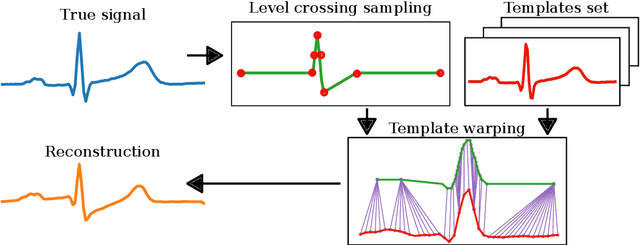

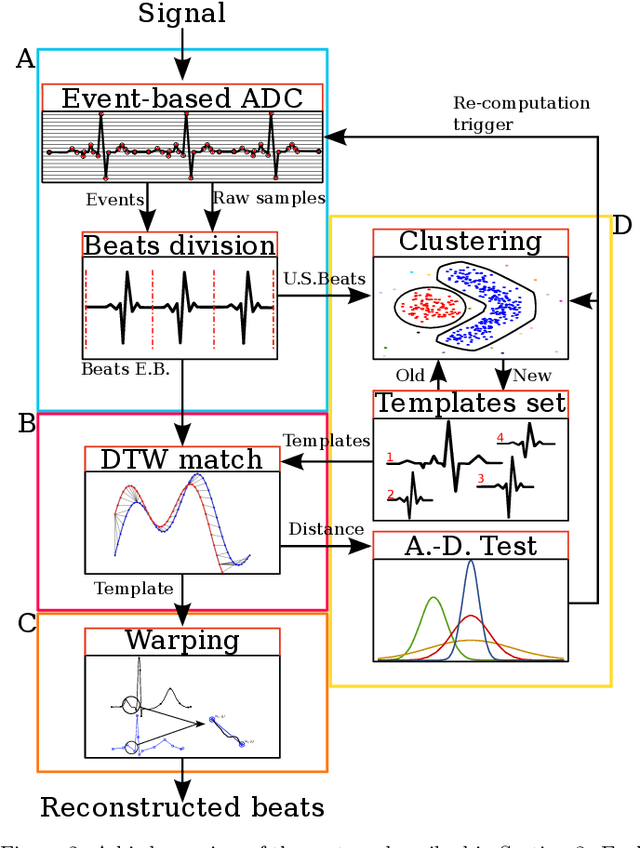

Background and Objective: Event-based analog-to-digital converters allow for sparse bio-signal acquisition, enabling local sub-Nyquist sampling frequency. However, aggressive event selection can cause the loss of important bio-markers, not recoverable with standard interpolation techniques. In this work, we leverage the self-similarity of the electrocardiogram (ECG) signal to recover missing features in event-based sampled ECG signals, dynamically selecting patient-representative templates together with a novel dynamic time warping algorithm to infer the morphology of event-based sampled heartbeats. Methods: We acquire a set of uniformly sampled heartbeats and use a graph-based clustering algorithm to define representative templates for the patient. Then, for each event-based sampled heartbeat, we select the morphologically nearest template, and we then reconstruct the heartbeat with piece-wise linear deformations of the selected template, according to a novel dynamic time warping algorithm that matches events to template segments. Results: Synthetic tests on a standard normal sinus rhythm dataset, composed of approximately 1.8 million normal heartbeats, show a big leap in performance with respect to standard resampling techniques. In particular (when compared to classic linear resampling), we show an improvement in P-wave detection of up to 10 times, an improvement in T-wave detection of up to three times, and a 30\% improvement in the dynamic time warping morphological distance. Conclusion: In this work, we have developed an event-based processing pipeline that leverages signal self-similarity to reconstruct event-based sampled ECG signals. Synthetic tests show clear advantages over classical resampling techniques.