 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystolic Arrays and Structured Pruning Co-design for Efficient Transformers in Edge Systems
Nov 15, 2024



Efficient deployment of resource-intensive transformers on edge devices necessitates cross-stack optimization. We thus study the interrelation between structured pruning and systolic acceleration, matching the size of pruned blocks with the systolic array dimensions. In this setting, computations of pruned weight blocks can be skipped, reducing run-time and energy consumption, but potentially impacting quality of service (QoS). To evaluate the trade-offs between systolic array size and sparsity opportunities, we present a novel co-design framework that integrates algorithmic optimization, system simulation, and hardware design. Targeting speech recognition using transformers as a case study, we analyze how configuration choices across the stack affect performance metrics. Results demonstrate that structured pruning on systems featuring systolic array acceleration can effectively increase performance, while maintaining high QoS levels. Up to 26% system-wide speedups due to structured pruning were measured, with only 1.4% word error rate degradation on the standard Librispeech dataset.
Conditioning LLMs with Emotion in Neural Machine Translation
Aug 06, 2024Large Language Models (LLMs) have shown remarkable performance in Natural Language Processing tasks, including Machine Translation (MT). In this work, we propose a novel MT pipeline that integrates emotion information extracted from a Speech Emotion Recognition (SER) model into LLMs to enhance translation quality. We first fine-tune five existing LLMs on the Libri-trans dataset and select the most performant model. Subsequently, we augment LLM prompts with different dimensional emotions and train the selected LLM under these different configurations. Our experiments reveal that integrating emotion information, especially arousal, into LLM prompts leads to notable improvements in translation quality.
Usefulness of Emotional Prosody in Neural Machine Translation
Apr 27, 2024

Neural Machine Translation (NMT) is the task of translating a text from one language to another with the use of a trained neural network. Several existing works aim at incorporating external information into NMT models to improve or control predicted translations (e.g. sentiment, politeness, gender). In this work, we propose to improve translation quality by adding another external source of information: the automatically recognized emotion in the voice. This work is motivated by the assumption that each emotion is associated with a specific lexicon that can overlap between emotions. Our proposed method follows a two-stage procedure. At first, we select a state-of-the-art Speech Emotion Recognition (SER) model to predict dimensional emotion values from all input audio in the dataset. Then, we use these predicted emotions as source tokens added at the beginning of input texts to train our NMT model. We show that integrating emotion information, especially arousal, into NMT systems leads to better translations.
End-to-End Speech Recognition: A review for the French Language
Oct 23, 2019
Recently, end-to-end ASR based either on sequence-to-sequence networks or on the CTC objective function gained a lot of interest from the community, achieving competitive results over traditional systems using robust but complex pipelines. One of the main features of end-to-end systems, in addition to the ability to free themselves from extra linguistic resources such as dictionaries or language models, is the capacity to model acoustic units such as characters, subwords or directly words; opening up the capacity to directly translate speech with different representations or levels of knowledge depending on the target language. In this paper we propose a review of the existing end-to-end ASR approaches for the French language. We compare results to conventional state-of-the-art ASR systems and discuss which units are more suited to model the French language.
Regularized Optimal Transport and the Rot Mover's Distance
Jul 14, 2018

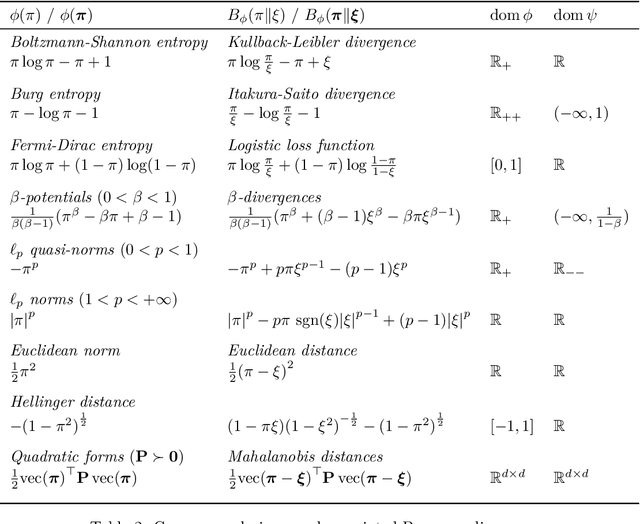
This paper presents a unified framework for smooth convex regularization of discrete optimal transport problems. In this context, the regularized optimal transport turns out to be equivalent to a matrix nearness problem with respect to Bregman divergences. Our framework thus naturally generalizes a previously proposed regularization based on the Boltzmann-Shannon entropy related to the Kullback-Leibler divergence, and solved with the Sinkhorn-Knopp algorithm. We call the regularized optimal transport distance the rot mover's distance in reference to the classical earth mover's distance. We develop two generic schemes that we respectively call the alternate scaling algorithm and the non-negative alternate scaling algorithm, to compute efficiently the regularized optimal plans depending on whether the domain of the regularizer lies within the non-negative orthant or not. These schemes are based on Dykstra's algorithm with alternate Bregman projections, and further exploit the Newton-Raphson method when applied to separable divergences. We enhance the separable case with a sparse extension to deal with high data dimensions. We also instantiate our proposed framework and discuss the inherent specificities for well-known regularizers and statistical divergences in the machine learning and information geometry communities. Finally, we demonstrate the merits of our methods with experiments using synthetic data to illustrate the effect of different regularizers and penalties on the solutions, as well as real-world data for a pattern recognition application to audio scene classification.