 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditioning LLMs with Emotion in Neural Machine Translation
Aug 06, 2024Large Language Models (LLMs) have shown remarkable performance in Natural Language Processing tasks, including Machine Translation (MT). In this work, we propose a novel MT pipeline that integrates emotion information extracted from a Speech Emotion Recognition (SER) model into LLMs to enhance translation quality. We first fine-tune five existing LLMs on the Libri-trans dataset and select the most performant model. Subsequently, we augment LLM prompts with different dimensional emotions and train the selected LLM under these different configurations. Our experiments reveal that integrating emotion information, especially arousal, into LLM prompts leads to notable improvements in translation quality.
Usefulness of Emotional Prosody in Neural Machine Translation
Apr 27, 2024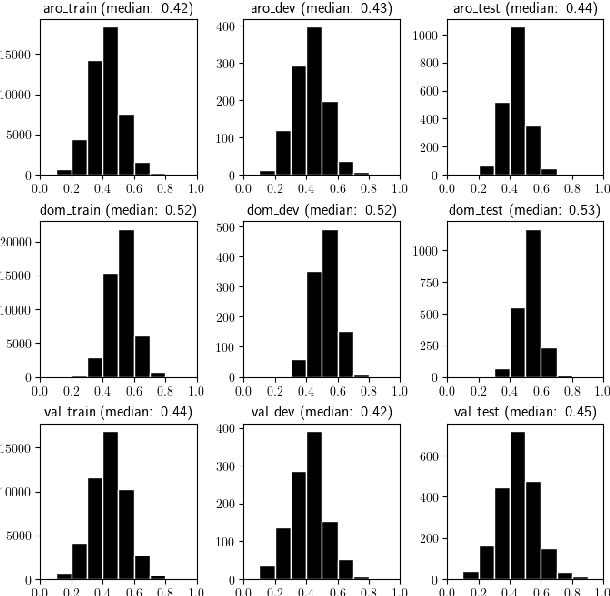

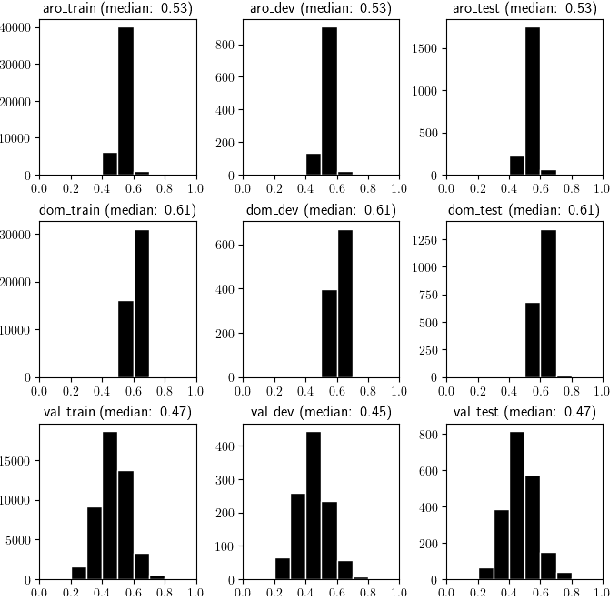
Neural Machine Translation (NMT) is the task of translating a text from one language to another with the use of a trained neural network. Several existing works aim at incorporating external information into NMT models to improve or control predicted translations (e.g. sentiment, politeness, gender). In this work, we propose to improve translation quality by adding another external source of information: the automatically recognized emotion in the voice. This work is motivated by the assumption that each emotion is associated with a specific lexicon that can overlap between emotions. Our proposed method follows a two-stage procedure. At first, we select a state-of-the-art Speech Emotion Recognition (SER) model to predict dimensional emotion values from all input audio in the dataset. Then, we use these predicted emotions as source tokens added at the beginning of input texts to train our NMT model. We show that integrating emotion information, especially arousal, into NMT systems leads to better translations.
Improving Real-time Score Following in Opera by Combining Music with Lyrics Tracking
Oct 06, 2021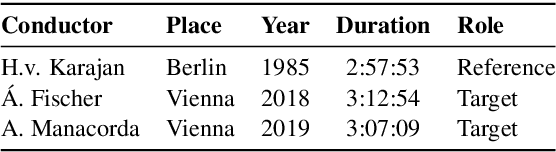
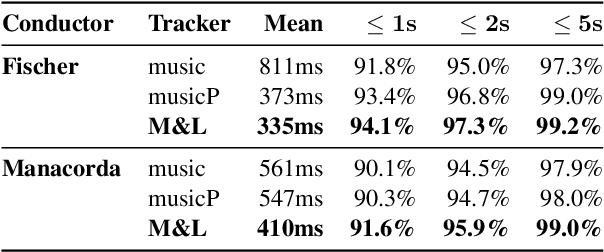
Fully automatic opera tracking is challenging because of the acoustic complexity of the genre, combining musical and linguistic information (singing, speech) in complex ways. In this paper, we propose a new pipeline for complete opera tracking. The pipeline is based on two trackers. A music tracker that has proven to be effective at tracking orchestral parts, will lead the tracking process. In addition, a lyrics tracker, that has recently been shown to reliably track the lyrics of opera songs, will correct the music tracker when tracking parts that have a text dominance over the music. We will demonstrate the efficiency of this method on the opera Don Giovanni, showing that this technique helps improving accuracy and robustness of a complete opera tracker.
On-Line Audio-to-Lyrics Alignment Based on a Reference Performance
Jul 30, 2021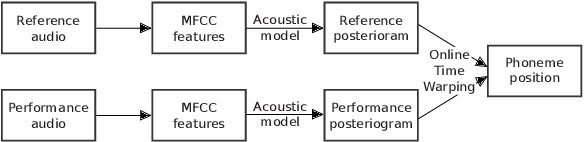
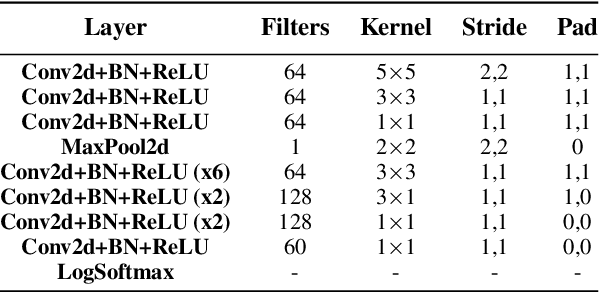
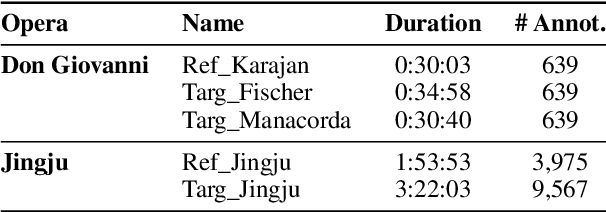

Audio-to-lyrics alignment has become an increasingly active research task in MIR, supported by the emergence of several open-source datasets of audio recordings with word-level lyrics annotations. However, there are still a number of open problems, such as a lack of robustness in the face of severe duration mismatches between audio and lyrics representation; a certain degree of language-specificity caused by acoustic differences across languages; and the fact that most successful methods in the field are not suited to work in real-time. Real-time lyrics alignment (tracking) would have many useful applications, such as fully automated subtitle display in live concerts and opera. In this work, we describe the first real-time-capable audio-to-lyrics alignment pipeline that is able to robustly track the lyrics of different languages, without additional language information. The proposed model predicts, for each audio frame, a probability vector over (European) phoneme classes, using a very small temporal context, and aligns this vector with a phoneme posteriogram matrix computed beforehand from another recording of the same work, which serves as a reference and a proxy to the written-out lyrics. We evaluate our system's tracking accuracy on the challenging genre of classical opera. Finally, robustness to out-of-training languages is demonstrated in an experiment on Jingju (Beijing opera).
Handling Structural Mismatches in Real-time Opera Tracking
May 18, 2021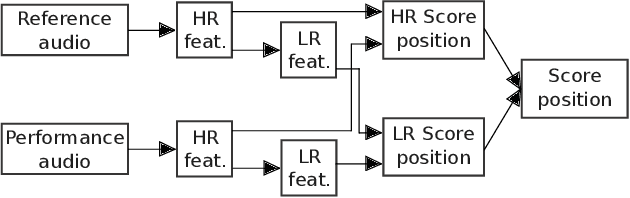


Algorithms for reliable real-time score following in live opera promise a lot of useful applications such as automatic subtitles display, or real-time video cutting in live streaming. Until now, such systems were based on the strong assumption that an opera performance follows the structure of the score linearly. However, this is rarely the case in practice, because of different opera versions and directors' cutting choices. In this paper, we propose a two-level solution to this problem. We introduce a real-time-capable, high-resolution (HR) tracker that can handle jumps or repetitions at specific locations provided to it. We then combine this with an additional low-resolution (LR) tracker that can handle all sorts of mismatches that can occur at any time, with some imprecision, and can re-direct the HR tracker if the latter is `lost' in the score. We show that the combination of the two improves tracking robustness in the presence of strong structural mismatches.
Towards Reliable Real-time Opera Tracking: Combining Alignment with Audio Event Detectors to Increase Robustness
Jun 19, 2020
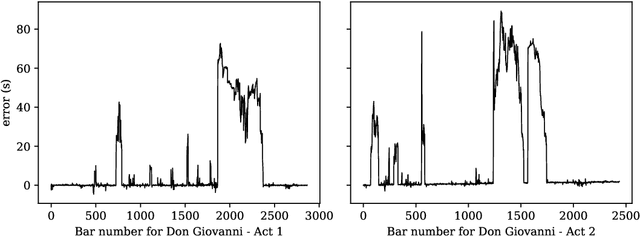


Recent advances in real-time music score following have made it possible for machines to automatically track highly complex polyphonic music, including full orchestra performances. In this paper, we attempt to take this to an even higher level, namely, live tracking of full operas. We first apply a state-of-the-art audio alignment method based on online Dynamic Time-Warping (OLTW) to full-length recordings of a Mozart opera and, analyzing the tracker's most severe errors, identify three common sources of problems specific to the opera scenario. To address these, we propose a combination of a DTW-based music tracker with specialized audio event detectors (for applause, silence/noise, and speech) that condition the DTW algorithm in a top-down fashion, and show, step by step, how these detectors add robustness to the score follower. However, there remain a number of open problems which we identify as targets for ongoing and future research.