 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Line Audio-to-Lyrics Alignment Based on a Reference Performance
Paper and Code
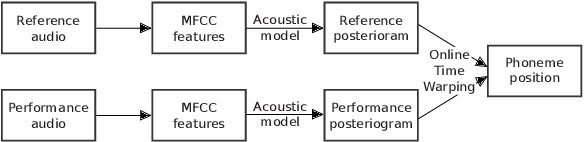
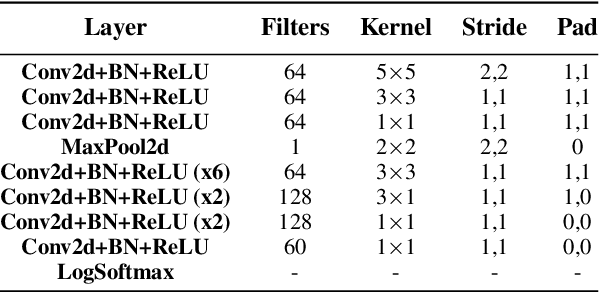
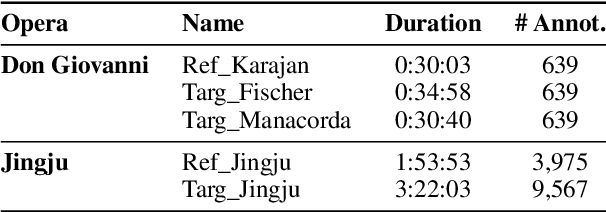

Audio-to-lyrics alignment has become an increasingly active research task in MIR, supported by the emergence of several open-source datasets of audio recordings with word-level lyrics annotations. However, there are still a number of open problems, such as a lack of robustness in the face of severe duration mismatches between audio and lyrics representation; a certain degree of language-specificity caused by acoustic differences across languages; and the fact that most successful methods in the field are not suited to work in real-time. Real-time lyrics alignment (tracking) would have many useful applications, such as fully automated subtitle display in live concerts and opera. In this work, we describe the first real-time-capable audio-to-lyrics alignment pipeline that is able to robustly track the lyrics of different languages, without additional language information. The proposed model predicts, for each audio frame, a probability vector over (European) phoneme classes, using a very small temporal context, and aligns this vector with a phoneme posteriogram matrix computed beforehand from another recording of the same work, which serves as a reference and a proxy to the written-out lyrics. We evaluate our system's tracking accuracy on the challenging genre of classical opera. Finally, robustness to out-of-training languages is demonstrated in an experiment on Jingju (Beijing opera).