 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeITA: An Energy-Efficient Attention and Softmax Accelerator for Quantized Transformers
Jul 10, 2023



Transformer networks have emerged as the state-of-the-art approach for natural language processing tasks and are gaining popularity in other domains such as computer vision and audio processing. However, the efficient hardware acceleration of transformer models poses new challenges due to their high arithmetic intensities, large memory requirements, and complex dataflow dependencies. In this work, we propose ITA, a novel accelerator architecture for transformers and related models that targets efficient inference on embedded systems by exploiting 8-bit quantization and an innovative softmax implementation that operates exclusively on integer values. By computing on-the-fly in streaming mode, our softmax implementation minimizes data movement and energy consumption. ITA achieves competitive energy efficiency with respect to state-of-the-art transformer accelerators with 16.9 TOPS/W, while outperforming them in area efficiency with 5.93 TOPS/mm$^2$ in 22 nm fully-depleted silicon-on-insulator technology at 0.8 V.
Marsellus: A Heterogeneous RISC-V AI-IoT End-Node SoC with 2-to-8b DNN Acceleration and 30%-Boost Adaptive Body Biasing
May 15, 2023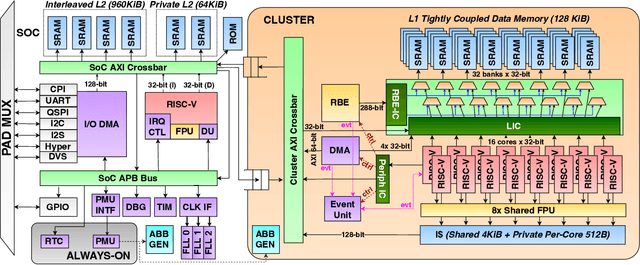
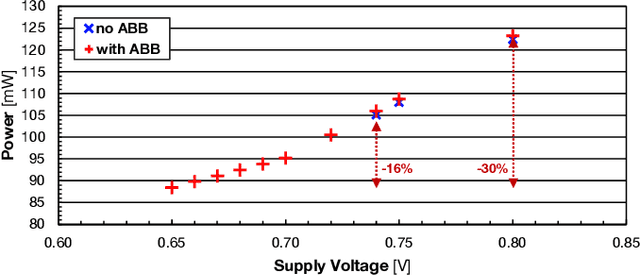
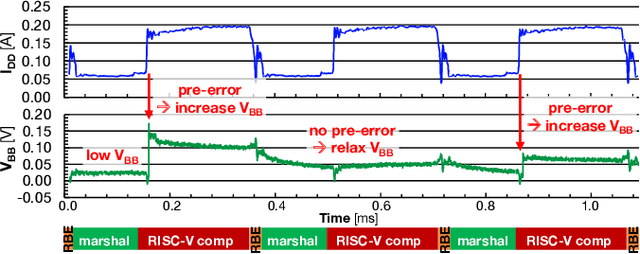
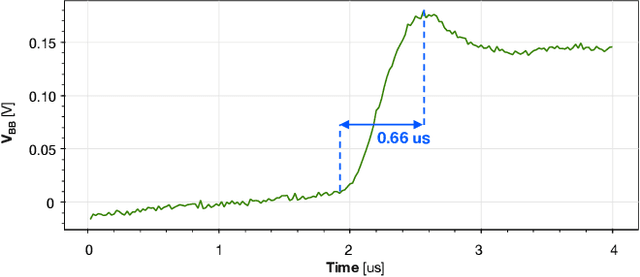
Emerging Artificial Intelligence-enabled Internet-of-Things (AI-IoT) System-on-a-Chip (SoC) for augmented reality, personalized healthcare, and nano-robotics need to run many diverse tasks within a power envelope of a few tens of mW over a wide range of operating conditions: compute-intensive but strongly quantized Deep Neural Network (DNN) inference, as well as signal processing and control requiring high-precision floating-point. We present Marsellus, an all-digital heterogeneous SoC for AI-IoT end-nodes fabricated in GlobalFoundries 22nm FDX that combines 1) a general-purpose cluster of 16 RISC-V Digital Signal Processing (DSP) cores attuned for the execution of a diverse range of workloads exploiting 4-bit and 2-bit arithmetic extensions (XpulpNN), combined with fused MAC&LOAD operations and floating-point support; 2) a 2-8bit Reconfigurable Binary Engine (RBE) to accelerate 3x3 and 1x1 (pointwise) convolutions in DNNs; 3) a set of On-Chip Monitoring (OCM) blocks connected to an Adaptive Body Biasing (ABB) generator and a hardware control loop, enabling on-the-fly adaptation of transistor threshold voltages. Marsellus achieves up to 180 Gop/s or 3.32 Top/s/W on 2-bit precision arithmetic in software, and up to 637 Gop/s or 12.4 Top/s/W on hardware-accelerated DNN layers.
Vau da muntanialas: Energy-efficient multi-die scalable acceleration of RNN inference
Feb 14, 2022



Recurrent neural networks such as Long Short-Term Memories (LSTMs) learn temporal dependencies by keeping an internal state, making them ideal for time-series problems such as speech recognition. However, the output-to-input feedback creates distinctive memory bandwidth and scalability challenges in designing accelerators for RNNs. We present Muntaniala, an RNN accelerator architecture for LSTM inference with a silicon-measured energy-efficiency of 3.25$TOP/s/W$ and performance of 30.53$GOP/s$ in UMC 65 $nm$ technology. The scalable design of Muntaniala allows running large RNN models by combining multiple tiles in a systolic array. We keep all parameters stationary on every die in the array, drastically reducing the I/O communication to only loading new features and sharing partial results with other dies. For quantifying the overall system power, including I/O power, we built Vau da Muntanialas, to the best of our knowledge, the first demonstration of a systolic multi-chip-on-PCB array of RNN accelerator. Our multi-die prototype performs LSTM inference with 192 hidden states in 330$\mu s$ with a total system power of 9.0$mW$ at 10$MHz$ consuming 2.95$\mu J$. Targeting the 8/16-bit quantization implemented in Muntaniala, we show a phoneme error rate (PER) drop of approximately 3% with respect to floating-point (FP) on a 3L-384NH-123NI LSTM network on the TIMIT dataset.
Chipmunk: A Systolically Scalable 0.9 mm${}^2$, 3.08 Gop/s/mW @ 1.2 mW Accelerator for Near-Sensor Recurrent Neural Network Inference
Feb 20, 2018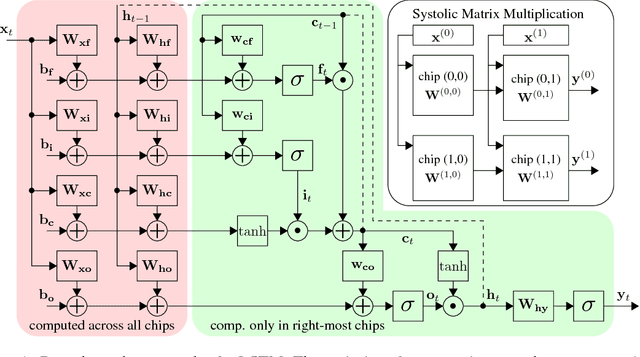
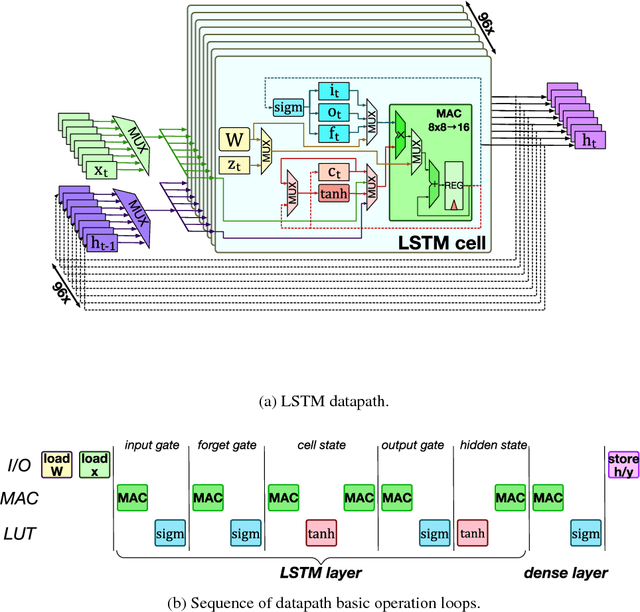
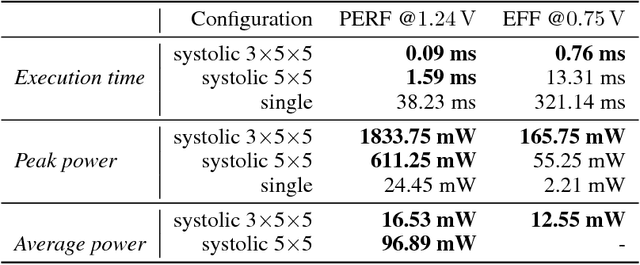
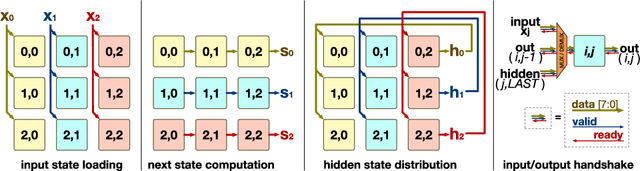
Recurrent neural networks (RNNs) are state-of-the-art in voice awareness/understanding and speech recognition. On-device computation of RNNs on low-power mobile and wearable devices would be key to applications such as zero-latency voice-based human-machine interfaces. Here we present Chipmunk, a small (<1 mm${}^2$) hardware accelerator for Long-Short Term Memory RNNs in UMC 65 nm technology capable to operate at a measured peak efficiency up to 3.08 Gop/s/mW at 1.24 mW peak power. To implement big RNN models without incurring in huge memory transfer overhead, multiple Chipmunk engines can cooperate to form a single systolic array. In this way, the Chipmunk architecture in a 75 tiles configuration can achieve real-time phoneme extraction on a demanding RNN topology proposed by Graves et al., consuming less than 13 mW of average power.