 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Attention-based TinyML: A Heterogeneous Accelerated Architecture and Automated Deployment Flow
Aug 05, 2024One of the challenges for Tiny Machine Learning (tinyML) is keeping up with the evolution of Machine Learning models from Convolutional Neural Networks to Transformers. We address this by leveraging a heterogeneous architectural template coupling RISC-V processors with hardwired accelerators supported by an automated deployment flow. We demonstrate an Attention-based model in a tinyML power envelope with an octa-core cluster coupled with an accelerator for quantized Attention. Our deployment flow enables an end-to-end 8-bit MobileBERT, achieving leading-edge energy efficiency and throughput of 2960 GOp/J and 154 GOp/s at 32.5 Inf/s consuming 52.0 mW (0.65 V, 22 nm FD-SOI technology).
Optimizing the Deployment of Tiny Transformers on Low-Power MCUs
Apr 03, 2024


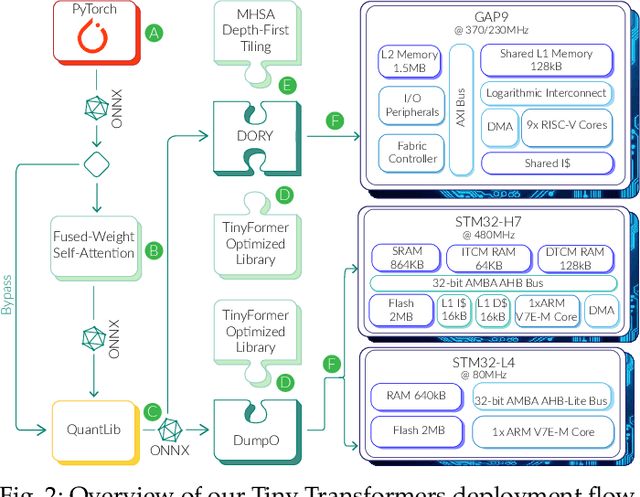
Transformer networks are rapidly becoming SotA in many fields, such as NLP and CV. Similarly to CNN, there is a strong push for deploying Transformer models at the extreme edge, ultimately fitting the tiny power budget and memory footprint of MCUs. However, the early approaches in this direction are mostly ad-hoc, platform, and model-specific. This work aims to enable and optimize the flexible, multi-platform deployment of encoder Tiny Transformers on commercial MCUs. We propose a complete framework to perform end-to-end deployment of Transformer models onto single and multi-core MCUs. Our framework provides an optimized library of kernels to maximize data reuse and avoid unnecessary data marshaling operations into the crucial attention block. A novel MHSA inference schedule, named Fused-Weight Self-Attention, is introduced, fusing the linear projection weights offline to further reduce the number of operations and parameters. Furthermore, to mitigate the memory peak reached by the computation of the attention map, we present a Depth-First Tiling scheme for MHSA. We evaluate our framework on three different MCU classes exploiting ARM and RISC-V ISA, namely the STM32H7, the STM32L4, and GAP9 (RV32IMC-XpulpV2). We reach an average of 4.79x and 2.0x lower latency compared to SotA libraries CMSIS-NN (ARM) and PULP-NN (RISC-V), respectively. Moreover, we show that our MHSA depth-first tiling scheme reduces the memory peak by up to 6.19x, while the fused-weight attention can reduce the runtime by 1.53x, and number of parameters by 25%. We report significant improvements across several Tiny Transformers: for instance, when executing a transformer block for the task of radar-based hand-gesture recognition on GAP9, we achieve a latency of 0.14ms and energy consumption of 4.92 micro-joules, 2.32x lower than the SotA PULP-NN library on the same platform.
ITA: An Energy-Efficient Attention and Softmax Accelerator for Quantized Transformers
Jul 10, 2023



Transformer networks have emerged as the state-of-the-art approach for natural language processing tasks and are gaining popularity in other domains such as computer vision and audio processing. However, the efficient hardware acceleration of transformer models poses new challenges due to their high arithmetic intensities, large memory requirements, and complex dataflow dependencies. In this work, we propose ITA, a novel accelerator architecture for transformers and related models that targets efficient inference on embedded systems by exploiting 8-bit quantization and an innovative softmax implementation that operates exclusively on integer values. By computing on-the-fly in streaming mode, our softmax implementation minimizes data movement and energy consumption. ITA achieves competitive energy efficiency with respect to state-of-the-art transformer accelerators with 16.9 TOPS/W, while outperforming them in area efficiency with 5.93 TOPS/mm$^2$ in 22 nm fully-depleted silicon-on-insulator technology at 0.8 V.
SALSA: Simulated Annealing based Loop-Ordering Scheduler for DNN Accelerators
Apr 20, 2023



To meet the growing need for computational power for DNNs, multiple specialized hardware architectures have been proposed. Each DNN layer should be mapped onto the hardware with the most efficient schedule, however, SotA schedulers struggle to consistently provide optimum schedules in a reasonable time across all DNN-HW combinations. This paper proposes SALSA, a fast dual-engine scheduler to generate optimal execution schedules for both even and uneven mapping. We introduce a new strategy, combining exhaustive search with simulated annealing to address the dynamic nature of the loop ordering design space size across layers. SALSA is extensively benchmarked against two SotA schedulers, LOMA and Timeloop on 5 different DNNs, on average SALSA finds schedules with 11.9% and 7.6% lower energy while speeding up the search by 1.7x and 24x compared to LOMA and Timeloop, respectively.