 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing the Deployment of Tiny Transformers on Low-Power MCUs
Paper and Code



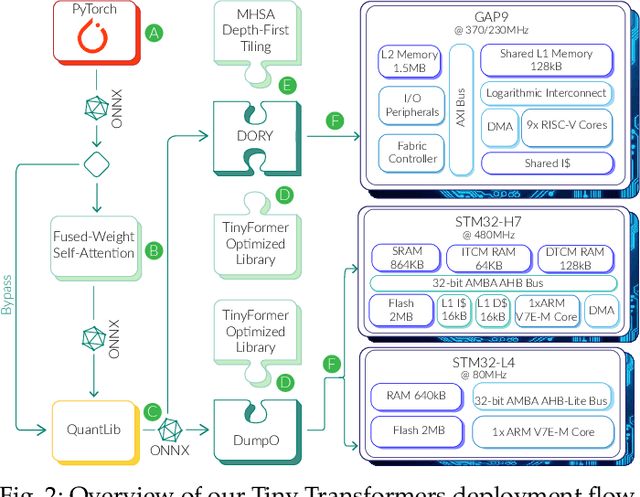
Transformer networks are rapidly becoming SotA in many fields, such as NLP and CV. Similarly to CNN, there is a strong push for deploying Transformer models at the extreme edge, ultimately fitting the tiny power budget and memory footprint of MCUs. However, the early approaches in this direction are mostly ad-hoc, platform, and model-specific. This work aims to enable and optimize the flexible, multi-platform deployment of encoder Tiny Transformers on commercial MCUs. We propose a complete framework to perform end-to-end deployment of Transformer models onto single and multi-core MCUs. Our framework provides an optimized library of kernels to maximize data reuse and avoid unnecessary data marshaling operations into the crucial attention block. A novel MHSA inference schedule, named Fused-Weight Self-Attention, is introduced, fusing the linear projection weights offline to further reduce the number of operations and parameters. Furthermore, to mitigate the memory peak reached by the computation of the attention map, we present a Depth-First Tiling scheme for MHSA. We evaluate our framework on three different MCU classes exploiting ARM and RISC-V ISA, namely the STM32H7, the STM32L4, and GAP9 (RV32IMC-XpulpV2). We reach an average of 4.79x and 2.0x lower latency compared to SotA libraries CMSIS-NN (ARM) and PULP-NN (RISC-V), respectively. Moreover, we show that our MHSA depth-first tiling scheme reduces the memory peak by up to 6.19x, while the fused-weight attention can reduce the runtime by 1.53x, and number of parameters by 25%. We report significant improvements across several Tiny Transformers: for instance, when executing a transformer block for the task of radar-based hand-gesture recognition on GAP9, we achieve a latency of 0.14ms and energy consumption of 4.92 micro-joules, 2.32x lower than the SotA PULP-NN library on the same platform.