 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexTern: Energy-Efficient Ternary Neural Network Inference on RISC-V-Based Edge Systems
May 29, 2024



Ternary neural networks (TNNs) offer a superior accuracy-energy trade-off compared to binary neural networks. However, until now, they have required specialized accelerators to realize their efficiency potential, which has hindered widespread adoption. To address this, we present xTern, a lightweight extension of the RISC-V instruction set architecture (ISA) targeted at accelerating TNN inference on general-purpose cores. To complement the ISA extension, we developed a set of optimized kernels leveraging xTern, achieving 67% higher throughput than their 2-bit equivalents. Power consumption is only marginally increased by 5.2%, resulting in an energy efficiency improvement by 57.1%. We demonstrate that the proposed xTern extension, integrated into an octa-core compute cluster, incurs a minimal silicon area overhead of 0.9% with no impact on timing. In end-to-end benchmarks, we demonstrate that xTern enables the deployment of TNNs achieving up to 1.6 percentage points higher CIFAR-10 classification accuracy than 2-bit networks at equal inference latency. Our results show that xTern enables RISC-V-based ultra-low-power edge AI platforms to benefit from the efficiency potential of TNNs.
Combining Local and Global Perception for Autonomous Navigation on Nano-UAVs
Mar 18, 2024


A critical challenge in deploying unmanned aerial vehicles (UAVs) for autonomous tasks is their ability to navigate in an unknown environment. This paper introduces a novel vision-depth fusion approach for autonomous navigation on nano-UAVs. We combine the visual-based PULP-Dronet convolutional neural network for semantic information extraction, i.e., serving as the global perception, with 8x8px depth maps for close-proximity maneuvers, i.e., the local perception. When tested in-field, our integration strategy highlights the complementary strengths of both visual and depth sensory information. We achieve a 100% success rate over 15 flights in a complex navigation scenario, encompassing straight pathways, static obstacle avoidance, and 90{\deg} turns.
Flexible and Fully Quantized Ultra-Lightweight TinyissimoYOLO for Ultra-Low-Power Edge Systems
Jul 14, 2023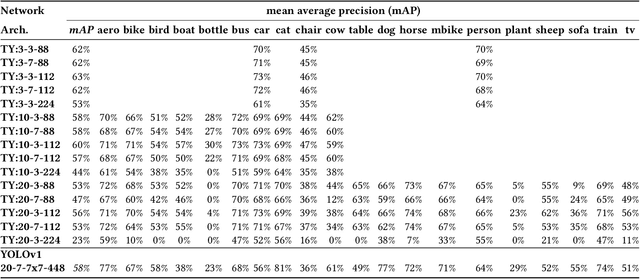
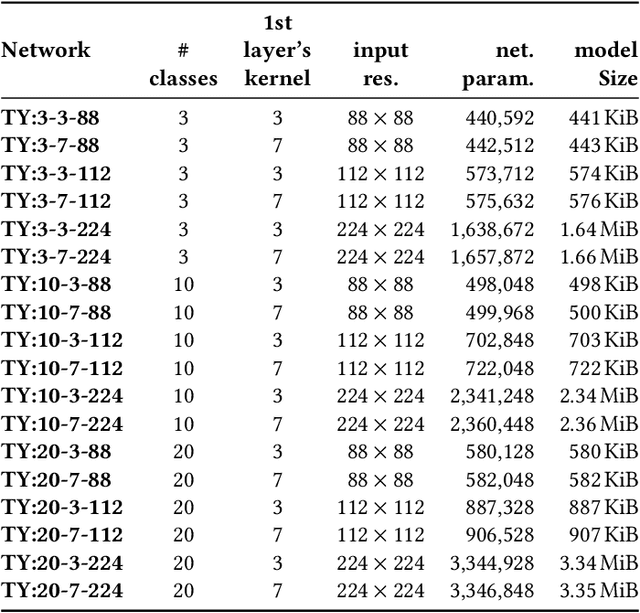

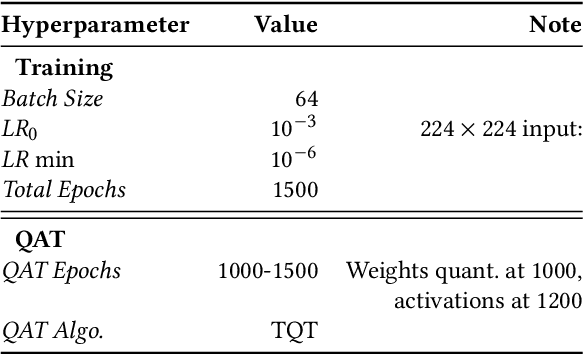
This paper deploys and explores variants of TinyissimoYOLO, a highly flexible and fully quantized ultra-lightweight object detection network designed for edge systems with a power envelope of a few milliwatts. With experimental measurements, we present a comprehensive characterization of the network's detection performance, exploring the impact of various parameters, including input resolution, number of object classes, and hidden layer adjustments. We deploy variants of TinyissimoYOLO on state-of-the-art ultra-low-power extreme edge platforms, presenting an in-depth a comparison on latency, energy efficiency, and their ability to efficiently parallelize the workload. In particular, the paper presents a comparison between a novel parallel RISC-V processor (GAP9 from Greenwaves) with and without use of its on-chip hardware accelerator, an ARM Cortex-M7 core (STM32H7 from ST Microelectronics), two ARM Cortex-M4 cores (STM32L4 from STM and Apollo4b from Ambiq), and a multi-core platform with a CNN hardware accelerator (Analog Devices MAX78000). Experimental results show that the GAP9's hardware accelerator achieves the lowest inference latency and energy at 2.12ms and 150uJ respectively, which is around 2x faster and 20% more efficient than the next best platform, the MAX78000. The hardware accelerator of GAP9 can even run an increased resolution version of TinyissimoYOLO with 112x112 pixels and 10 detection classes within 3.2ms, consuming 245uJ. To showcase the competitiveness of a versatile general-purpose system we also deployed and profiled a multi-core implementation on GAP9 at different operating points, achieving 11.3ms with the lowest-latency and 490uJ with the most energy-efficient configuration. With this paper, we demonstrate the suitability and flexibility of TinyissimoYOLO on state-of-the-art detection datasets for real-time ultra-low-power edge inference.
Free Bits: Latency Optimization of Mixed-Precision Quantized Neural Networks on the Edge
Jul 06, 2023Mixed-precision quantization, where a deep neural network's layers are quantized to different precisions, offers the opportunity to optimize the trade-offs between model size, latency, and statistical accuracy beyond what can be achieved with homogeneous-bit-width quantization. To navigate the intractable search space of mixed-precision configurations for a given network, this paper proposes a hybrid search methodology. It consists of a hardware-agnostic differentiable search algorithm followed by a hardware-aware heuristic optimization to find mixed-precision configurations latency-optimized for a specific hardware target. We evaluate our algorithm on MobileNetV1 and MobileNetV2 and deploy the resulting networks on a family of multi-core RISC-V microcontroller platforms with different hardware characteristics. We achieve up to 28.6% reduction of end-to-end latency compared to an 8-bit model at a negligible accuracy drop from a full-precision baseline on the 1000-class ImageNet dataset. We demonstrate speedups relative to an 8-bit baseline, even on systems with no hardware support for sub-byte arithmetic at negligible accuracy drop. Furthermore, we show the superiority of our approach with respect to differentiable search targeting reduced binary operation counts as a proxy for latency.
ColibriUAV: An Ultra-Fast, Energy-Efficient Neuromorphic Edge Processing UAV-Platform with Event-Based and Frame-Based Cameras
May 27, 2023The interest in dynamic vision sensor (DVS)-powered unmanned aerial vehicles (UAV) is raising, especially due to the microsecond-level reaction time of the bio-inspired event sensor, which increases robustness and reduces latency of the perception tasks compared to a RGB camera. This work presents ColibriUAV, a UAV platform with both frame-based and event-based cameras interfaces for efficient perception and near-sensor processing. The proposed platform is designed around Kraken, a novel low-power RISC-V System on Chip with two hardware accelerators targeting spiking neural networks and deep ternary neural networks.Kraken is capable of efficiently processing both event data from a DVS camera and frame data from an RGB camera. A key feature of Kraken is its integrated, dedicated interface with a DVS camera. This paper benchmarks the end-to-end latency and power efficiency of the neuromorphic and event-based UAV subsystem, demonstrating state-of-the-art event data with a throughput of 7200 frames of events per second and a power consumption of 10.7 \si{\milli\watt}, which is over 6.6 times faster and a hundred times less power-consuming than the widely-used data reading approach through the USB interface. The overall sensing and processing power consumption is below 50 mW, achieving latency in the milliseconds range, making the platform suitable for low-latency autonomous nano-drones as well.
Marsellus: A Heterogeneous RISC-V AI-IoT End-Node SoC with 2-to-8b DNN Acceleration and 30%-Boost Adaptive Body Biasing
May 15, 2023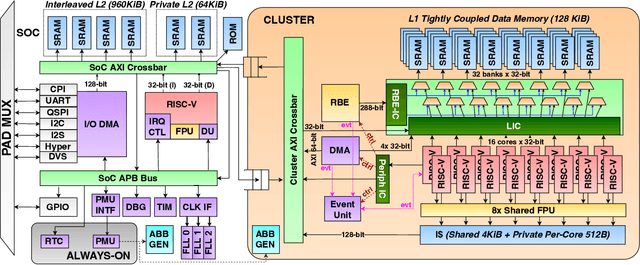
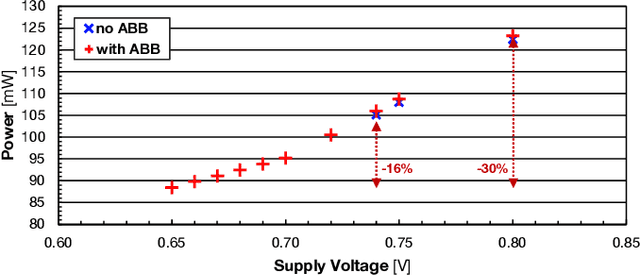
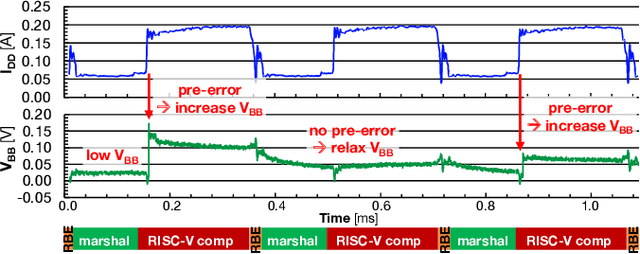
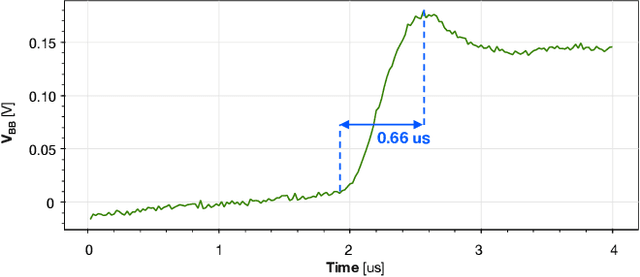
Emerging Artificial Intelligence-enabled Internet-of-Things (AI-IoT) System-on-a-Chip (SoC) for augmented reality, personalized healthcare, and nano-robotics need to run many diverse tasks within a power envelope of a few tens of mW over a wide range of operating conditions: compute-intensive but strongly quantized Deep Neural Network (DNN) inference, as well as signal processing and control requiring high-precision floating-point. We present Marsellus, an all-digital heterogeneous SoC for AI-IoT end-nodes fabricated in GlobalFoundries 22nm FDX that combines 1) a general-purpose cluster of 16 RISC-V Digital Signal Processing (DSP) cores attuned for the execution of a diverse range of workloads exploiting 4-bit and 2-bit arithmetic extensions (XpulpNN), combined with fused MAC&LOAD operations and floating-point support; 2) a 2-8bit Reconfigurable Binary Engine (RBE) to accelerate 3x3 and 1x1 (pointwise) convolutions in DNNs; 3) a set of On-Chip Monitoring (OCM) blocks connected to an Adaptive Body Biasing (ABB) generator and a hardware control loop, enabling on-the-fly adaptation of transistor threshold voltages. Marsellus achieves up to 180 Gop/s or 3.32 Top/s/W on 2-bit precision arithmetic in software, and up to 637 Gop/s or 12.4 Top/s/W on hardware-accelerated DNN layers.
EBPC: Extended Bit-Plane Compression for Deep Neural Network Inference and Training Accelerators
Aug 30, 2019
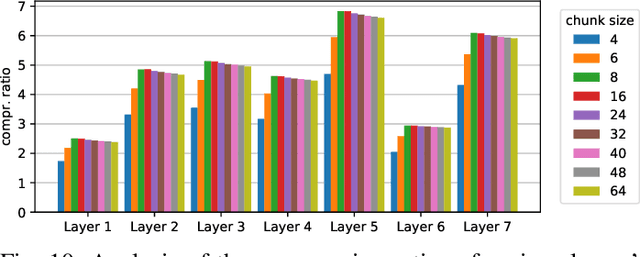
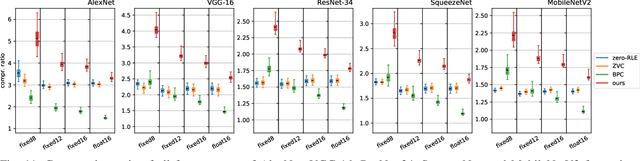
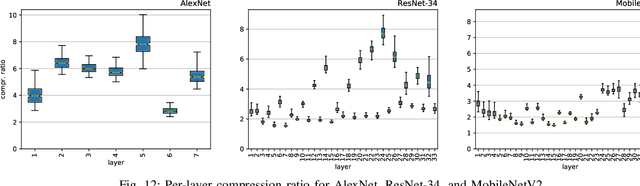
In the wake of the success of convolutional neural networks in image classification, object recognition, speech recognition, etc., the demand for deploying these compute-intensive ML models on embedded and mobile systems with tight power and energy constraints at low cost, as well as for boosting throughput in data centers, is growing rapidly. This has sparked a surge of research into specialized hardware accelerators. Their performance is typically limited by I/O bandwidth, power consumption is dominated by I/O transfers to off-chip memory, and on-chip memories occupy a large part of the silicon area. We introduce and evaluate a novel, hardware-friendly and lossless compression scheme for the feature maps present within convolutional neural networks. Its hardware implementation fits into 2.8 kGE and 1.7 kGE of silicon area for the compressor and decompressor, respectively. We show that an average compression ratio of 5.1x for AlexNet, 4x for VGG-16, 2.4x for ResNet-34 and 2.2x for MobileNetV2 can be achieved---a gain of 45--70% over existing methods. Our approach also works effectively for various number formats, has a low frame-to-frame variance on the compression ratio, and achieves compression factors for gradient map compression during training that are even better than for inference.