 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual staining for 3D X-ray histology of bone implants
Sep 11, 2025Three-dimensional X-ray histology techniques offer a non-invasive alternative to conventional 2D histology, enabling volumetric imaging of biological tissues without the need for physical sectioning or chemical staining. However, the inherent greyscale image contrast of X-ray tomography limits its biochemical specificity compared to traditional histological stains. Within digital pathology, deep learning-based virtual staining has demonstrated utility in simulating stained appearances from label-free optical images. In this study, we extend virtual staining to the X-ray domain by applying cross-modality image translation to generate artificially stained slices from synchrotron-radiation-based micro-CT scans. Using over 50 co-registered image pairs of micro-CT and toluidine blue-stained histology from bone-implant samples, we trained a modified CycleGAN network tailored for limited paired data. Whole slide histology images were downsampled to match the voxel size of the CT data, with on-the-fly data augmentation for patch-based training. The model incorporates pixelwise supervision and greyscale consistency terms, producing histologically realistic colour outputs while preserving high-resolution structural detail. Our method outperformed Pix2Pix and standard CycleGAN baselines across SSIM, PSNR, and LPIPS metrics. Once trained, the model can be applied to full CT volumes to generate virtually stained 3D datasets, enhancing interpretability without additional sample preparation. While features such as new bone formation were able to be reproduced, some variability in the depiction of implant degradation layers highlights the need for further training data and refinement. This work introduces virtual staining to 3D X-ray imaging and offers a scalable route for chemically informative, label-free tissue characterisation in biomedical research.
DSORT-MCU: Detecting Small Objects in Real-Time on Microcontroller Units
Oct 22, 2024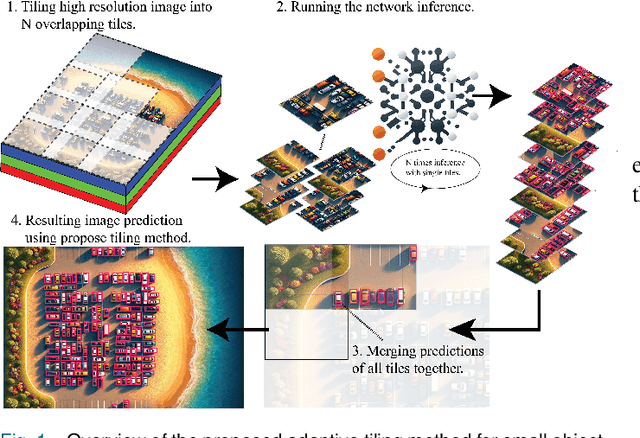
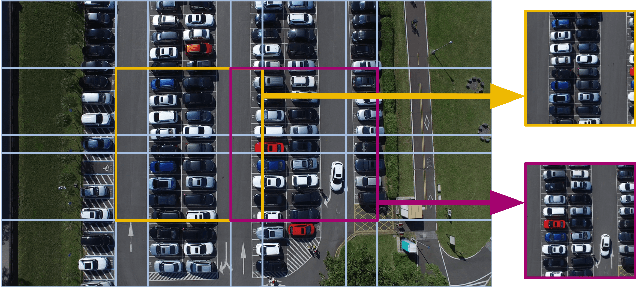

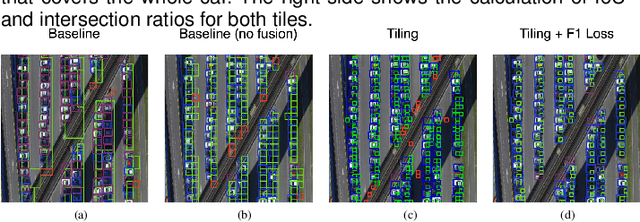
Advances in lightweight neural networks have revolutionized computer vision in a broad range of IoT applications, encompassing remote monitoring and process automation. However, the detection of small objects, which is crucial for many of these applications, remains an underexplored area in current computer vision research, particularly for low-power embedded devices that host resource-constrained processors. To address said gap, this paper proposes an adaptive tiling method for lightweight and energy-efficient object detection networks, including YOLO-based models and the popular FOMO network. The proposed tiling enables object detection on low-power MCUs with no compromise on accuracy compared to large-scale detection models. The benefit of the proposed method is demonstrated by applying it to FOMO and TinyissimoYOLO networks on a novel RISC-V-based MCU with built-in ML accelerators. Extensive experimental results show that the proposed tiling method boosts the F1-score by up to 225% for both FOMO and TinyissimoYOLO networks while reducing the average object count error by up to 76% with FOMO and up to 89% for TinyissimoYOLO. Furthermore, the findings of this work indicate that using a soft F1 loss over the popular binary cross-entropy loss can serve as an implicit non-maximum suppression for the FOMO network. To evaluate the real-world performance, the networks are deployed on the RISC-V based GAP9 microcontroller from GreenWaves Technologies, showcasing the proposed method's ability to strike a balance between detection performance ($58% - 95%$ F1 score), low latency (0.6 ms/Inference - 16.2 ms/Inference}), and energy efficiency (31 uJ/Inference} - 1.27 mJ/Inference) while performing multiple predictions using high-resolution images on a MCU.
Q-Segment: Segmenting Images In-Sensor for Vessel-Based Medical Diagnosis
Dec 22, 2023This paper addresses the growing interest in deploying deep learning models directly in-sensor. We present "Q-Segment", a quantized real-time segmentation algorithm, and conduct a comprehensive evaluation on a low-power edge vision platform with an in-sensors processor, the Sony IMX500. One of the main goals of the model is to achieve end-to-end image segmentation for vessel-based medical diagnosis. Deployed on the IMX500 platform, Q-Segment achieves ultra-low inference time in-sensor only 0.23 ms and power consumption of only 72mW. We compare the proposed network with state-of-the-art models, both float and quantized, demonstrating that the proposed solution outperforms existing networks on various platforms in computing efficiency, e.g., by a factor of 75x compared to ERFNet. The network employs an encoder-decoder structure with skip connections, and results in a binary accuracy of 97.25% and an Area Under the Receiver Operating Characteristic Curve (AUC) of 96.97% on the CHASE dataset. We also present a comparison of the IMX500 processing core with the Sony Spresense, a low-power multi-core ARM Cortex-M microcontroller, and a single-core ARM Cortex-M4 showing that it can achieve in-sensor processing with end-to-end low latency (17 ms) and power concumption (254mW). This research contributes valuable insights into edge-based image segmentation, laying the foundation for efficient algorithms tailored to low-power environments.
Ultra-Efficient On-Device Object Detection on AI-Integrated Smart Glasses with TinyissimoYOLO
Nov 03, 2023



Smart glasses are rapidly gaining advanced functionality thanks to cutting-edge computing technologies, accelerated hardware architectures, and tiny AI algorithms. Integrating AI into smart glasses featuring a small form factor and limited battery capacity is still challenging when targeting full-day usage for a satisfactory user experience. This paper illustrates the design and implementation of tiny machine-learning algorithms exploiting novel low-power processors to enable prolonged continuous operation in smart glasses. We explore the energy- and latency-efficient of smart glasses in the case of real-time object detection. To this goal, we designed a smart glasses prototype as a research platform featuring two microcontrollers, including a novel milliwatt-power RISC-V parallel processor with a hardware accelerator for visual AI, and a Bluetooth low-power module for communication. The smart glasses integrate power cycling mechanisms, including image and audio sensing interfaces. Furthermore, we developed a family of novel tiny deep-learning models based on YOLO with sub-million parameters customized for microcontroller-based inference dubbed TinyissimoYOLO v1.3, v5, and v8, aiming at benchmarking object detection with smart glasses for energy and latency. Evaluations on the prototype of the smart glasses demonstrate TinyissimoYOLO's 17ms inference latency and 1.59mJ energy consumption per inference while ensuring acceptable detection accuracy. Further evaluation reveals an end-to-end latency from image capturing to the algorithm's prediction of 56ms or equivalently 18 fps, with a total power consumption of 62.9mW, equivalent to a 9.3 hours of continuous run time on a 154mAh battery. These results outperform MCUNet (TinyNAS+TinyEngine), which runs a simpler task (image classification) at just 7.3 fps per second.
Quantitative Evaluation of a Multi-Modal Camera Setup for Fusing Event Data with RGB Images
Nov 03, 2023
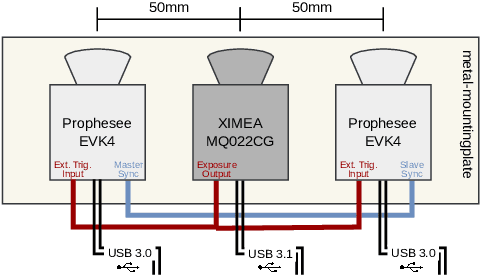
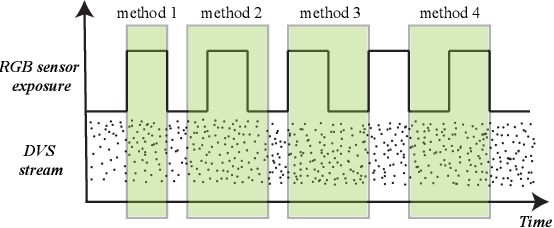
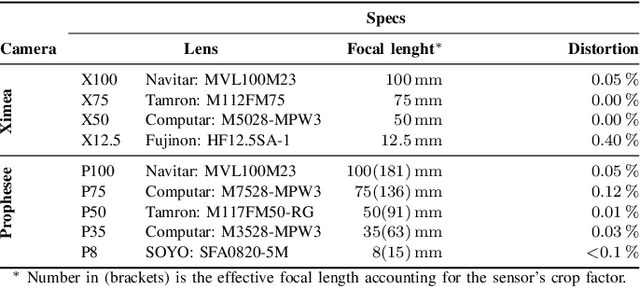
Event-based cameras, also called silicon retinas, potentially revolutionize computer vision by detecting and reporting significant changes in intensity asynchronous events, offering extended dynamic range, low latency, and low power consumption, enabling a wide range of applications from autonomous driving to longtime surveillance. As an emerging technology, there is a notable scarcity of publicly available datasets for event-based systems that also feature frame-based cameras, in order to exploit the benefits of both technologies. This work quantitatively evaluates a multi-modal camera setup for fusing high-resolution DVS data with RGB image data by static camera alignment. The proposed setup, which is intended for semi-automatic DVS data labeling, combines two recently released Prophesee EVK4 DVS cameras and one global shutter XIMEA MQ022CG-CM RGB camera. After alignment, state-of-the-art object detection or segmentation networks label the image data by mapping boundary boxes or labeled pixels directly to the aligned events. To facilitate this process, various time-based synchronization methods for DVS data are analyzed, and calibration accuracy, camera alignment, and lens impact are evaluated. Experimental results demonstrate the benefits of the proposed system: the best synchronization method yields an image calibration error of less than 0.90px and a pixel cross-correlation deviation of1.6px, while a lens with 8mm focal length enables detection of objects with size 30cm at a distance of 350m against homogeneous background.
Flexible and Fully Quantized Ultra-Lightweight TinyissimoYOLO for Ultra-Low-Power Edge Systems
Jul 14, 2023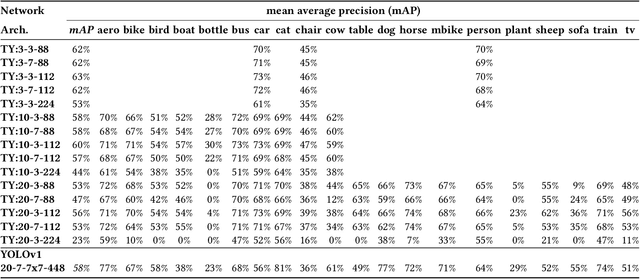
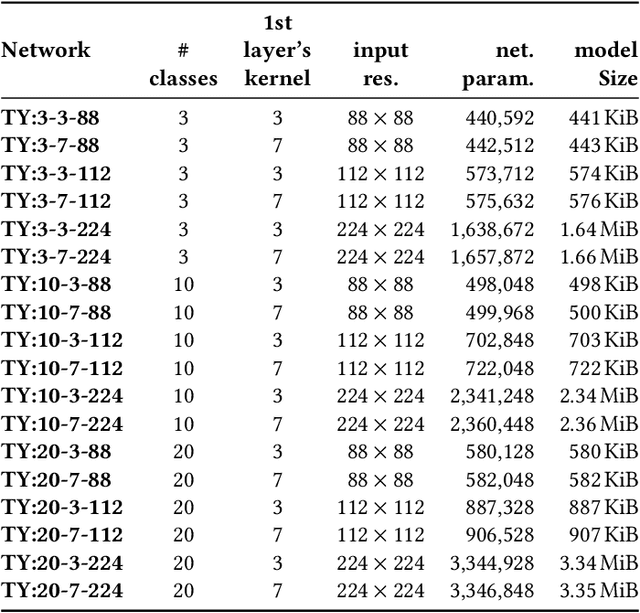

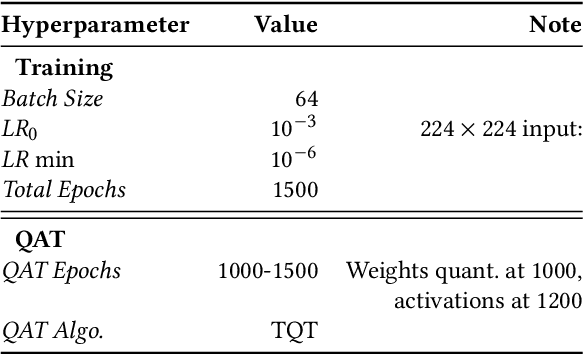
This paper deploys and explores variants of TinyissimoYOLO, a highly flexible and fully quantized ultra-lightweight object detection network designed for edge systems with a power envelope of a few milliwatts. With experimental measurements, we present a comprehensive characterization of the network's detection performance, exploring the impact of various parameters, including input resolution, number of object classes, and hidden layer adjustments. We deploy variants of TinyissimoYOLO on state-of-the-art ultra-low-power extreme edge platforms, presenting an in-depth a comparison on latency, energy efficiency, and their ability to efficiently parallelize the workload. In particular, the paper presents a comparison between a novel parallel RISC-V processor (GAP9 from Greenwaves) with and without use of its on-chip hardware accelerator, an ARM Cortex-M7 core (STM32H7 from ST Microelectronics), two ARM Cortex-M4 cores (STM32L4 from STM and Apollo4b from Ambiq), and a multi-core platform with a CNN hardware accelerator (Analog Devices MAX78000). Experimental results show that the GAP9's hardware accelerator achieves the lowest inference latency and energy at 2.12ms and 150uJ respectively, which is around 2x faster and 20% more efficient than the next best platform, the MAX78000. The hardware accelerator of GAP9 can even run an increased resolution version of TinyissimoYOLO with 112x112 pixels and 10 detection classes within 3.2ms, consuming 245uJ. To showcase the competitiveness of a versatile general-purpose system we also deployed and profiled a multi-core implementation on GAP9 at different operating points, achieving 11.3ms with the lowest-latency and 490uJ with the most energy-efficient configuration. With this paper, we demonstrate the suitability and flexibility of TinyissimoYOLO on state-of-the-art detection datasets for real-time ultra-low-power edge inference.