 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyGLASS: Real-Time Self-Supervised In-Sensor Anomaly Detection
Mar 17, 2026Anomaly detection plays a key role in industrial quality control, where defects must be identified despite the scarcity of labeled faulty samples. Recent self-supervised approaches, such as GLASS, learn normal visual patterns using only defect-free data and have shown strong performance on industrial benchmarks. However, their computational requirements limit deployment on resource-constrained edge platforms. This work introduces TinyGLASS, a lightweight adaptation of the GLASS framework designed for real-time in-sensor anomaly detection on the Sony IMX500 intelligent vision sensor. The proposed architecture replaces the original WideResNet-50 backbone with a compact ResNet-18 and introduces deployment-oriented modifications that enable static graph tracing and INT8 quantization using Sony's Model Compression Toolkit. In addition to evaluating performance on the MVTec-AD benchmark, we investigate robustness to contaminated training data and introduce a custom industrial dataset, named MMS Dataset, for cross-device evaluation. Experimental results show that TinyGLASS achieves 8.7x parameter compression while maintaining competitive detection performance, reaching 94.2% image-level AUROC on MVTec-AD and operating at 20 FPS within the 8 MB memory constraints of the IMX500 platform. System profiling demonstrates low power consumption (4.0 mJ per inference), real-time end-to-end latency (20 FPS), and high energy efficiency (470 GMAC/J). Furthermore, the model maintains stable performance under moderate levels of training data contamination.
PicoSAM3: Real-Time In-Sensor Region-of-Interest Segmentation
Mar 12, 2026Real-time, on-device segmentation is critical for latency-sensitive and privacy-aware applications such as smart glasses and Internet-of-Things devices. We introduce PicoSAM3, a lightweight promptable visual segmentation model optimized for edge and in-sensor execution, including deployment on the Sony IMX500 vision sensor. PicoSAM3 has 1.3 M parameters and combines a dense CNN architecture with region of interest prompt encoding, Efficient Channel Attention, and knowledge distillation from SAM2 and SAM3. On COCO and LVIS, PicoSAM3 achieves 65.45% and 64.01% mIoU, respectively, outperforming existing SAM-based and edge-oriented baselines at similar or lower complexity. The INT8 quantized model preserves accuracy with negligible degradation while enabling real-time in-sensor inference at 11.82 ms latency on the IMX500, fully complying with its memory and operator constraints. Ablation studies show that distillation from large SAM models yields up to +14.5% mIoU improvement over supervised training and demonstrate that high-quality, spatially flexible promptable segmentation is feasible directly at the sensor level.
PicoSAM2: Low-Latency Segmentation In-Sensor for Edge Vision Applications
Jun 24, 2025Real-time, on-device segmentation is critical for latency-sensitive and privacy-aware applications like smart glasses and IoT devices. We introduce PicoSAM2, a lightweight (1.3M parameters, 336M MACs) promptable segmentation model optimized for edge and in-sensor execution, including the Sony IMX500. It builds on a depthwise separable U-Net, with knowledge distillation and fixed-point prompt encoding to learn from the Segment Anything Model 2 (SAM2). On COCO and LVIS, it achieves 51.9% and 44.9% mIoU, respectively. The quantized model (1.22MB) runs at 14.3 ms on the IMX500-achieving 86 MACs/cycle, making it the only model meeting both memory and compute constraints for in-sensor deployment. Distillation boosts LVIS performance by +3.5% mIoU and +5.1% mAP. These results demonstrate that efficient, promptable segmentation is feasible directly on-camera, enabling privacy-preserving vision without cloud or host processing.
RGB-Event Fusion with Self-Attention for Collision Prediction
May 07, 2025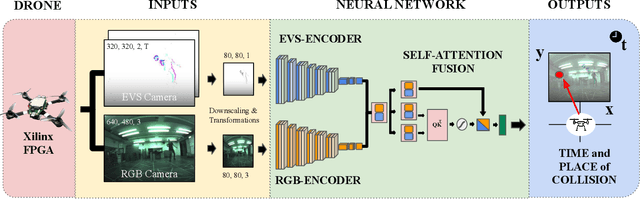
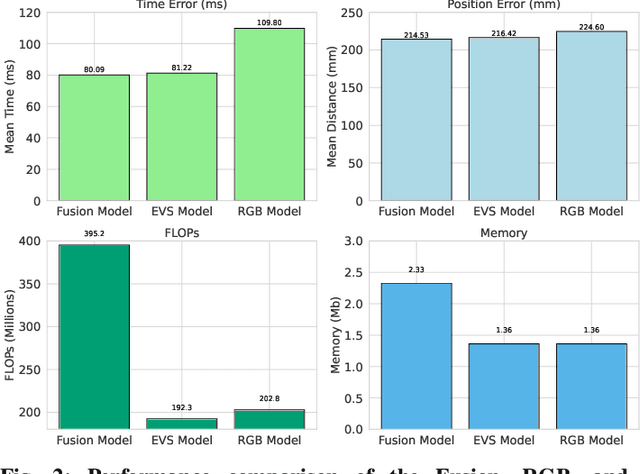
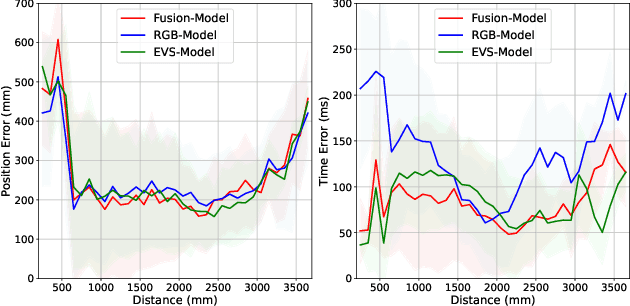
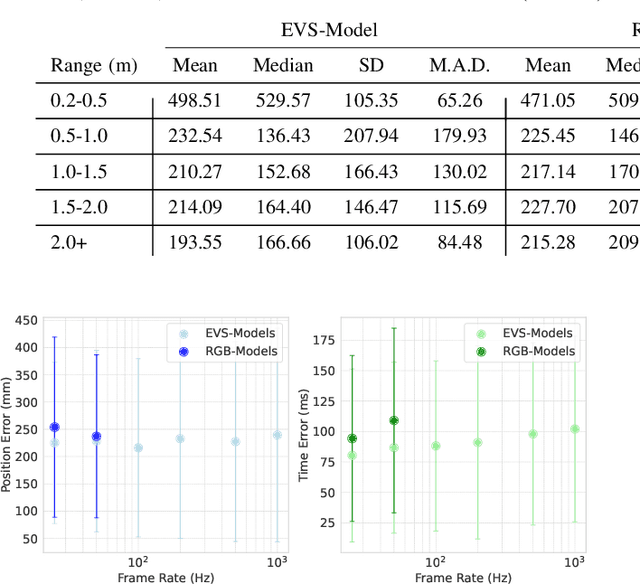
Ensuring robust and real-time obstacle avoidance is critical for the safe operation of autonomous robots in dynamic, real-world environments. This paper proposes a neural network framework for predicting the time and collision position of an unmanned aerial vehicle with a dynamic object, using RGB and event-based vision sensors. The proposed architecture consists of two separate encoder branches, one for each modality, followed by fusion by self-attention to improve prediction accuracy. To facilitate benchmarking, we leverage the ABCD [8] dataset collected that enables detailed comparisons of single-modality and fusion-based approaches. At the same prediction throughput of 50Hz, the experimental results show that the fusion-based model offers an improvement in prediction accuracy over single-modality approaches of 1% on average and 10% for distances beyond 0.5m, but comes at the cost of +71% in memory and + 105% in FLOPs. Notably, the event-based model outperforms the RGB model by 4% for position and 26% for time error at a similar computational cost, making it a competitive alternative. Additionally, we evaluate quantized versions of the event-based models, applying 1- to 8-bit quantization to assess the trade-offs between predictive performance and computational efficiency. These findings highlight the trade-offs of multi-modal perception using RGB and event-based cameras in robotic applications.
Towards Low-Latency Event-based Obstacle Avoidance on a FPGA-Drone
Apr 14, 2025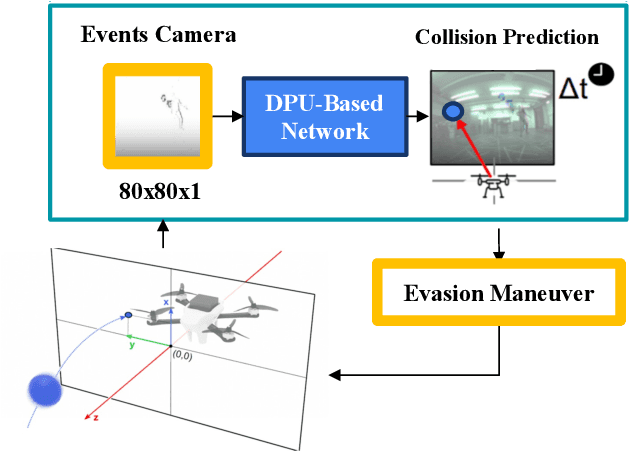
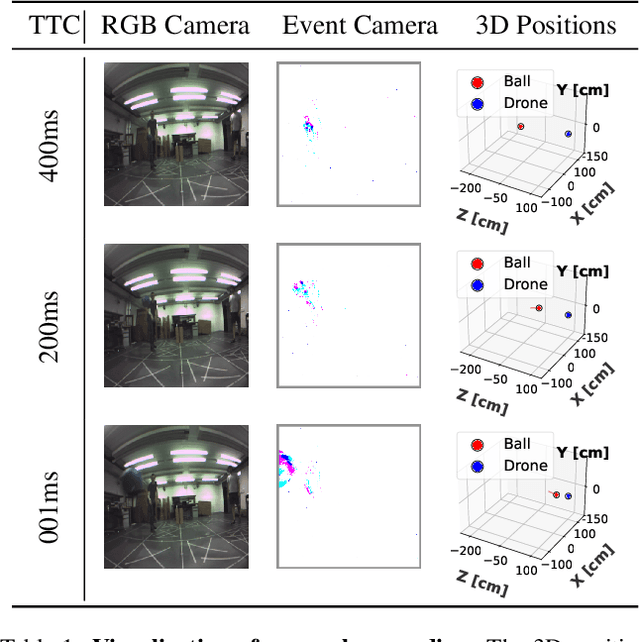
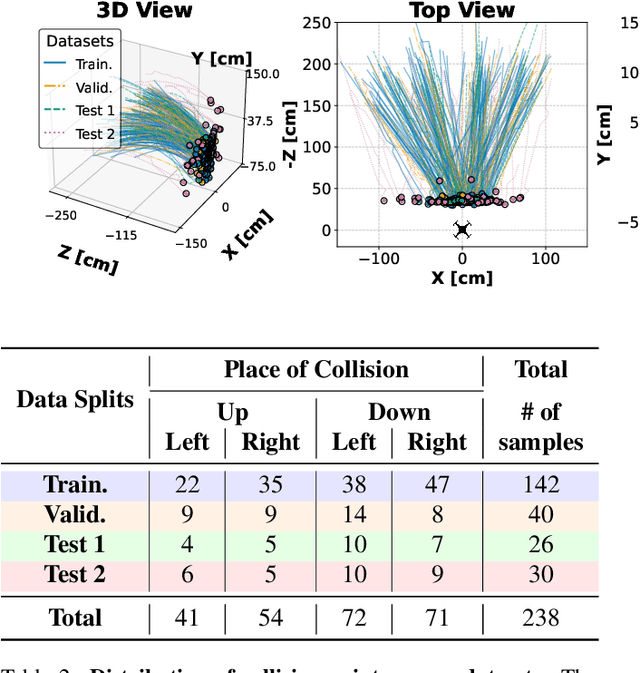
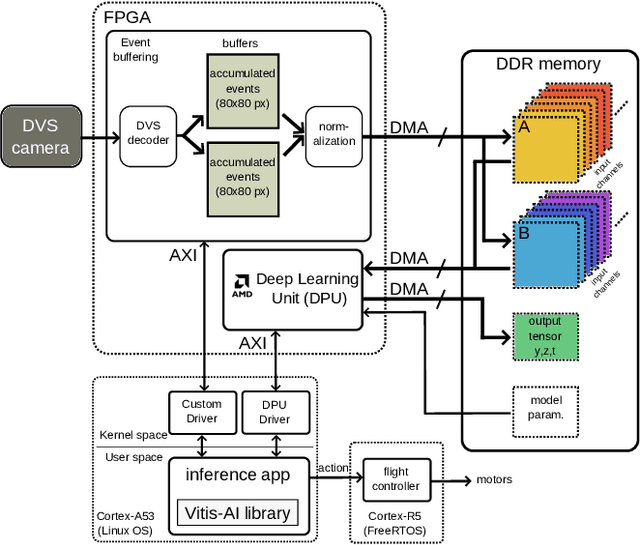
This work quantitatively evaluates the performance of event-based vision systems (EVS) against conventional RGB-based models for action prediction in collision avoidance on an FPGA accelerator. Our experiments demonstrate that the EVS model achieves a significantly higher effective frame rate (1 kHz) and lower temporal (-20 ms) and spatial prediction errors (-20 mm) compared to the RGB-based model, particularly when tested on out-of-distribution data. The EVS model also exhibits superior robustness in selecting optimal evasion maneuvers. In particular, in distinguishing between movement and stationary states, it achieves a 59 percentage point advantage in precision (78% vs. 19%) and a substantially higher F1 score (0.73 vs. 0.06), highlighting the susceptibility of the RGB model to overfitting. Further analysis in different combinations of spatial classes confirms the consistent performance of the EVS model in both test data sets. Finally, we evaluated the system end-to-end and achieved a latency of approximately 2.14 ms, with event aggregation (1 ms) and inference on the processing unit (0.94 ms) accounting for the largest components. These results underscore the advantages of event-based vision for real-time collision avoidance and demonstrate its potential for deployment in resource-constrained environments.
Few-shot point cloud reconstruction and denoising via learned Guassian splats renderings and fine-tuned diffusion features
Apr 04, 2024Existing deep learning methods for the reconstruction and denoising of point clouds rely on small datasets of 3D shapes. We circumvent the problem by leveraging deep learning methods trained on billions of images. We propose a method to reconstruct point clouds from few images and to denoise point clouds from their rendering by exploiting prior knowledge distilled from image-based deep learning models. To improve reconstruction in constraint settings, we regularize the training of a differentiable renderer with hybrid surface and appearance by introducing semantic consistency supervision. In addition, we propose a pipeline to finetune Stable Diffusion to denoise renderings of noisy point clouds and we demonstrate how these learned filters can be used to remove point cloud noise coming without 3D supervision. We compare our method with DSS and PointRadiance and achieved higher quality 3D reconstruction on the Sketchfab Testset and SCUT Dataset.
3D scene generation from scene graphs and self-attention
Apr 04, 2024Synthesizing realistic and diverse indoor 3D scene layouts in a controllable fashion opens up applications in simulated navigation and virtual reality. As concise and robust representations of a scene, scene graphs have proven to be well-suited as the semantic control on the generated layout. We present a variant of the conditional variational autoencoder (cVAE) model to synthesize 3D scenes from scene graphs and floor plans. We exploit the properties of self-attention layers to capture high-level relationships between objects in a scene, and use these as the building blocks of our model. Our model, leverages graph transformers to estimate the size, dimension and orientation of the objects in a room while satisfying relationships in the given scene graph. Our experiments shows self-attention layers leads to sparser (7.9x compared to Graphto3D) and more diverse scenes (16%).
Q-Segment: Segmenting Images In-Sensor for Vessel-Based Medical Diagnosis
Dec 22, 2023This paper addresses the growing interest in deploying deep learning models directly in-sensor. We present "Q-Segment", a quantized real-time segmentation algorithm, and conduct a comprehensive evaluation on a low-power edge vision platform with an in-sensors processor, the Sony IMX500. One of the main goals of the model is to achieve end-to-end image segmentation for vessel-based medical diagnosis. Deployed on the IMX500 platform, Q-Segment achieves ultra-low inference time in-sensor only 0.23 ms and power consumption of only 72mW. We compare the proposed network with state-of-the-art models, both float and quantized, demonstrating that the proposed solution outperforms existing networks on various platforms in computing efficiency, e.g., by a factor of 75x compared to ERFNet. The network employs an encoder-decoder structure with skip connections, and results in a binary accuracy of 97.25% and an Area Under the Receiver Operating Characteristic Curve (AUC) of 96.97% on the CHASE dataset. We also present a comparison of the IMX500 processing core with the Sony Spresense, a low-power multi-core ARM Cortex-M microcontroller, and a single-core ARM Cortex-M4 showing that it can achieve in-sensor processing with end-to-end low latency (17 ms) and power concumption (254mW). This research contributes valuable insights into edge-based image segmentation, laying the foundation for efficient algorithms tailored to low-power environments.
A Low-Power Neuromorphic Approach for Efficient Eye-Tracking
Dec 01, 2023


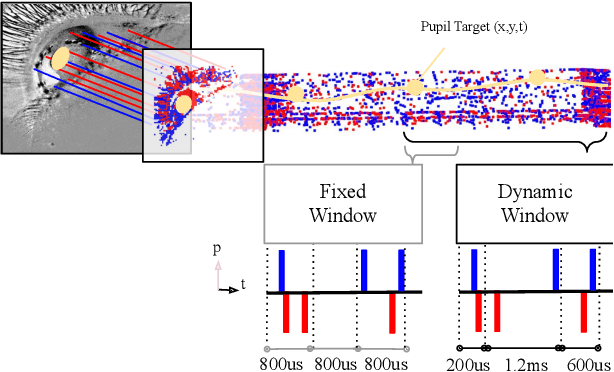
This paper introduces a neuromorphic methodology for eye tracking, harnessing pure event data captured by a Dynamic Vision Sensor (DVS) camera. The framework integrates a directly trained Spiking Neuron Network (SNN) regression model and leverages a state-of-the-art low power edge neuromorphic processor - Speck, collectively aiming to advance the precision and efficiency of eye-tracking systems. First, we introduce a representative event-based eye-tracking dataset, "Ini-30", which was collected with two glass-mounted DVS cameras from thirty volunteers. Then,a SNN model, based on Integrate And Fire (IAF) neurons, named "Retina", is described , featuring only 64k parameters (6.63x fewer than the latest) and achieving pupil tracking error of only 3.24 pixels in a 64x64 DVS input. The continous regression output is obtained by means of convolution using a non-spiking temporal 1D filter slided across the output spiking layer. Finally, we evaluate Retina on the neuromorphic processor, showing an end-to-end power between 2.89-4.8 mW and a latency of 5.57-8.01 mS dependent on the time window. We also benchmark our model against the latest event-based eye-tracking method, "3ET", which was built upon event frames. Results show that Retina achieves superior precision with 1.24px less pupil centroid error and reduced computational complexity with 35 times fewer MAC operations. We hope this work will open avenues for further investigation of close-loop neuromorphic solutions and true event-based training pursuing edge performance.
Ultra-Efficient On-Device Object Detection on AI-Integrated Smart Glasses with TinyissimoYOLO
Nov 03, 2023



Smart glasses are rapidly gaining advanced functionality thanks to cutting-edge computing technologies, accelerated hardware architectures, and tiny AI algorithms. Integrating AI into smart glasses featuring a small form factor and limited battery capacity is still challenging when targeting full-day usage for a satisfactory user experience. This paper illustrates the design and implementation of tiny machine-learning algorithms exploiting novel low-power processors to enable prolonged continuous operation in smart glasses. We explore the energy- and latency-efficient of smart glasses in the case of real-time object detection. To this goal, we designed a smart glasses prototype as a research platform featuring two microcontrollers, including a novel milliwatt-power RISC-V parallel processor with a hardware accelerator for visual AI, and a Bluetooth low-power module for communication. The smart glasses integrate power cycling mechanisms, including image and audio sensing interfaces. Furthermore, we developed a family of novel tiny deep-learning models based on YOLO with sub-million parameters customized for microcontroller-based inference dubbed TinyissimoYOLO v1.3, v5, and v8, aiming at benchmarking object detection with smart glasses for energy and latency. Evaluations on the prototype of the smart glasses demonstrate TinyissimoYOLO's 17ms inference latency and 1.59mJ energy consumption per inference while ensuring acceptable detection accuracy. Further evaluation reveals an end-to-end latency from image capturing to the algorithm's prediction of 56ms or equivalently 18 fps, with a total power consumption of 62.9mW, equivalent to a 9.3 hours of continuous run time on a 154mAh battery. These results outperform MCUNet (TinyNAS+TinyEngine), which runs a simpler task (image classification) at just 7.3 fps per second.