 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEBPC: Extended Bit-Plane Compression for Deep Neural Network Inference and Training Accelerators
Paper and Code

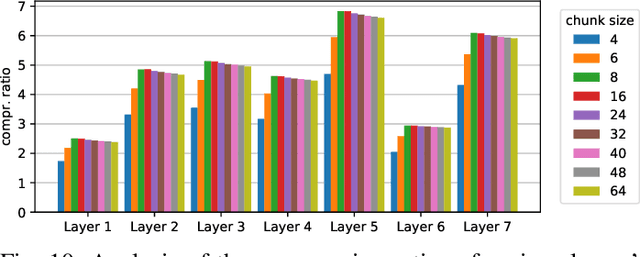
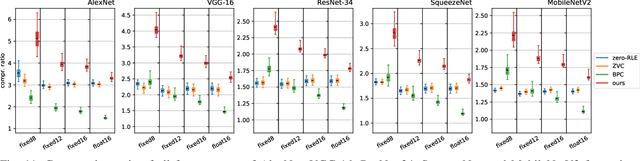
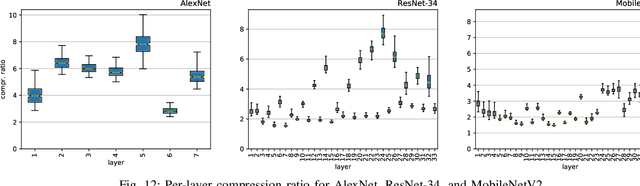
In the wake of the success of convolutional neural networks in image classification, object recognition, speech recognition, etc., the demand for deploying these compute-intensive ML models on embedded and mobile systems with tight power and energy constraints at low cost, as well as for boosting throughput in data centers, is growing rapidly. This has sparked a surge of research into specialized hardware accelerators. Their performance is typically limited by I/O bandwidth, power consumption is dominated by I/O transfers to off-chip memory, and on-chip memories occupy a large part of the silicon area. We introduce and evaluate a novel, hardware-friendly and lossless compression scheme for the feature maps present within convolutional neural networks. Its hardware implementation fits into 2.8 kGE and 1.7 kGE of silicon area for the compressor and decompressor, respectively. We show that an average compression ratio of 5.1x for AlexNet, 4x for VGG-16, 2.4x for ResNet-34 and 2.2x for MobileNetV2 can be achieved---a gain of 45--70% over existing methods. Our approach also works effectively for various number formats, has a low frame-to-frame variance on the compression ratio, and achieves compression factors for gradient map compression during training that are even better than for inference.