 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarsellus: A Heterogeneous RISC-V AI-IoT End-Node SoC with 2-to-8b DNN Acceleration and 30%-Boost Adaptive Body Biasing
May 15, 2023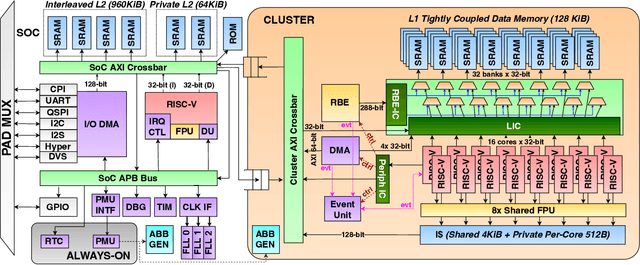
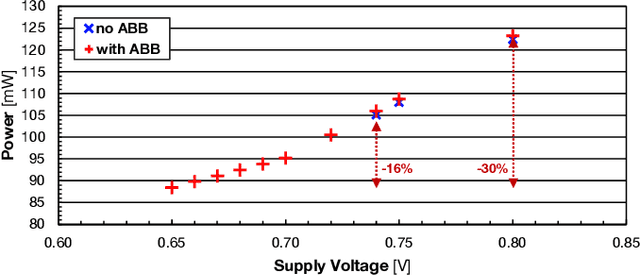
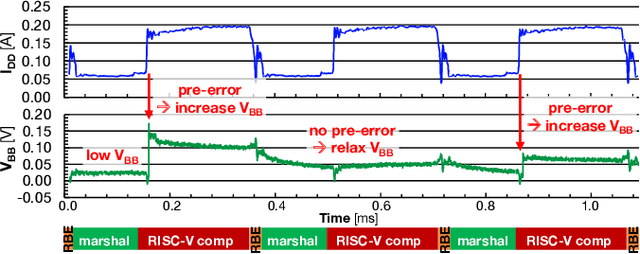
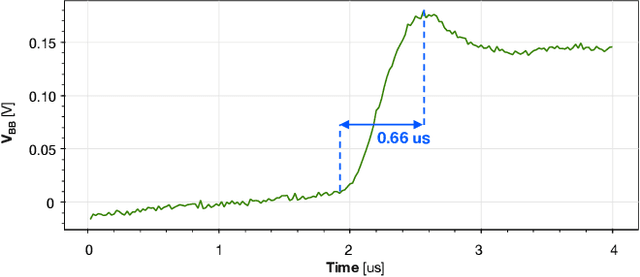
Emerging Artificial Intelligence-enabled Internet-of-Things (AI-IoT) System-on-a-Chip (SoC) for augmented reality, personalized healthcare, and nano-robotics need to run many diverse tasks within a power envelope of a few tens of mW over a wide range of operating conditions: compute-intensive but strongly quantized Deep Neural Network (DNN) inference, as well as signal processing and control requiring high-precision floating-point. We present Marsellus, an all-digital heterogeneous SoC for AI-IoT end-nodes fabricated in GlobalFoundries 22nm FDX that combines 1) a general-purpose cluster of 16 RISC-V Digital Signal Processing (DSP) cores attuned for the execution of a diverse range of workloads exploiting 4-bit and 2-bit arithmetic extensions (XpulpNN), combined with fused MAC&LOAD operations and floating-point support; 2) a 2-8bit Reconfigurable Binary Engine (RBE) to accelerate 3x3 and 1x1 (pointwise) convolutions in DNNs; 3) a set of On-Chip Monitoring (OCM) blocks connected to an Adaptive Body Biasing (ABB) generator and a hardware control loop, enabling on-the-fly adaptation of transistor threshold voltages. Marsellus achieves up to 180 Gop/s or 3.32 Top/s/W on 2-bit precision arithmetic in software, and up to 637 Gop/s or 12.4 Top/s/W on hardware-accelerated DNN layers.
Non-invasive urinary bladder volume estimation with artefact-suppressed bio-impedance measurements
Mar 24, 2023



Urine output is a vital parameter to gauge kidney health. Current monitoring methods include manually written records, invasive urinary catheterization or ultrasound measurements performed by highly skilled personnel. Catheterization bears high risks of infection while intermittent ultrasound measures and manual recording are time consuming and might miss early signs of kidney malfunction. Bioimpedance (BI) measurements may serve as a non-invasive alternative for measuring urine volume in vivo. However, limited robustness have prevented its clinical translation. Here, a deep learning-based algorithm is presented that processes the local BI of the lower abdomen and suppresses artefacts to measure the bladder volume quantitatively, non-invasively and without the continuous need for additional personnel. A tetrapolar BI wearable system called ANUVIS was used to collect continuous bladder volume data from three healthy subjects to demonstrate feasibility of operation, while clinical gold standards of urodynamic (n=6) and uroflowmetry tests (n=8) provided the ground truth. Optimized location for electrode placement and a model for the change in BI with changing bladder volume is deduced. The average error for full bladder volume estimation and for residual volume estimation was -29 +/-87.6 ml, thus, comparable to commercial portable ultrasound devices (Bland Altman analysis showed a bias of -5.2 ml with LoA between 119.7 ml to -130.1 ml), while providing the additional benefit of hands-free, non-invasive, and continuous bladder volume estimation. The combination of the wearable BI sensor node and the presented algorithm provides an attractive alternative to current standard of care with potential benefits in providing insights into kidney function.
Vega: A 10-Core SoC for IoT End-Nodes with DNN Acceleration and Cognitive Wake-Up From MRAM-Based State-Retentive Sleep Mode
Oct 18, 2021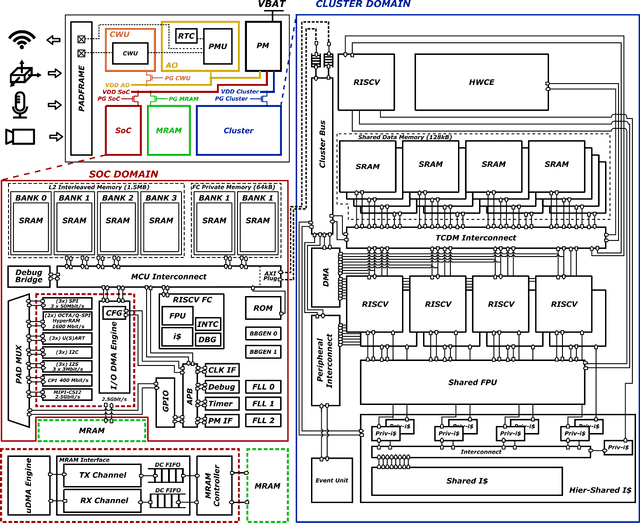
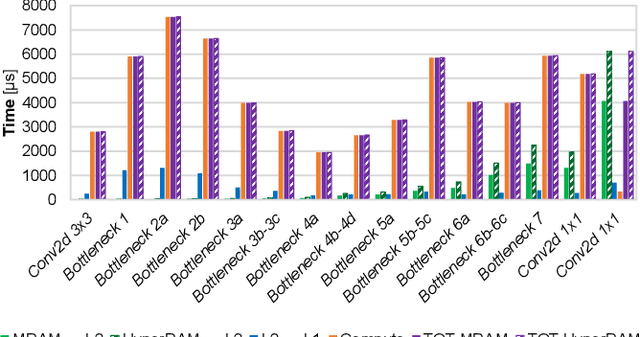
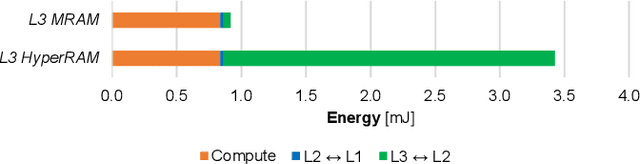
The Internet-of-Things requires end-nodes with ultra-low-power always-on capability for a long battery lifetime, as well as high performance, energy efficiency, and extreme flexibility to deal with complex and fast-evolving near-sensor analytics algorithms (NSAAs). We present Vega, an IoT end-node SoC capable of scaling from a 1.7 $\mathrm{\mu}$W fully retentive cognitive sleep mode up to 32.2 GOPS (@ 49.4 mW) peak performance on NSAAs, including mobile DNN inference, exploiting 1.6 MB of state-retentive SRAM, and 4 MB of non-volatile MRAM. To meet the performance and flexibility requirements of NSAAs, the SoC features 10 RISC-V cores: one core for SoC and IO management and a 9-cores cluster supporting multi-precision SIMD integer and floating-point computation. Vega achieves SoA-leading efficiency of 615 GOPS/W on 8-bit INT computation (boosted to 1.3TOPS/W for 8-bit DNN inference with hardware acceleration). On floating-point (FP) compuation, it achieves SoA-leading efficiency of 79 and 129 GFLOPS/W on 32- and 16-bit FP, respectively. Two programmable machine-learning (ML) accelerators boost energy efficiency in cognitive sleep and active states, respectively.
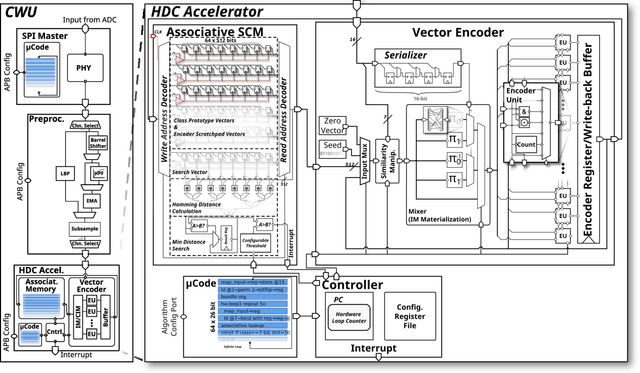
A 5 μW Standard Cell Memory-based Configurable Hyperdimensional Computing Accelerator for Always-on Smart Sensing
Feb 04, 2021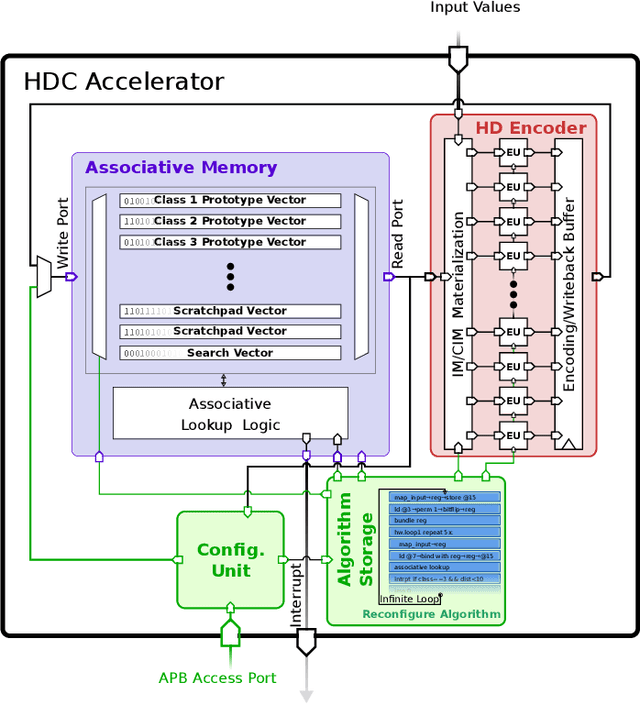
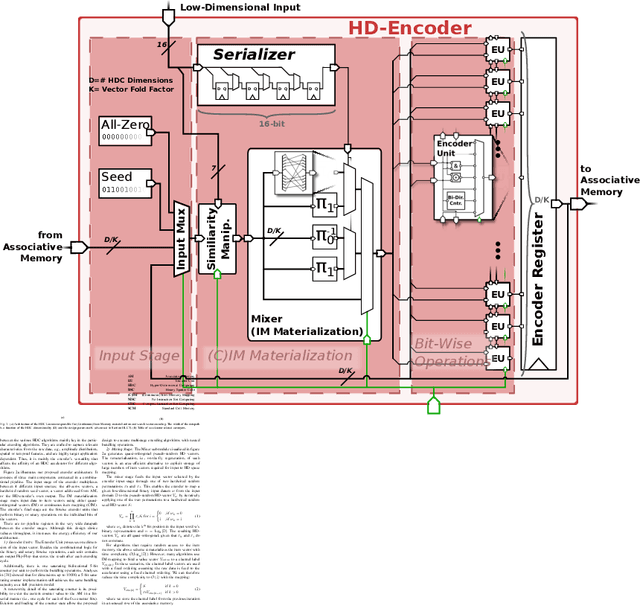
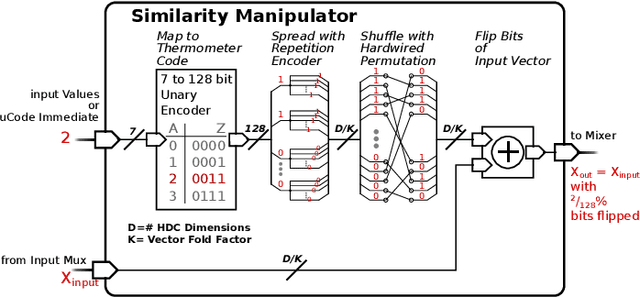
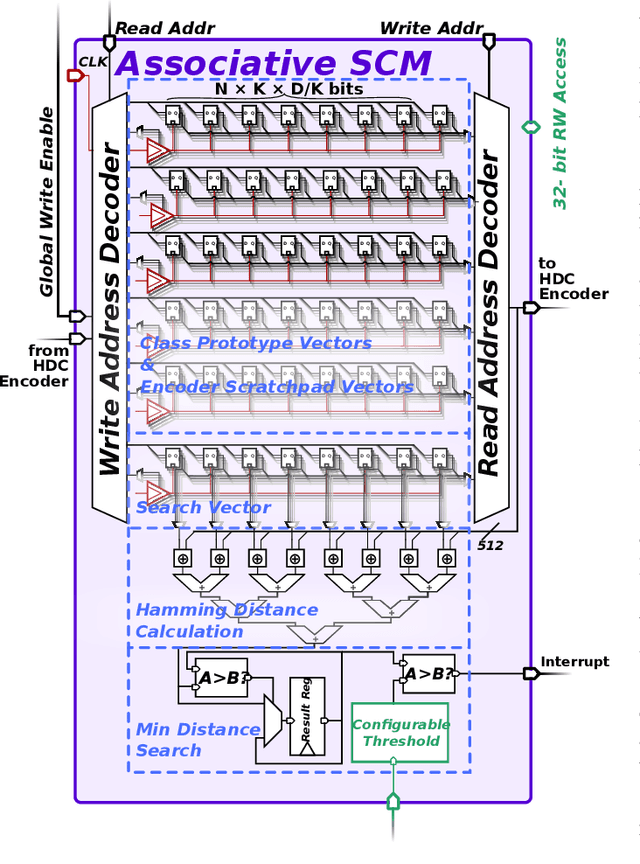
Hyperdimensional computing (HDC) is a brain-inspired computing paradigm based on high-dimensional holistic representations of vectors. It recently gained attention for embedded smart sensing due to its inherent error-resiliency and suitability to highly parallel hardware implementations. In this work, we propose a programmable all-digital CMOS implementation of a fully autonomous HDC accelerator for always-on classification in energy-constrained sensor nodes. By using energy-efficient standard cell memory (SCM), the design is easily cross-technology mappable. It achieves extremely low power, 5 $\mu W$ in typical applications, and an energy-efficiency improvement over the state-of-the-art (SoA) digital architectures of up to 3$\times$ in post-layout simulations for always-on wearable tasks such as EMG gesture recognition. As part of the accelerator's architecture, we introduce novel hardware-friendly embodiments of common HDC-algorithmic primitives, which results in 3.3$\times$ technology scaled area reduction over the SoA, achieving the same accuracy levels in all examined targets. The proposed architecture also has a fully configurable datapath using microcode optimized for HDC stored on an integrated SCM based configuration memory, making the design "general-purpose" in terms of HDC algorithm flexibility. This flexibility allows usage of the accelerator across novel HDC tasks, for instance, a newly designed HDC applied to the task of ball bearing fault detection.
TinyRadarNN: Combining Spatial and Temporal Convolutional Neural Networks for Embedded Gesture Recognition with Short Range Radars
Jun 25, 2020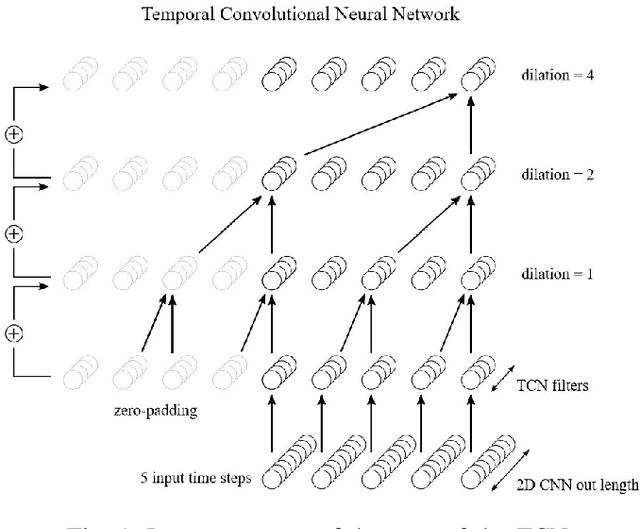
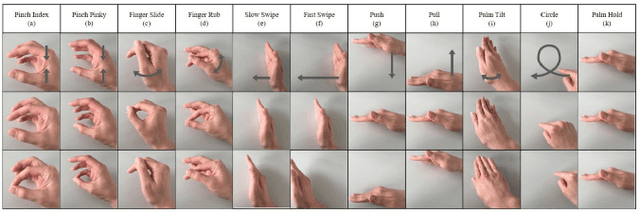
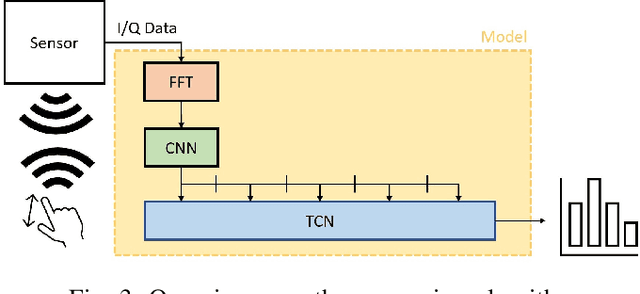
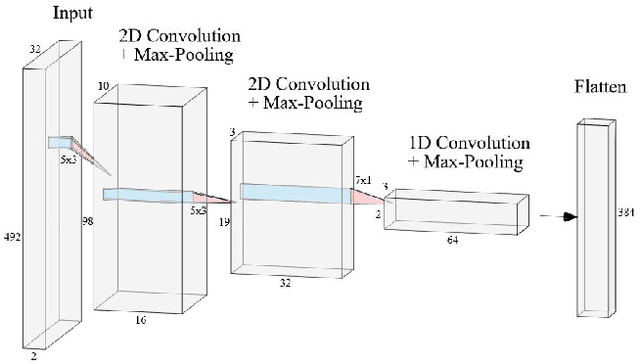
This work proposes a low-power high-accuracy embedded hand-gesture recognition algorithm targeting battery-operated wearable devices using low power short-range RADAR sensors. A 2D Convolutional Neural Network (CNN) using range frequency Doppler features is combined with a Temporal Convolutional Neural Network (TCN) for time sequence prediction. The final algorithm has a model size of only 46 thousand parameters, yielding a memory footprint of only 92 KB. Two datasets containing 11 challenging hand gestures performed by 26 different people have been recorded containing a total of 20,210 gesture instances. On the 11 hand gesture dataset, accuracies of 86.6% (26 users) and 92.4% (single user) have been achieved, which are comparable to the state-of-the-art, which achieves 87% (10 users) and 94% (single user), while using a TCN-based network that is 7500x smaller than the state-of-the-art. Furthermore, the gesture recognition classifier has been implemented on Parallel Ultra-Low Power Processor, demonstrating that real-time prediction is feasible with only 21 mW of power consumption for the full TCN sequence prediction network.
HR-SAR-Net: A Deep Neural Network for Urban Scene Segmentation from High-Resolution SAR Data
Dec 10, 2019
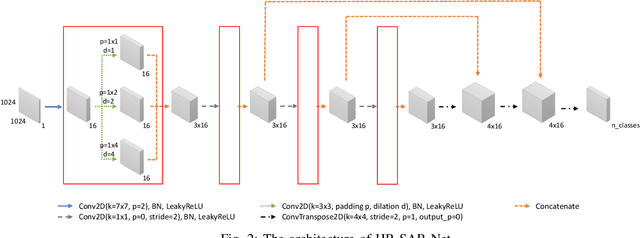

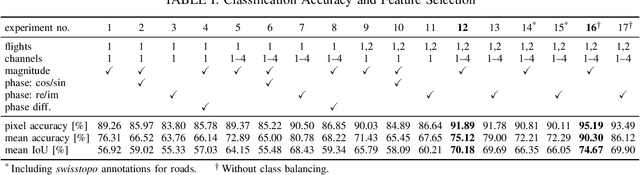
Synthetic aperture radar (SAR) data is becoming increasingly available to a wide range of users through commercial service providers with resolutions reaching 0.5m/px. Segmenting SAR data still requires skilled personnel, limiting the potential for large-scale use. We show that it is possible to automatically and reliably perform urban scene segmentation from next-gen resolution SAR data (0.15m/px) using deep neural networks (DNNs), achieving a pixel accuracy of 95.19% and a mean IoU of 74.67% with data collected over a region of merely 2.2km${}^2$. The presented DNN is not only effective, but is very small with only 63k parameters and computationally simple enough to achieve a throughput of around 500Mpx/s using a single GPU. We further identify that additional SAR receive antennas and data from multiple flights massively improve the segmentation accuracy. We describe a procedure for generating a high-quality segmentation ground truth from multiple inaccurate building and road annotations, which has been crucial to achieving these segmentation results.