 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Downstream Analysis in Genome Sequencing: Species Classification While Basecalling
Apr 09, 2025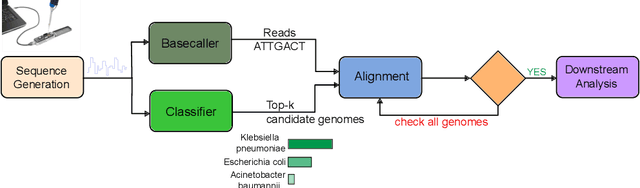

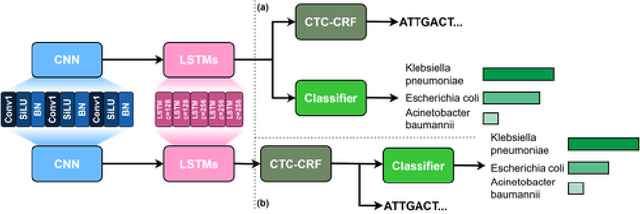
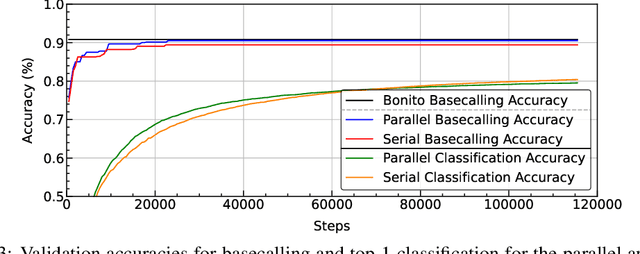
The ability to quickly and accurately identify microbial species in a sample, known as metagenomic profiling, is critical across various fields, from healthcare to environmental science. This paper introduces a novel method to profile signals coming from sequencing devices in parallel with determining their nucleotide sequences, a process known as basecalling, via a multi-objective deep neural network for simultaneous basecalling and multi-class genome classification. We introduce a new loss strategy where losses for basecalling and classification are back-propagated separately, with model weights combined for the shared layers, and a pre-configured ranking strategy allowing top-K species accuracy, giving users flexibility to choose between higher accuracy or higher speed at identifying the species. We achieve state-of-the-art basecalling accuracies, while classification accuracies meet and exceed the results of state-of-the-art binary classifiers, attaining an average of 92.5%/98.9% accuracy at identifying the top-1/3 species among a total of 17 genomes in the Wick bacterial dataset. The work presented here has implications for future studies in metagenomic profiling by accelerating the bottleneck step of matching the DNA sequence to the correct genome.
A Precision-Optimized Fixed-Point Near-Memory Digital Processing Unit for Analog In-Memory Computing
Feb 12, 2024



Analog In-Memory Computing (AIMC) is an emerging technology for fast and energy-efficient Deep Learning (DL) inference. However, a certain amount of digital post-processing is required to deal with circuit mismatches and non-idealities associated with the memory devices. Efficient near-memory digital logic is critical to retain the high area/energy efficiency and low latency of AIMC. Existing systems adopt Floating Point 16 (FP16) arithmetic with limited parallelization capability and high latency. To overcome these limitations, we propose a Near-Memory digital Processing Unit (NMPU) based on fixed-point arithmetic. It achieves competitive accuracy and higher computing throughput than previous approaches while minimizing the area overhead. Moreover, the NMPU supports standard DL activation steps, such as ReLU and Batch Normalization. We perform a physical implementation of the NMPU design in a 14 nm CMOS technology and provide detailed performance, power, and area assessments. We validate the efficacy of the NMPU by using data from an AIMC chip and demonstrate that a simulated AIMC system with the proposed NMPU outperforms existing FP16-based implementations, providing 139$\times$ speed-up, 7.8$\times$ smaller area, and a competitive power consumption. Additionally, our approach achieves an inference accuracy of 86.65 %/65.06 %, with an accuracy drop of just 0.12 %/0.4 % compared to the FP16 baseline when benchmarked with ResNet9/ResNet32 networks trained on the CIFAR10/CIFAR100 datasets, respectively.
AnalogNAS: A Neural Network Design Framework for Accurate Inference with Analog In-Memory Computing
May 17, 2023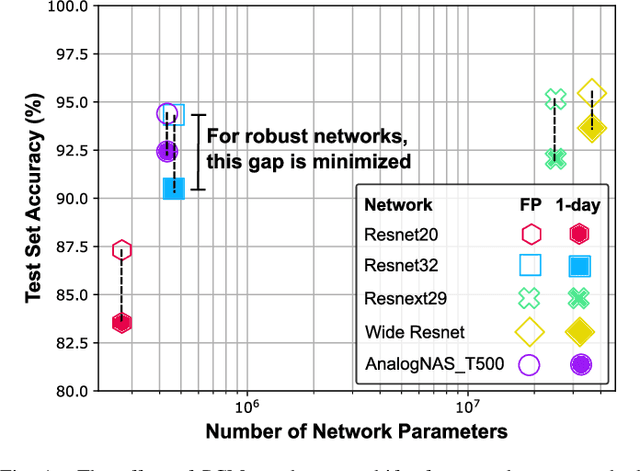
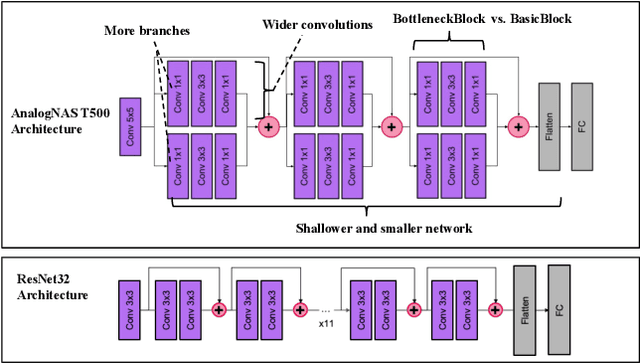
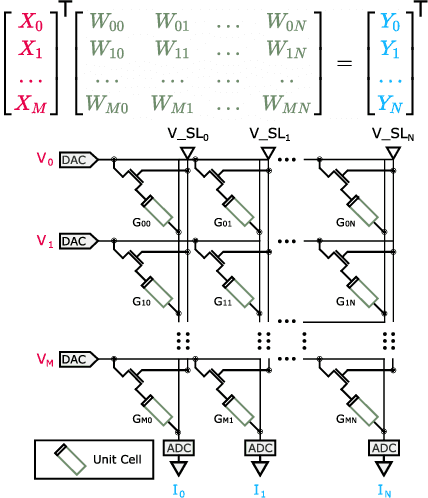
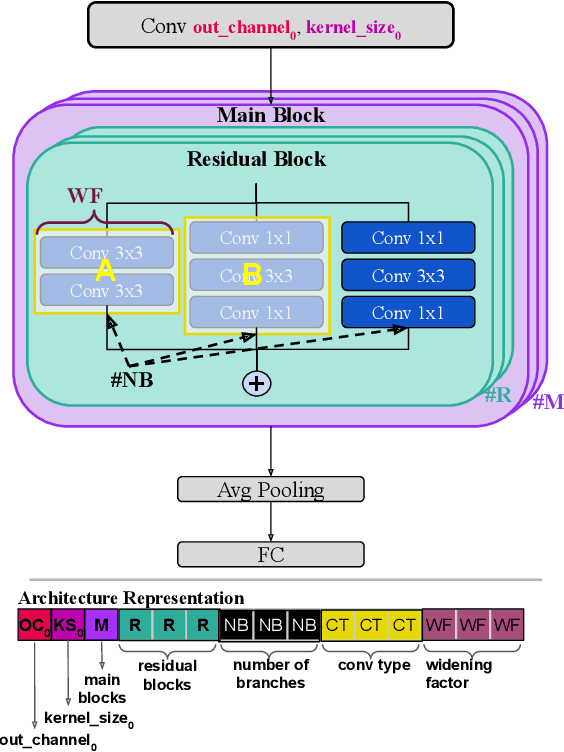
The advancement of Deep Learning (DL) is driven by efficient Deep Neural Network (DNN) design and new hardware accelerators. Current DNN design is primarily tailored for general-purpose use and deployment on commercially viable platforms. Inference at the edge requires low latency, compact and power-efficient models, and must be cost-effective. Digital processors based on typical von Neumann architectures are not conducive to edge AI given the large amounts of required data movement in and out of memory. Conversely, analog/mixed signal in-memory computing hardware accelerators can easily transcend the memory wall of von Neuman architectures when accelerating inference workloads. They offer increased area and power efficiency, which are paramount in edge resource-constrained environments. In this paper, we propose AnalogNAS, a framework for automated DNN design targeting deployment on analog In-Memory Computing (IMC) inference accelerators. We conduct extensive hardware simulations to demonstrate the performance of AnalogNAS on State-Of-The-Art (SOTA) models in terms of accuracy and deployment efficiency on various Tiny Machine Learning (TinyML) tasks. We also present experimental results that show AnalogNAS models achieving higher accuracy than SOTA models when implemented on a 64-core IMC chip based on Phase Change Memory (PCM). The AnalogNAS search code is released: https://github.com/IBM/analog-nas
Benchmarking energy consumption and latency for neuromorphic computing in condensed matter and particle physics
Sep 21, 2022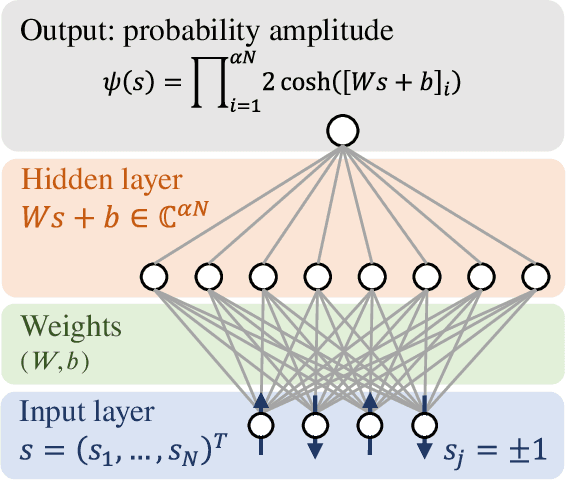
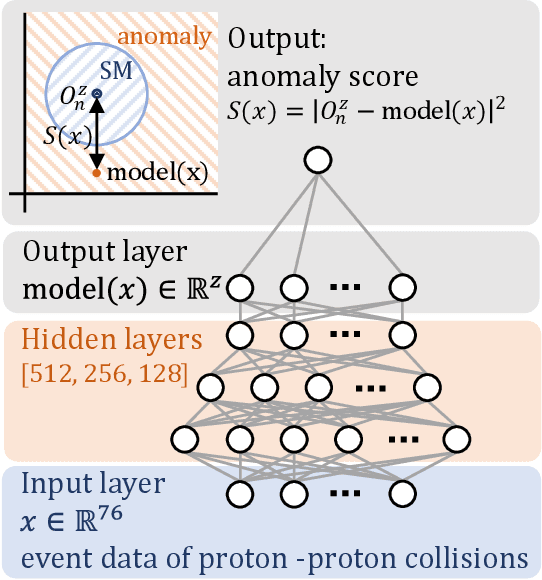
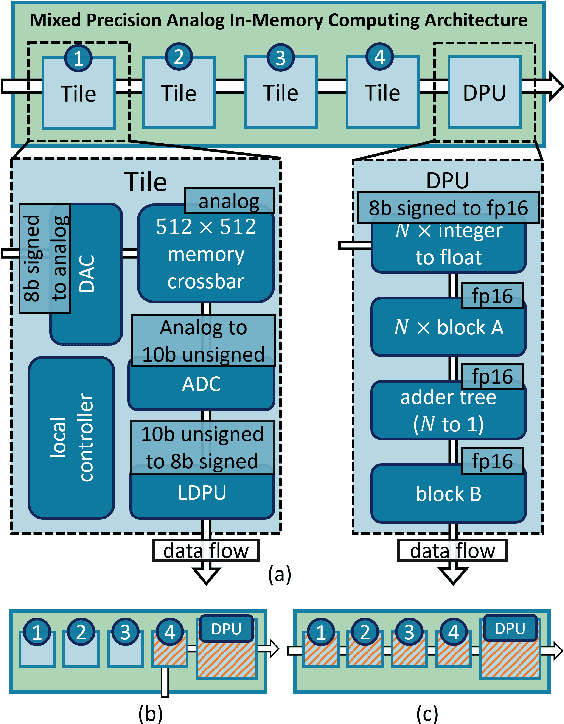
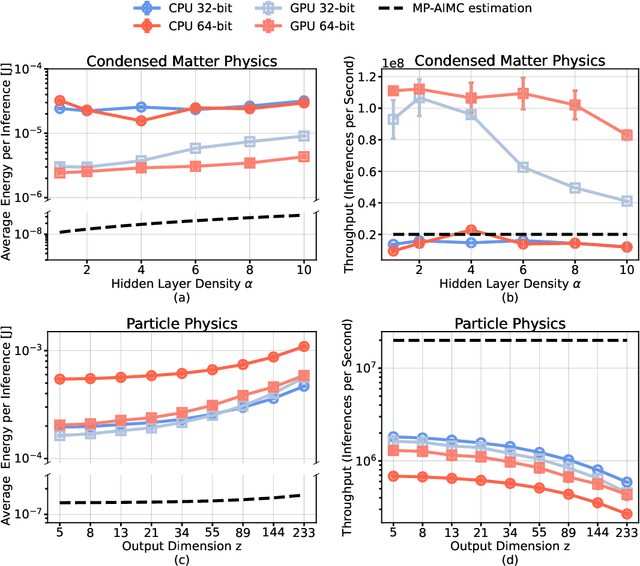
The massive use of artificial neural networks (ANNs), increasingly popular in many areas of scientific computing, rapidly increases the energy consumption of modern high-performance computing systems. An appealing and possibly more sustainable alternative is provided by novel neuromorphic paradigms, which directly implement ANNs in hardware. However, little is known about the actual benefits of running ANNs on neuromorphic hardware for use cases in scientific computing. Here we present a methodology for measuring the energy cost and compute time for inference tasks with ANNs on conventional hardware. In addition, we have designed an architecture for these tasks and estimate the same metrics based on a state-of-the-art analog in-memory computing (AIMC) platform, one of the key paradigms in neuromorphic computing. Both methodologies are compared for a use case in quantum many-body physics in two dimensional condensed matter systems and for anomaly detection at 40 MHz rates at the Large Hadron Collider in particle physics. We find that AIMC can achieve up to one order of magnitude shorter computation times than conventional hardware, at an energy cost that is up to three orders of magnitude smaller. This suggests great potential for faster and more sustainable scientific computing with neuromorphic hardware.
A Heterogeneous In-Memory Computing Cluster For Flexible End-to-End Inference of Real-World Deep Neural Networks
Jan 04, 2022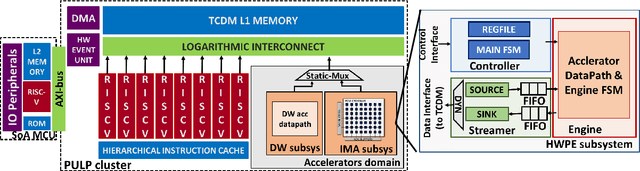
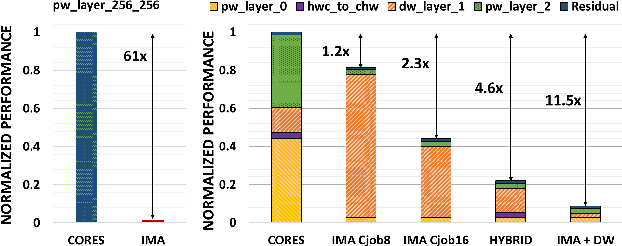
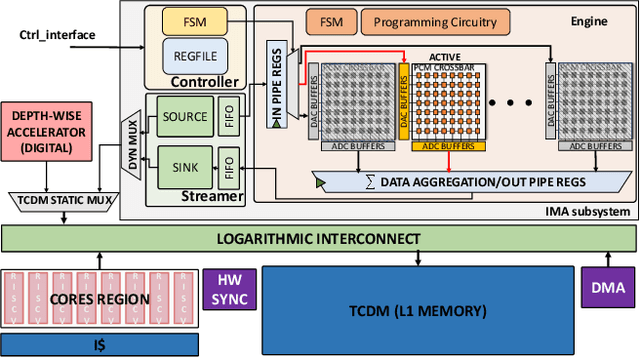
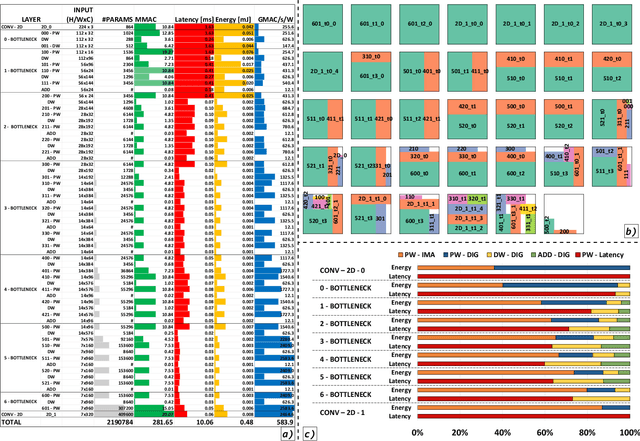
Deployment of modern TinyML tasks on small battery-constrained IoT devices requires high computational energy efficiency. Analog In-Memory Computing (IMC) using non-volatile memory (NVM) promises major efficiency improvements in deep neural network (DNN) inference and serves as on-chip memory storage for DNN weights. However, IMC's functional flexibility limitations and their impact on performance, energy, and area efficiency are not yet fully understood at the system level. To target practical end-to-end IoT applications, IMC arrays must be enclosed in heterogeneous programmable systems, introducing new system-level challenges which we aim at addressing in this work. We present a heterogeneous tightly-coupled clustered architecture integrating 8 RISC-V cores, an in-memory computing accelerator (IMA), and digital accelerators. We benchmark the system on a highly heterogeneous workload such as the Bottleneck layer from a MobileNetV2, showing 11.5x performance and 9.5x energy efficiency improvements, compared to highly optimized parallel execution on the cores. Furthermore, we explore the requirements for end-to-end inference of a full mobile-grade DNN (MobileNetV2) in terms of IMC array resources, by scaling up our heterogeneous architecture to a multi-array accelerator. Our results show that our solution, on the end-to-end inference of the MobileNetV2, is one order of magnitude better in terms of execution latency than existing programmable architectures and two orders of magnitude better than state-of-the-art heterogeneous solutions integrating in-memory computing analog cores.
AnalogNets: ML-HW Co-Design of Noise-robust TinyML Models and Always-On Analog Compute-in-Memory Accelerator
Nov 10, 2021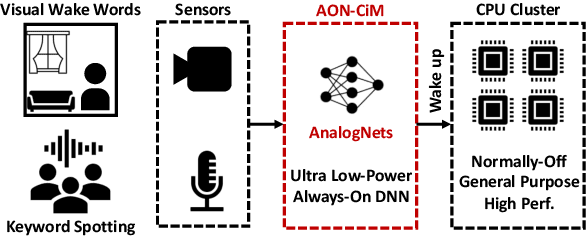
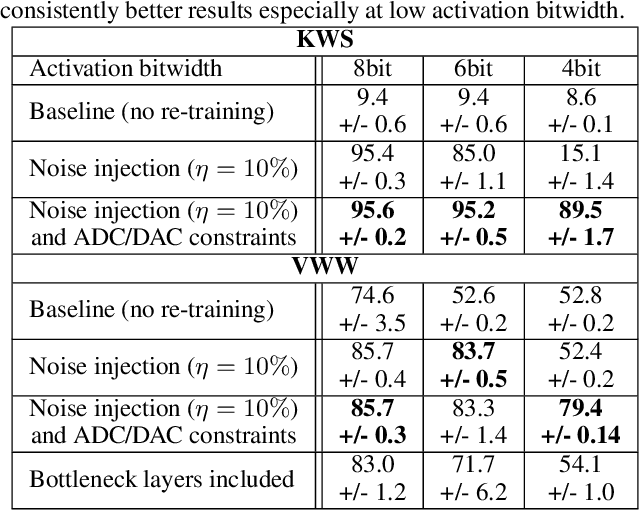
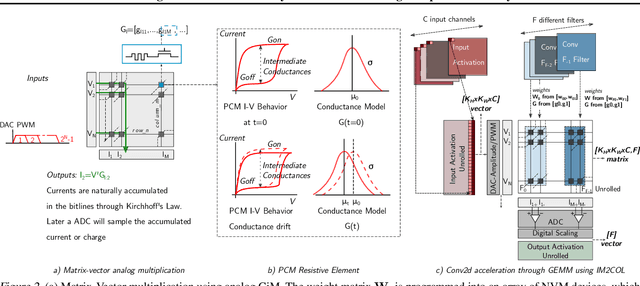
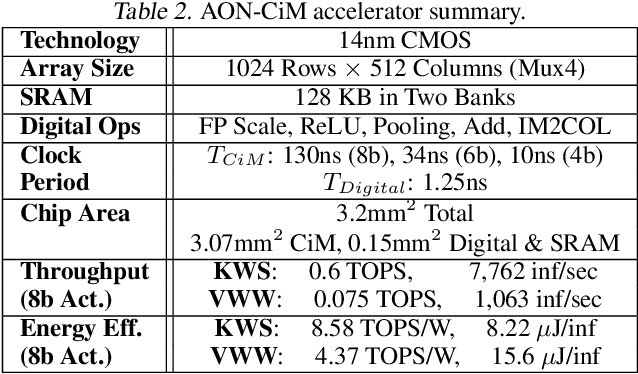
Always-on TinyML perception tasks in IoT applications require very high energy efficiency. Analog compute-in-memory (CiM) using non-volatile memory (NVM) promises high efficiency and also provides self-contained on-chip model storage. However, analog CiM introduces new practical considerations, including conductance drift, read/write noise, fixed analog-to-digital (ADC) converter gain, etc. These additional constraints must be addressed to achieve models that can be deployed on analog CiM with acceptable accuracy loss. This work describes $\textit{AnalogNets}$: TinyML models for the popular always-on applications of keyword spotting (KWS) and visual wake words (VWW). The model architectures are specifically designed for analog CiM, and we detail a comprehensive training methodology, to retain accuracy in the face of analog non-idealities, and low-precision data converters at inference time. We also describe AON-CiM, a programmable, minimal-area phase-change memory (PCM) analog CiM accelerator, with a novel layer-serial approach to remove the cost of complex interconnects associated with a fully-pipelined design. We evaluate the AnalogNets on a calibrated simulator, as well as real hardware, and find that accuracy degradation is limited to 0.8$\%$/1.2$\%$ after 24 hours of PCM drift (8-bit) for KWS/VWW. AnalogNets running on the 14nm AON-CiM accelerator demonstrate 8.58/4.37 TOPS/W for KWS/VWW workloads using 8-bit activations, respectively, and increasing to 57.39/25.69 TOPS/W with $4$-bit activations.
ESSOP: Efficient and Scalable Stochastic Outer Product Architecture for Deep Learning
Mar 25, 2020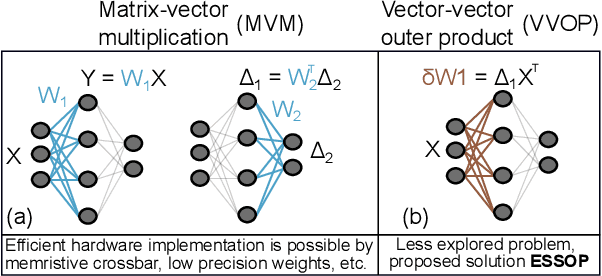
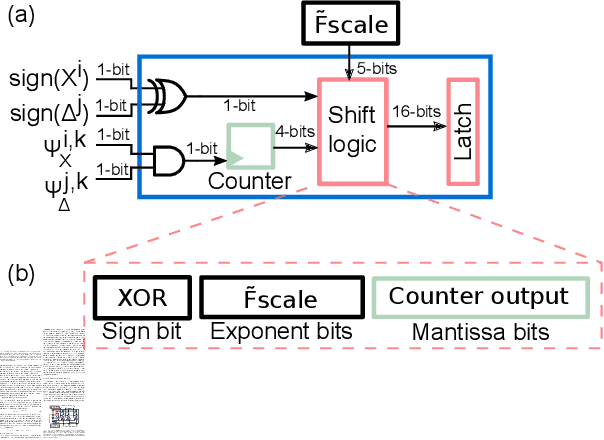
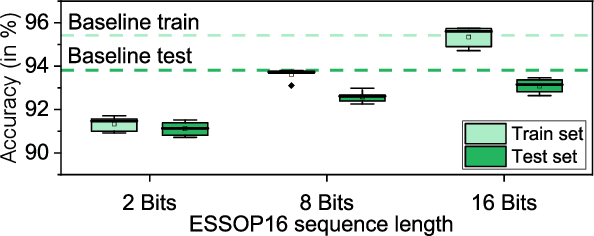
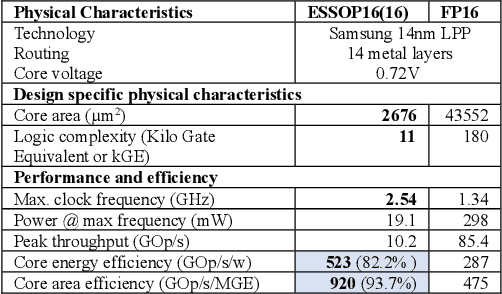
Deep neural networks (DNNs) have surpassed human-level accuracy in a variety of cognitive tasks but at the cost of significant memory/time requirements in DNN training. This limits their deployment in energy and memory limited applications that require real-time learning. Matrix-vector multiplications (MVM) and vector-vector outer product (VVOP) are the two most expensive operations associated with the training of DNNs. Strategies to improve the efficiency of MVM computation in hardware have been demonstrated with minimal impact on training accuracy. However, the VVOP computation remains a relatively less explored bottleneck even with the aforementioned strategies. Stochastic computing (SC) has been proposed to improve the efficiency of VVOP computation but on relatively shallow networks with bounded activation functions and floating-point (FP) scaling of activation gradients. In this paper, we propose ESSOP, an efficient and scalable stochastic outer product architecture based on the SC paradigm. We introduce efficient techniques to generalize SC for weight update computation in DNNs with the unbounded activation functions (e.g., ReLU), required by many state-of-the-art networks. Our architecture reduces the computational cost by re-using random numbers and replacing certain FP multiplication operations by bit shift scaling. We show that the ResNet-32 network with 33 convolution layers and a fully-connected layer can be trained with ESSOP on the CIFAR-10 dataset to achieve baseline comparable accuracy. Hardware design of ESSOP at 14nm technology node shows that, compared to a highly pipelined FP16 multiplier design, ESSOP is 82.2% and 93.7% better in energy and area efficiency respectively for outer product computation.
Supervised Learning in Spiking Neural Networks with Phase-Change Memory Synapses
May 28, 2019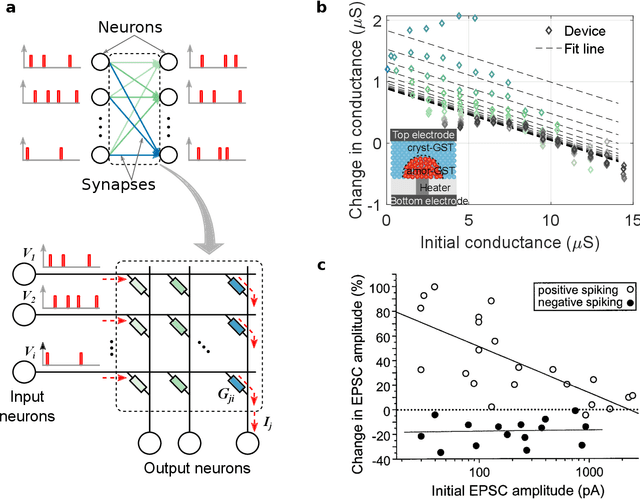
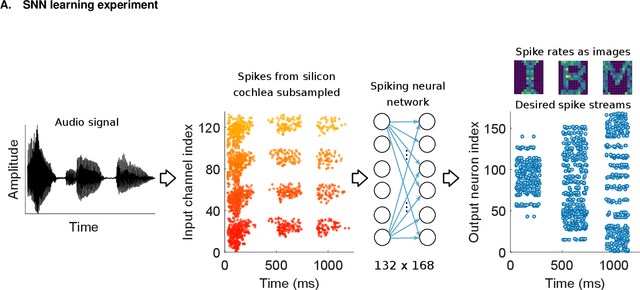
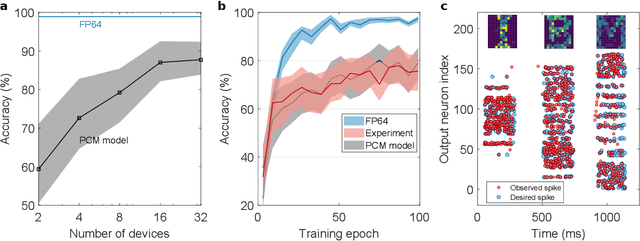
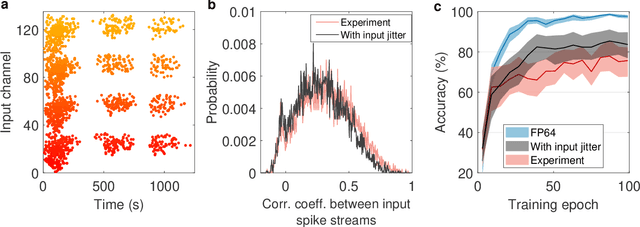
Spiking neural networks (SNN) are artificial computational models that have been inspired by the brain's ability to naturally encode and process information in the time domain. The added temporal dimension is believed to render them more computationally efficient than the conventional artificial neural networks, though their full computational capabilities are yet to be explored. Recently, computational memory architectures based on non-volatile memory crossbar arrays have shown great promise to implement parallel computations in artificial and spiking neural networks. In this work, we experimentally demonstrate for the first time, the feasibility to realize high-performance event-driven in-situ supervised learning systems using nanoscale and stochastic phase-change synapses. Our SNN is trained to recognize audio signals of alphabets encoded using spikes in the time domain and to generate spike trains at precise time instances to represent the pixel intensities of their corresponding images. Moreover, with a statistical model capturing the experimental behavior of the devices, we investigate architectural and systems-level solutions for improving the training and inference performance of our computational memory-based system. Combining the computational potential of supervised SNNs with the parallel compute power of computational memory, the work paves the way for next-generation of efficient brain-inspired systems.
Fatiguing STDP: Learning from Spike-Timing Codes in the Presence of Rate Codes
Jun 17, 2017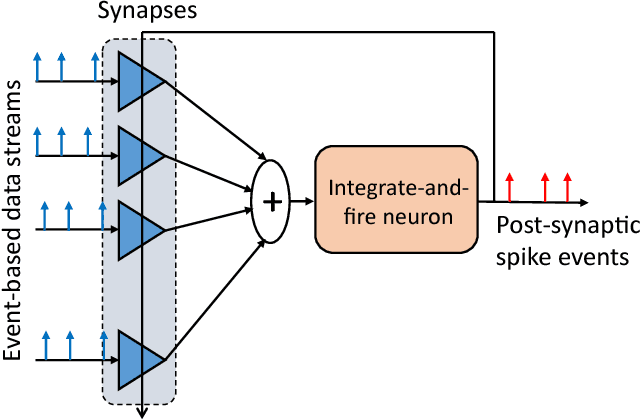
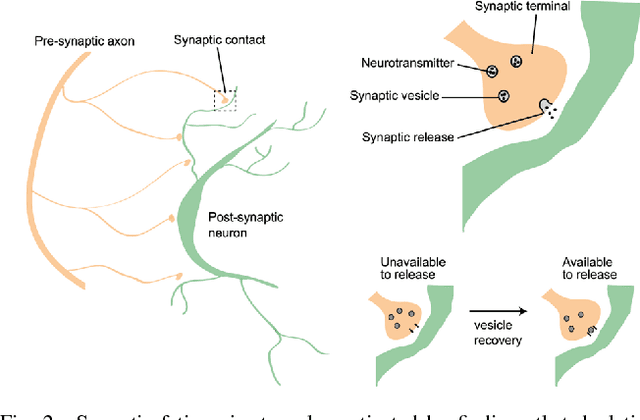
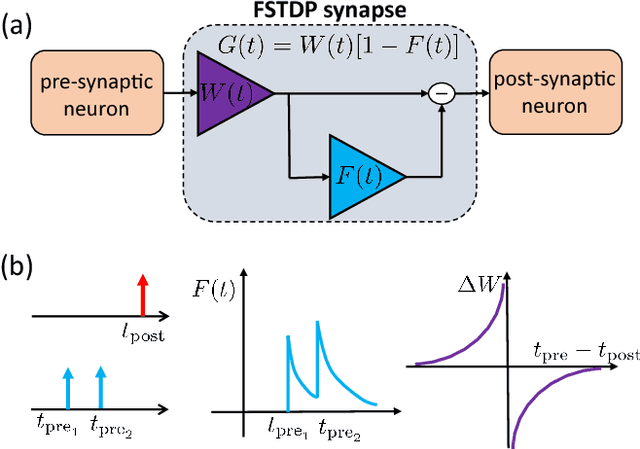
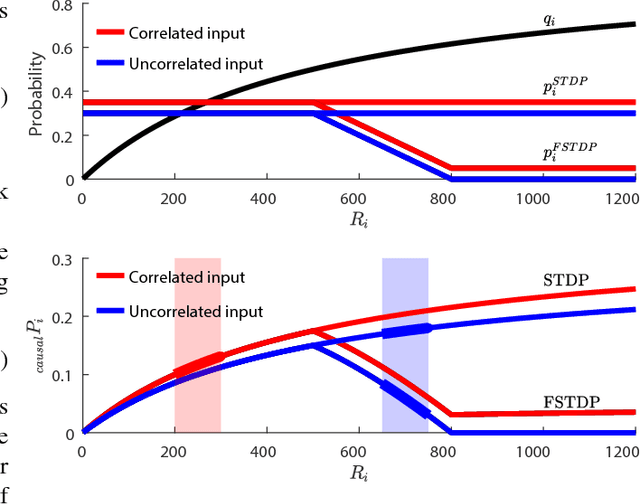
Spiking neural networks (SNNs) could play a key role in unsupervised machine learning applications, by virtue of strengths related to learning from the fine temporal structure of event-based signals. However, some spike-timing-related strengths of SNNs are hindered by the sensitivity of spike-timing-dependent plasticity (STDP) rules to input spike rates, as fine temporal correlations may be obstructed by coarser correlations between firing rates. In this article, we propose a spike-timing-dependent learning rule that allows a neuron to learn from the temporally-coded information despite the presence of rate codes. Our long-term plasticity rule makes use of short-term synaptic fatigue dynamics. We show analytically that, in contrast to conventional STDP rules, our fatiguing STDP (FSTDP) helps learn the temporal code, and we derive the necessary conditions to optimize the learning process. We showcase the effectiveness of FSTDP in learning spike-timing correlations among processes of different rates in synthetic data. Finally, we use FSTDP to detect correlations in real-world weather data from the United States in an experimental realization of the algorithm that uses a neuromorphic hardware platform comprising phase-change memristive devices. Taken together, our analyses and demonstrations suggest that FSTDP paves the way for the exploitation of the spike-based strengths of SNNs in real-world applications.