 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware-aware training for large-scale and diverse deep learning inference workloads using in-memory computing-based accelerators
Feb 16, 2023Analog in-memory computing (AIMC) -- a promising approach for energy-efficient acceleration of deep learning workloads -- computes matrix-vector multiplications (MVMs) but only approximately, due to nonidealities that often are non-deterministic or nonlinear. This can adversely impact the achievable deep neural network (DNN) inference accuracy as compared to a conventional floating point (FP) implementation. While retraining has previously been suggested to improve robustness, prior work has explored only a few DNN topologies, using disparate and overly simplified AIMC hardware models. Here, we use hardware-aware (HWA) training to systematically examine the accuracy of AIMC for multiple common artificial intelligence (AI) workloads across multiple DNN topologies, and investigate sensitivity and robustness to a broad set of nonidealities. By introducing a new and highly realistic AIMC crossbar-model, we improve significantly on earlier retraining approaches. We show that many large-scale DNNs of various topologies, including convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformers, can in fact be successfully retrained to show iso-accuracy on AIMC. Our results further suggest that AIMC nonidealities that add noise to the inputs or outputs, not the weights, have the largest impact on DNN accuracy, and that RNNs are particularly robust to all nonidealities.
AnalogNets: ML-HW Co-Design of Noise-robust TinyML Models and Always-On Analog Compute-in-Memory Accelerator
Nov 10, 2021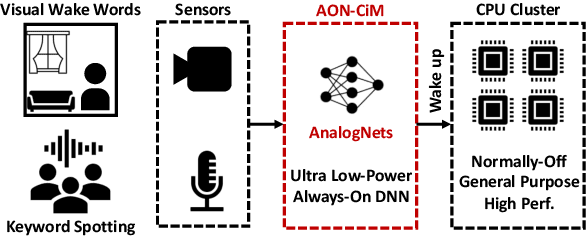
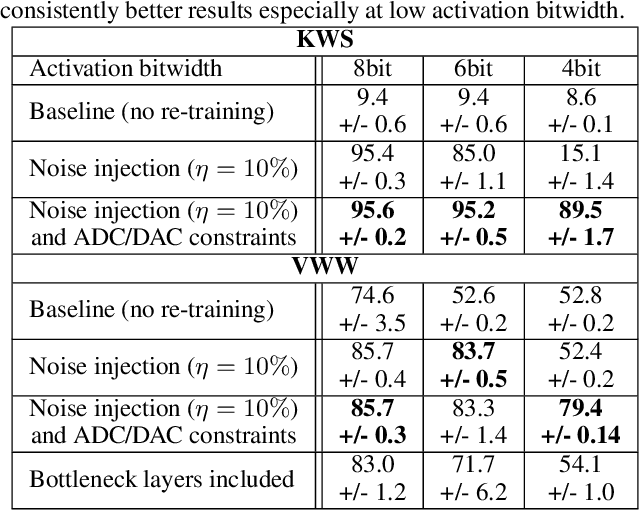
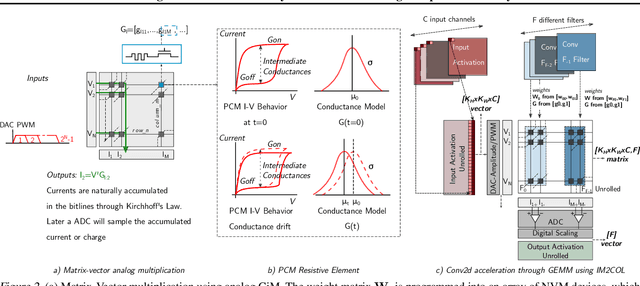
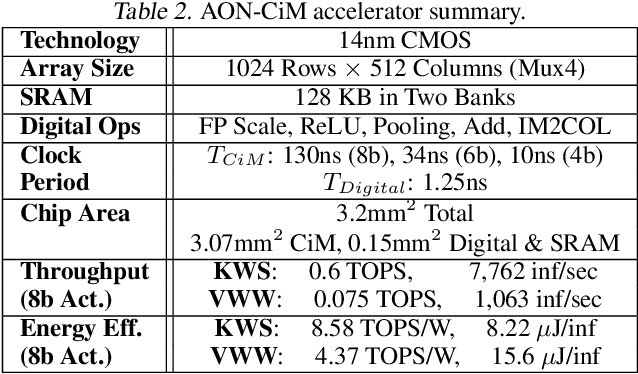
Always-on TinyML perception tasks in IoT applications require very high energy efficiency. Analog compute-in-memory (CiM) using non-volatile memory (NVM) promises high efficiency and also provides self-contained on-chip model storage. However, analog CiM introduces new practical considerations, including conductance drift, read/write noise, fixed analog-to-digital (ADC) converter gain, etc. These additional constraints must be addressed to achieve models that can be deployed on analog CiM with acceptable accuracy loss. This work describes $\textit{AnalogNets}$: TinyML models for the popular always-on applications of keyword spotting (KWS) and visual wake words (VWW). The model architectures are specifically designed for analog CiM, and we detail a comprehensive training methodology, to retain accuracy in the face of analog non-idealities, and low-precision data converters at inference time. We also describe AON-CiM, a programmable, minimal-area phase-change memory (PCM) analog CiM accelerator, with a novel layer-serial approach to remove the cost of complex interconnects associated with a fully-pipelined design. We evaluate the AnalogNets on a calibrated simulator, as well as real hardware, and find that accuracy degradation is limited to 0.8$\%$/1.2$\%$ after 24 hours of PCM drift (8-bit) for KWS/VWW. AnalogNets running on the 14nm AON-CiM accelerator demonstrate 8.58/4.37 TOPS/W for KWS/VWW workloads using 8-bit activations, respectively, and increasing to 57.39/25.69 TOPS/W with $4$-bit activations.
Supervised Learning in Spiking Neural Networks with Phase-Change Memory Synapses
May 28, 2019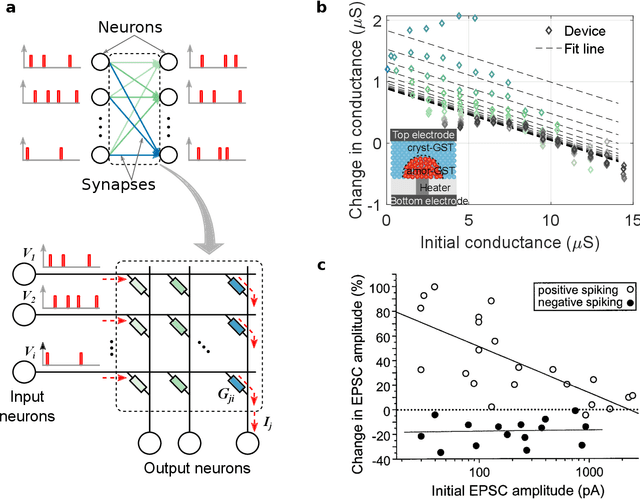
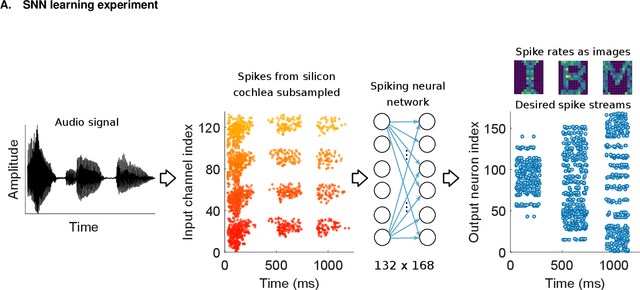
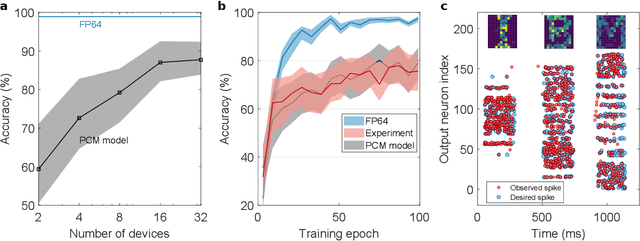
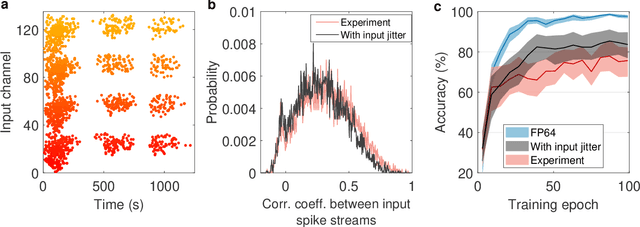
Spiking neural networks (SNN) are artificial computational models that have been inspired by the brain's ability to naturally encode and process information in the time domain. The added temporal dimension is believed to render them more computationally efficient than the conventional artificial neural networks, though their full computational capabilities are yet to be explored. Recently, computational memory architectures based on non-volatile memory crossbar arrays have shown great promise to implement parallel computations in artificial and spiking neural networks. In this work, we experimentally demonstrate for the first time, the feasibility to realize high-performance event-driven in-situ supervised learning systems using nanoscale and stochastic phase-change synapses. Our SNN is trained to recognize audio signals of alphabets encoded using spikes in the time domain and to generate spike trains at precise time instances to represent the pixel intensities of their corresponding images. Moreover, with a statistical model capturing the experimental behavior of the devices, we investigate architectural and systems-level solutions for improving the training and inference performance of our computational memory-based system. Combining the computational potential of supervised SNNs with the parallel compute power of computational memory, the work paves the way for next-generation of efficient brain-inspired systems.