 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalogNets: ML-HW Co-Design of Noise-robust TinyML Models and Always-On Analog Compute-in-Memory Accelerator
Nov 10, 2021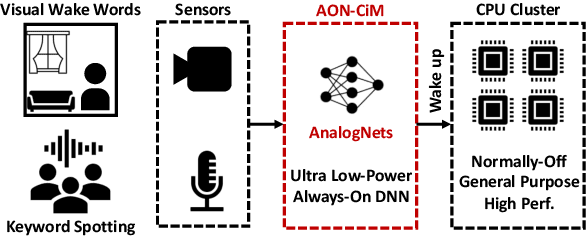
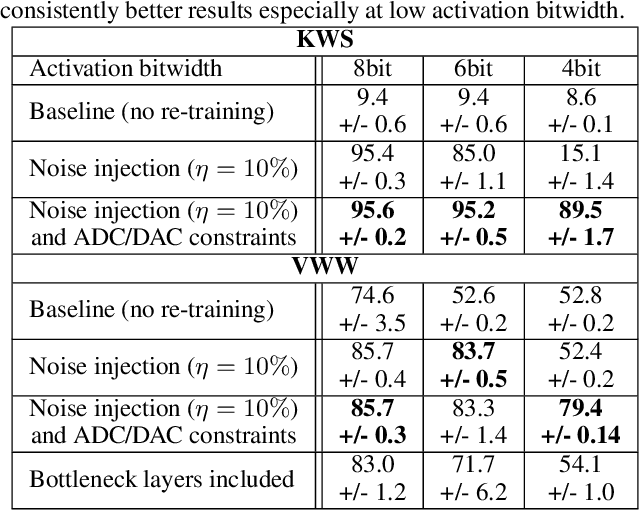
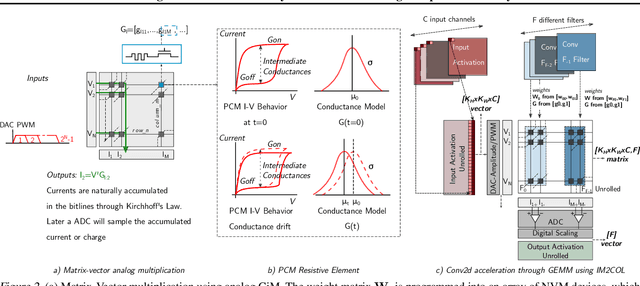
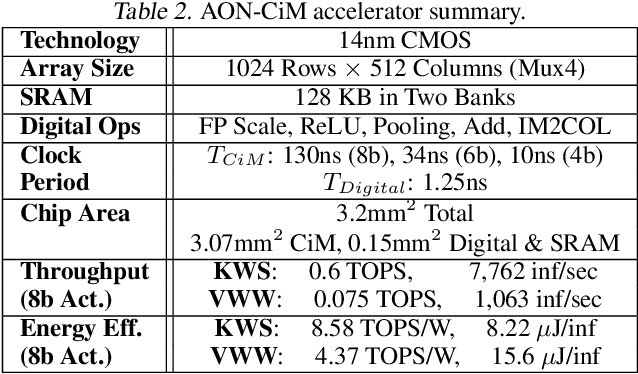
Always-on TinyML perception tasks in IoT applications require very high energy efficiency. Analog compute-in-memory (CiM) using non-volatile memory (NVM) promises high efficiency and also provides self-contained on-chip model storage. However, analog CiM introduces new practical considerations, including conductance drift, read/write noise, fixed analog-to-digital (ADC) converter gain, etc. These additional constraints must be addressed to achieve models that can be deployed on analog CiM with acceptable accuracy loss. This work describes $\textit{AnalogNets}$: TinyML models for the popular always-on applications of keyword spotting (KWS) and visual wake words (VWW). The model architectures are specifically designed for analog CiM, and we detail a comprehensive training methodology, to retain accuracy in the face of analog non-idealities, and low-precision data converters at inference time. We also describe AON-CiM, a programmable, minimal-area phase-change memory (PCM) analog CiM accelerator, with a novel layer-serial approach to remove the cost of complex interconnects associated with a fully-pipelined design. We evaluate the AnalogNets on a calibrated simulator, as well as real hardware, and find that accuracy degradation is limited to 0.8$\%$/1.2$\%$ after 24 hours of PCM drift (8-bit) for KWS/VWW. AnalogNets running on the 14nm AON-CiM accelerator demonstrate 8.58/4.37 TOPS/W for KWS/VWW workloads using 8-bit activations, respectively, and increasing to 57.39/25.69 TOPS/W with $4$-bit activations.
Training DNN IoT Applications for Deployment On Analog NVM Crossbars
Nov 03, 2019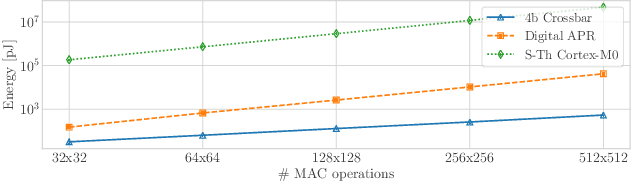

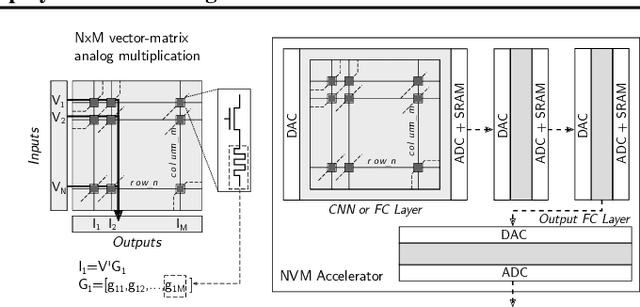

Deep Neural Networks (DNN) applications are increasingly being deployed in always-on IoT devices. However, the limited resources in tiny microcontroller units (MCUs) limit the deployment of the required Machine Learning (ML) models. Therefore alternatives to traditional architectures such as Computation-In-Memory based on resistive nonvolatile memories (NVM), promising high integration density, low power consumption and massively-parallel computation capabilities, are under study. However, these technologies are still immature and suffer from intrinsic analog nature problems --noise, non-linearities, inability to represent negative values, and limited-precision per device. Consequently, mapping DNNs to NVM crossbars requires the full-custom design of each one of the DNN layers, involving finely tuned blocks such as ADC/DACs or current subtractors/adders, and thus limiting the chip reconfigurability. This paper presents an NVM-aware framework to efficiently train and map the DNN to the NVM hardware. We propose the first method that trains the NN weights while ensuring uniformity across layer weights/activations, improving HW blocks re-usability. Firstly, this quantization algorithm obtains uniform scaling across the DNN layers independently of their characteristics, removing the need of per-layer full-custom design while reducing the peripheral HW. Secondly, for certain applications we make use of Network Architecture Search, to avoid using negative weights. Unipolar weight matrices translate into simpler analog periphery and lead to $67 \%$ area improvement and up to $40 \%$ power reduction. We validate our idea with CIFAR10 and HAR applications by mapping to crossbars using $4$-bit and $2$-bit devices. Up to $92.91\%$ accuracy ($95\%$ floating-point) can be achieved using $2$-bit only-positive weights for HAR.
Neural Network Design for Energy-Autonomous AI Applications using Temporal Encoding
Oct 15, 2019
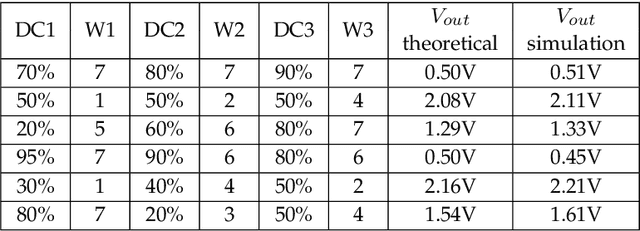

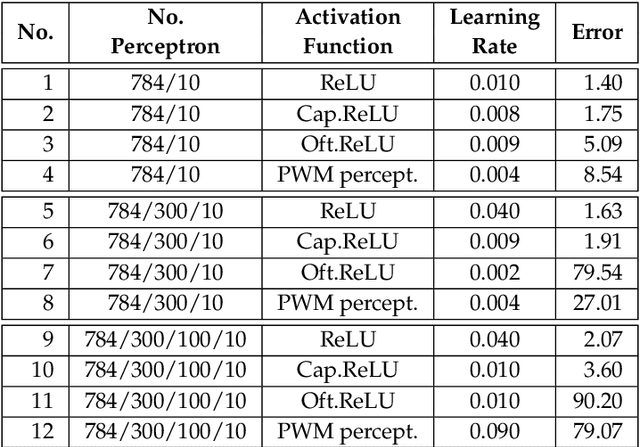
Neural Networks (NNs) are steering a new generation of artificial intelligence (AI) applications at the micro-edge. Examples include wireless sensors, wearables and cybernetic systems that collect data and process them to support real-world decisions and controls. For energy autonomy, these applications are typically powered by energy harvesters. As harvesters and other power sources which provide energy autonomy inevitably have power variations, the circuits need to robustly operate over a dynamic power envelope. In other words, the NN hardware needs to be able to function correctly under unpredictable and variable supply voltages. In this paper, we propose a novel NN design approach using the principle of pulse width modulation (PWM). PWM signals represent information with their duty cycle values which may be made independent of the voltages and frequencies of the carrier signals. We design a PWM-based perceptron which can serve as the fundamental building block for NNs, by using an entirely new method of realising arithmetic in the PWM domain. We analyse the proposed approach building from a 3x3 perceptron circuit to a complex multi-layer NN. Using handwritten character recognition as an exemplar of AI applications, we demonstrate the power elasticity, resilience and efficiency of the proposed NN design in the presence of functional and parametric variations including large voltage variations in the power supply.