 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining DNN IoT Applications for Deployment On Analog NVM Crossbars
Nov 03, 2019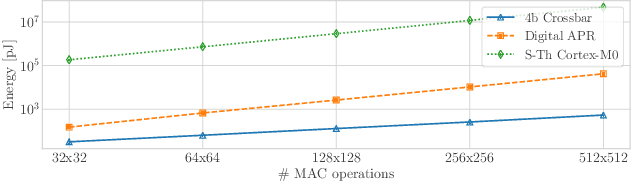

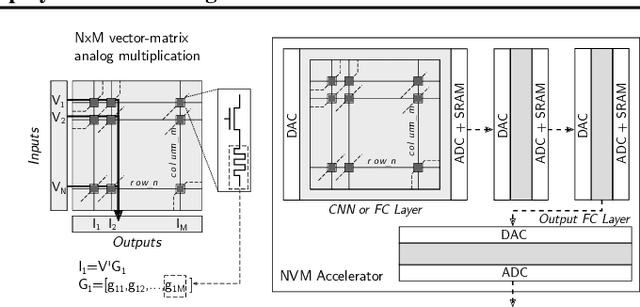

Deep Neural Networks (DNN) applications are increasingly being deployed in always-on IoT devices. However, the limited resources in tiny microcontroller units (MCUs) limit the deployment of the required Machine Learning (ML) models. Therefore alternatives to traditional architectures such as Computation-In-Memory based on resistive nonvolatile memories (NVM), promising high integration density, low power consumption and massively-parallel computation capabilities, are under study. However, these technologies are still immature and suffer from intrinsic analog nature problems --noise, non-linearities, inability to represent negative values, and limited-precision per device. Consequently, mapping DNNs to NVM crossbars requires the full-custom design of each one of the DNN layers, involving finely tuned blocks such as ADC/DACs or current subtractors/adders, and thus limiting the chip reconfigurability. This paper presents an NVM-aware framework to efficiently train and map the DNN to the NVM hardware. We propose the first method that trains the NN weights while ensuring uniformity across layer weights/activations, improving HW blocks re-usability. Firstly, this quantization algorithm obtains uniform scaling across the DNN layers independently of their characteristics, removing the need of per-layer full-custom design while reducing the peripheral HW. Secondly, for certain applications we make use of Network Architecture Search, to avoid using negative weights. Unipolar weight matrices translate into simpler analog periphery and lead to $67 \%$ area improvement and up to $40 \%$ power reduction. We validate our idea with CIFAR10 and HAR applications by mapping to crossbars using $4$-bit and $2$-bit devices. Up to $92.91\%$ accuracy ($95\%$ floating-point) can be achieved using $2$-bit only-positive weights for HAR.