 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTsetlinWiSARD: On-Chip Training of Weightless Neural Networks using Tsetlin Automata on FPGAs
Mar 25, 2026Increasing demands for adaptability, privacy, and security at the edge have persistently pushed the frontiers for a new generation of machine learning (ML) algorithms with training and inference capabilities on-chip. Weightless Neural Network (WNN) is such an algorithm that is principled on lookup table based simple neuron structures. As a result, it offers architectural benefits, such as low-latency, low-complexity inference, compared to deep neural networks that depend heavily on multiply-accumulate operations. However, traditional WNNs rely on memorization-based one-shot training, which either leads to overfitting and reduced accuracy or requires tedious post-training adjustments, limiting their effectiveness for efficient on chip training. In this work, we propose TsetlinWiSARD, a training approach for WNNs that leverages Tsetlin Automata (TAs) to enable probabilistic, feedback-driven learning. It overcomes the overfitting of WiSARD's one-shot training with iterative optimization, while maintaining simple, continuous binary feedback for efficient on-chip training. Central to our approach is a field programmable gate array (FPGA)-based training architecture that delivers state-of-the-art accuracy while significantly improving hardware efficiency. Our approach provides over 1000x faster training when compared with the traditional WiSARD implementation of WNNs. Further, we demonstrate 22% reduced resource usage, 93.3% lower latency, and 64.2% lower power consumption compared to FPGA-based training accelerators implementing other ML algorithms.
Eventizing Traditionally Opaque Binary Neural Networks as 1-safe Petri net Models
Feb 13, 2026Binary Neural Networks (BNNs) offer a low-complexity and energy-efficient alternative to traditional full-precision neural networks by constraining their weights and activations to binary values. However, their discrete, highly non-linear behavior makes them difficult to explain, validate and formally verify. As a result, BNNs remain largely opaque, limiting their suitability in safety-critical domains, where causal transparency and behavioral guarantees are essential. In this work, we introduce a Petri net (PN)-based framework that captures the BNN's internal operations as event-driven processes. By "eventizing" their operations, we expose their causal relationships and dependencies for a fine-grained analysis of concurrency, ordering, and state evolution. Here, we construct modular PN blueprints for core BNN components including activation, gradient computation and weight updates, and compose them into a complete system-level model. We then validate the composed PN against a reference software-based BNN, verify it against reachability and structural checks to establish 1-safeness, deadlock-freeness, mutual exclusion and correct-by-construction causal sequencing, before we assess its scalability and complexity at segment, component, and system levels using the automated measurement tools in Workcraft. Overall, this framework enables causal introspection of transparent and event-driven BNNs that are amenable to formal reasoning and verification.
Event-Driven Digital-Time-Domain Inference Architectures for Tsetlin Machines
Nov 12, 2025Machine learning fits model parameters to approximate input-output mappings, predicting unknown samples. However, these models often require extensive arithmetic computations during inference, increasing latency and power consumption. This paper proposes a digital-time-domain computing approach for Tsetlin machine (TM) inference process to address these challenges. This approach leverages a delay accumulation mechanism to mitigate the costly arithmetic sums of classes and employs a Winner-Takes-All scheme to replace conventional magnitude comparators. Specifically, a Hamming distance-driven time-domain scheme is implemented for multi-class TMs. Furthermore, differential delay paths, combined with a leading-ones-detector logarithmic delay compression digital-time-domain scheme, are utilised for the coalesced TMs, accommodating both binary-signed and exponential-scale delay accumulation issues. Compared to the functionally equivalent, post-implementation digital TM architecture baseline, the proposed architecture demonstrates orders-of-magnitude improvements in energy efficiency and throughput.
A Methodology for Transparent Logic-Based Classification Using a Multi-Task Convolutional Tsetlin Machine
Oct 02, 2025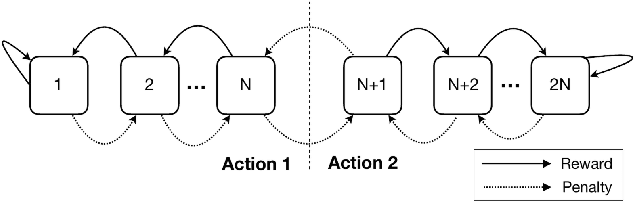
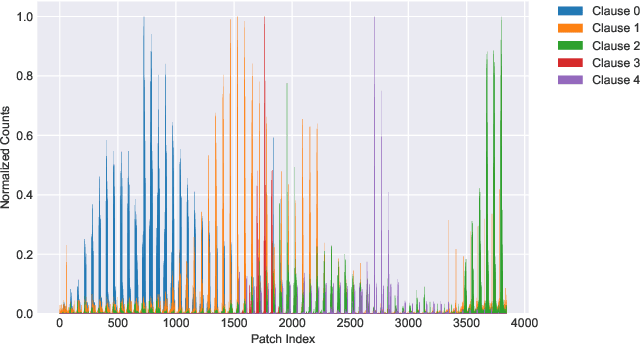

The Tsetlin Machine (TM) is a novel machine learning paradigm that employs finite-state automata for learning and utilizes propositional logic to represent patterns. Due to its simplistic approach, TMs are inherently more interpretable than learning algorithms based on Neural Networks. The Convolutional TM has shown comparable performance on various datasets such as MNIST, K-MNIST, F-MNIST and CIFAR-2. In this paper, we explore the applicability of the TM architecture for large-scale multi-channel (RGB) image classification. We propose a methodology to generate both local interpretations and global class representations. The local interpretations can be used to explain the model predictions while the global class representations aggregate important patterns for each class. These interpretations summarize the knowledge captured by the convolutional clauses, which can be visualized as images. We evaluate our methods on MNIST and CelebA datasets, using models that achieve 98.5\% accuracy on MNIST and 86.56\% F1-score on CelebA (compared to 88.07\% for ResNet50) respectively. We show that the TM performs competitively to this deep learning model while maintaining its interpretability, even in large-scale complex training environments. This contributes to a better understanding of TM clauses and provides insights into how these models can be applied to more complex and diverse datasets.
Omni TM-AE: A Scalable and Interpretable Embedding Model Using the Full Tsetlin Machine State Space
May 22, 2025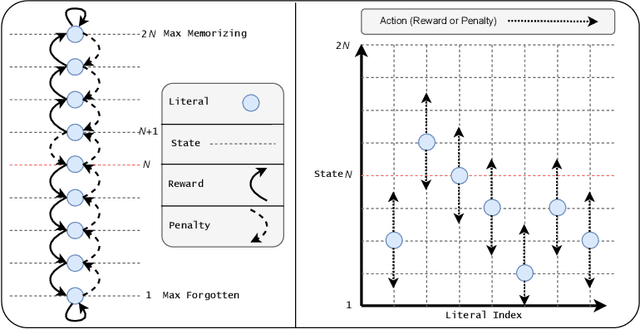
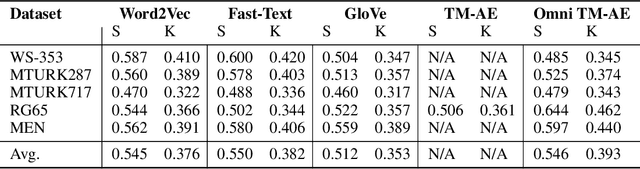
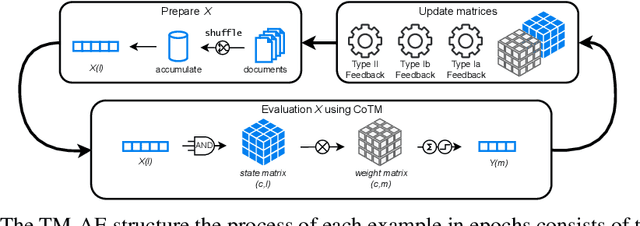
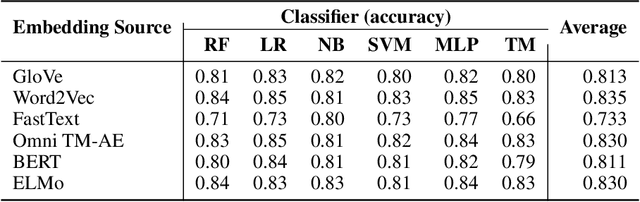
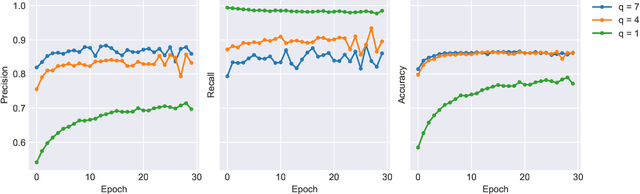
The increasing complexity of large-scale language models has amplified concerns regarding their interpretability and reusability. While traditional embedding models like Word2Vec and GloVe offer scalability, they lack transparency and often behave as black boxes. Conversely, interpretable models such as the Tsetlin Machine (TM) have shown promise in constructing explainable learning systems, though they previously faced limitations in scalability and reusability. In this paper, we introduce Omni Tsetlin Machine AutoEncoder (Omni TM-AE), a novel embedding model that fully exploits the information contained in the TM's state matrix, including literals previously excluded from clause formation. This method enables the construction of reusable, interpretable embeddings through a single training phase. Extensive experiments across semantic similarity, sentiment classification, and document clustering tasks show that Omni TM-AE performs competitively with and often surpasses mainstream embedding models. These results demonstrate that it is possible to balance performance, scalability, and interpretability in modern Natural Language Processing (NLP) systems without resorting to opaque architectures.
Efficient FPGA Implementation of Time-Domain Popcount for Low-Complexity Machine Learning
May 04, 2025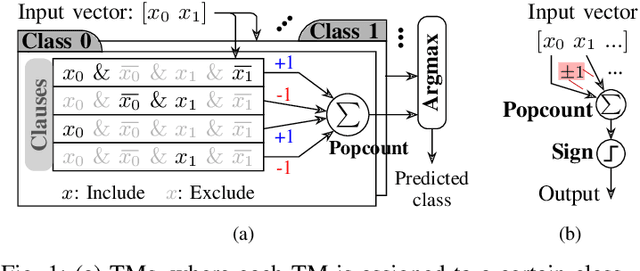
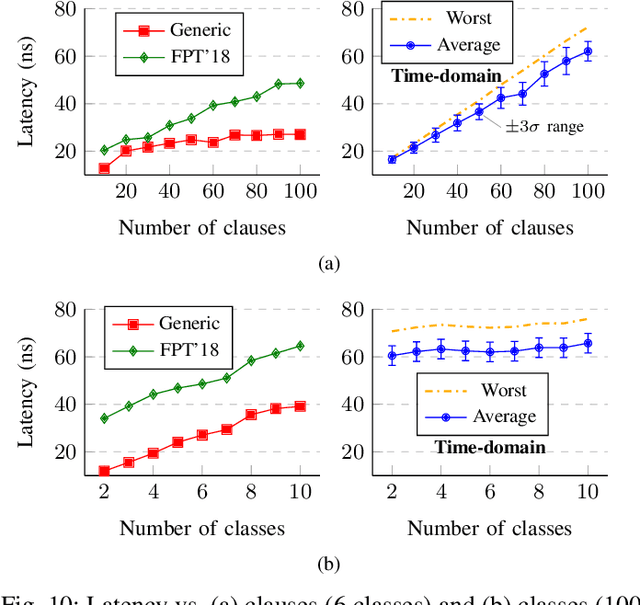
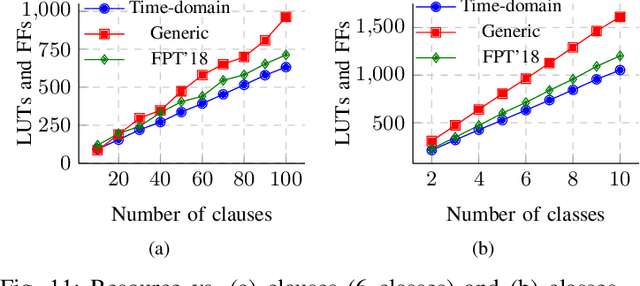
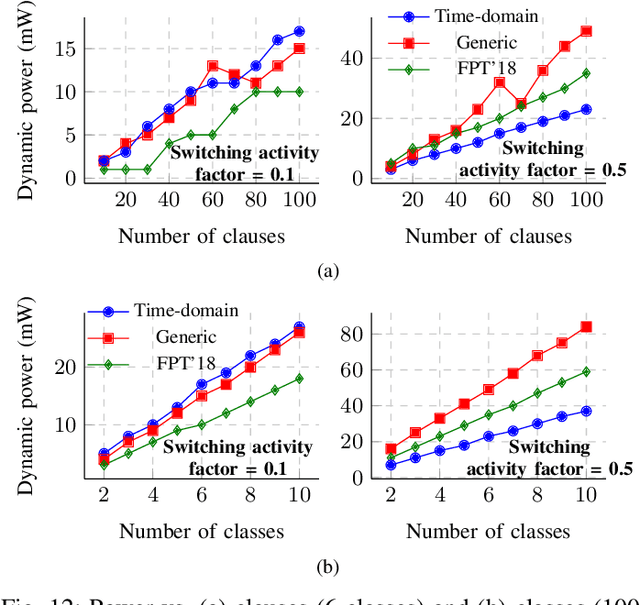
Population count (popcount) is a crucial operation for many low-complexity machine learning (ML) algorithms, including Tsetlin Machine (TM)-a promising new ML method, particularly well-suited for solving classification tasks. The inference mechanism in TM consists of propositional logic-based structures within each class, followed by a majority voting scheme, which makes the classification decision. In TM, the voters are the outputs of Boolean clauses. The voting mechanism comprises two operations: popcount for each class and determining the class with the maximum vote by means of an argmax operation. While TMs offer a lightweight ML alternative, their performance is often limited by the high computational cost of popcount and comparison required to produce the argmax result. In this paper, we propose an innovative approach to accelerate and optimize these operations by performing them in the time domain. Our time-domain implementation uses programmable delay lines (PDLs) and arbiters to efficiently manage these tasks through delay-based mechanisms. We also present an FPGA design flow for practical implementation of the time-domain popcount, addressing delay skew and ensuring that the behavior matches that of the model's intended functionality. By leveraging the natural compatibility of the proposed popcount with asynchronous architectures, we demonstrate significant improvements in an asynchronous TM, including up to 38% reduction in latency, 43.1% reduction in dynamic power, and 15% savings in resource utilization, compared to synchronous TMs using adder-based popcount.
Attention-enabled Explainable AI for Bladder Cancer Recurrence Prediction
Apr 30, 2025Non-muscle-invasive bladder cancer (NMIBC) is a relentless challenge in oncology, with recurrence rates soaring as high as 70-80%. Each recurrence triggers a cascade of invasive procedures, lifelong surveillance, and escalating healthcare costs - affecting 460,000 individuals worldwide. However, existing clinical prediction tools remain fundamentally flawed, often overestimating recurrence risk and failing to provide personalized insights for patient management. In this work, we propose an interpretable deep learning framework that integrates vector embeddings and attention mechanisms to improve NMIBC recurrence prediction performance. We incorporate vector embeddings for categorical variables such as smoking status and intravesical treatments, allowing the model to capture complex relationships between patient attributes and recurrence risk. These embeddings provide a richer representation of the data, enabling improved feature interactions and enhancing prediction performance. Our approach not only enhances performance but also provides clinicians with patient-specific insights by highlighting the most influential features contributing to recurrence risk for each patient. Our model achieves accuracy of 70% with tabular data, outperforming conventional statistical methods while providing clinician-friendly patient-level explanations through feature attention. Unlike previous studies, our approach identifies new important factors influencing recurrence, such as surgical duration and hospital stay, which had not been considered in existing NMIBC prediction models.
Dynamic Tsetlin Machine Accelerators for On-Chip Training at the Edge using FPGAs
Apr 28, 2025The increased demand for data privacy and security in machine learning (ML) applications has put impetus on effective edge training on Internet-of-Things (IoT) nodes. Edge training aims to leverage speed, energy efficiency and adaptability within the resource constraints of the nodes. Deploying and training Deep Neural Networks (DNNs)-based models at the edge, although accurate, posit significant challenges from the back-propagation algorithm's complexity, bit precision trade-offs, and heterogeneity of DNN layers. This paper presents a Dynamic Tsetlin Machine (DTM) training accelerator as an alternative to DNN implementations. DTM utilizes logic-based on-chip inference with finite-state automata-driven learning within the same Field Programmable Gate Array (FPGA) package. Underpinned on the Vanilla and Coalesced Tsetlin Machine algorithms, the dynamic aspect of the accelerator design allows for a run-time reconfiguration targeting different datasets, model architectures, and model sizes without resynthesis. This makes the DTM suitable for targeting multivariate sensor-based edge tasks. Compared to DNNs, DTM trains with fewer multiply-accumulates, devoid of derivative computation. It is a data-centric ML algorithm that learns by aligning Tsetlin automata with input data to form logical propositions enabling efficient Look-up-Table (LUT) mapping and frugal Block RAM usage in FPGA training implementations. The proposed accelerator offers 2.54x more Giga operations per second per Watt (GOP/s per W) and uses 6x less power than the next-best comparable design.
Runtime Tunable Tsetlin Machines for Edge Inference on eFPGAs
Feb 10, 2025Embedded Field-Programmable Gate Arrays (eFPGAs) allow for the design of hardware accelerators of edge Machine Learning (ML) applications at a lower power budget compared with traditional FPGA platforms. However, the limited eFPGA logic and memory significantly constrain compute capabilities and model size. As such, ML application deployment on eFPGAs is in direct contrast with the most recent FPGA approaches developing architecture-specific implementations and maximizing throughput over resource frugality. This paper focuses on the opposite side of this trade-off: the proposed eFPGA accelerator focuses on minimizing resource usage and allowing flexibility for on-field recalibration over throughput. This allows for runtime changes in model size, architecture, and input data dimensionality without offline resynthesis. This is made possible through the use of a bitwise compressed inference architecture of the Tsetlin Machine (TM) algorithm. TM compute does not require any multiplication operations, being limited to only bitwise AND, OR, NOT, summations and additions. Additionally, TM model compression allows the entire model to fit within the on-chip block RAM of the eFPGA. The paper uses this accelerator to propose a strategy for runtime model tuning in the field. The proposed approach uses 2.5x fewer Look-up-Tables (LUTs) and 3.38x fewer registers than the current most resource-fugal design and achieves up to 129x energy reduction compared with low-power microcontrollers running the same ML application.
ETHEREAL: Energy-efficient and High-throughput Inference using Compressed Tsetlin Machine
Feb 08, 2025



The Tsetlin Machine (TM) is a novel alternative to deep neural networks (DNNs). Unlike DNNs, which rely on multi-path arithmetic operations, a TM learns propositional logic patterns from data literals using Tsetlin automata. This fundamental shift from arithmetic to logic underpinning makes TM suitable for empowering new applications with low-cost implementations. In TM, literals are often included by both positive and negative clauses within the same class, canceling out their impact on individual class definitions. This property can be exploited to develop compressed TM models, enabling energy-efficient and high-throughput inferences for machine learning (ML) applications. We introduce a training approach that incorporates excluded automata states to sparsify TM logic patterns in both positive and negative clauses. This exclusion is iterative, ensuring that highly class-correlated (and therefore significant) literals are retained in the compressed inference model, ETHEREAL, to maintain strong classification accuracy. Compared to standard TMs, ETHEREAL TM models can reduce model size by up to 87.54%, with only a minor accuracy compromise. We validate the impact of this compression on eight real-world Tiny machine learning (TinyML) datasets against standard TM, equivalent Random Forest (RF) and Binarized Neural Network (BNN) on the STM32F746G-DISCO platform. Our results show that ETHEREAL TM models achieve over an order of magnitude reduction in inference time (resulting in higher throughput) and energy consumption compared to BNNs, while maintaining a significantly smaller memory footprint compared to RFs.