 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMPACT:InMemory ComPuting Architecture Based on Y-FlAsh Technology for Coalesced Tsetlin Machine Inference
Dec 04, 2024



The increasing demand for processing large volumes of data for machine learning models has pushed data bandwidth requirements beyond the capability of traditional von Neumann architecture. In-memory computing (IMC) has recently emerged as a promising solution to address this gap by enabling distributed data storage and processing at the micro-architectural level, significantly reducing both latency and energy. In this paper, we present the IMPACT: InMemory ComPuting Architecture Based on Y-FlAsh Technology for Coalesced Tsetlin Machine Inference, underpinned on a cutting-edge memory device, Y-Flash, fabricated on a 180 nm CMOS process. Y-Flash devices have recently been demonstrated for digital and analog memory applications, offering high yield, non-volatility, and low power consumption. The IMPACT leverages the Y-Flash array to implement the inference of a novel machine learning algorithm: coalesced Tsetlin machine (CoTM) based on propositional logic. CoTM utilizes Tsetlin automata (TA) to create Boolean feature selections stochastically across parallel clauses. The IMPACT is organized into two computational crossbars for storing the TA and weights. Through validation on the MNIST dataset, IMPACT achieved 96.3% accuracy. The IMPACT demonstrated improvements in energy efficiency, e.g., 2.23X over CNN-based ReRAM, 2.46X over Neuromorphic using NOR-Flash, and 2.06X over DNN-based PCM, suited for modern ML inference applications.
IMBUE: In-Memory Boolean-to-CUrrent Inference ArchitecturE for Tsetlin Machines
May 22, 2023



In-memory computing for Machine Learning (ML) applications remedies the von Neumann bottlenecks by organizing computation to exploit parallelism and locality. Non-volatile memory devices such as Resistive RAM (ReRAM) offer integrated switching and storage capabilities showing promising performance for ML applications. However, ReRAM devices have design challenges, such as non-linear digital-analog conversion and circuit overheads. This paper proposes an In-Memory Boolean-to-Current Inference Architecture (IMBUE) that uses ReRAM-transistor cells to eliminate the need for such conversions. IMBUE processes Boolean feature inputs expressed as digital voltages and generates parallel current paths based on resistive memory states. The proportional column current is then translated back to the Boolean domain for further digital processing. The IMBUE architecture is inspired by the Tsetlin Machine (TM), an emerging ML algorithm based on intrinsically Boolean logic. The IMBUE architecture demonstrates significant performance improvements over binarized convolutional neural networks and digital TM in-memory implementations, achieving up to a 12.99x and 5.28x increase, respectively.
Logic Locking at the Frontiers of Machine Learning: A Survey on Developments and Opportunities
Jul 21, 2021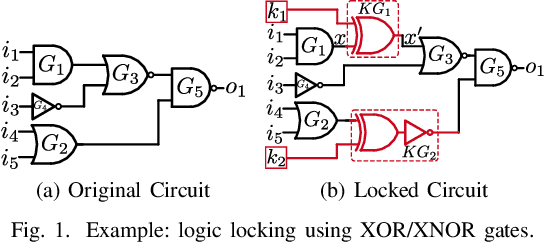



In the past decade, a lot of progress has been made in the design and evaluation of logic locking; a premier technique to safeguard the integrity of integrated circuits throughout the electronics supply chain. However, the widespread proliferation of machine learning has recently introduced a new pathway to evaluating logic locking schemes. This paper summarizes the recent developments in logic locking attacks and countermeasures at the frontiers of contemporary machine learning models. Based on the presented work, the key takeaways, opportunities, and challenges are highlighted to offer recommendations for the design of next-generation logic locking.
Deceptive Logic Locking for Hardware Integrity Protection against Machine Learning Attacks
Jul 19, 2021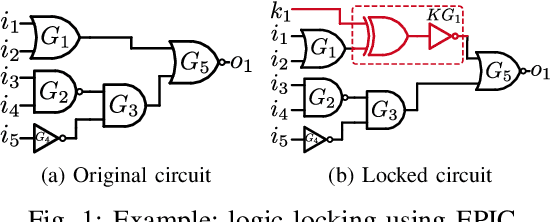

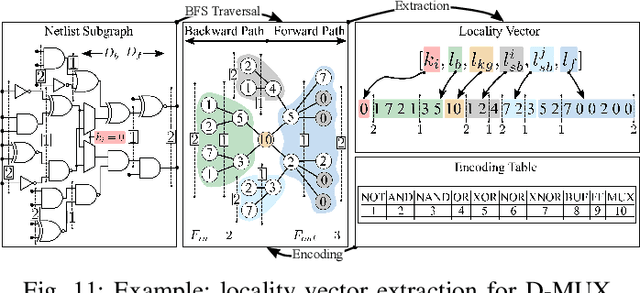
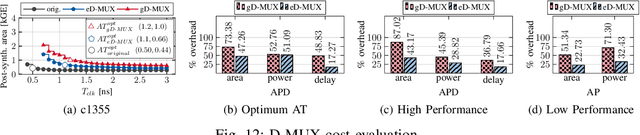
Logic locking has emerged as a prominent key-driven technique to protect the integrity of integrated circuits. However, novel machine-learning-based attacks have recently been introduced to challenge the security foundations of locking schemes. These attacks are able to recover a significant percentage of the key without having access to an activated circuit. This paper address this issue through two focal points. First, we present a theoretical model to test locking schemes for key-related structural leakage that can be exploited by machine learning. Second, based on the theoretical model, we introduce D-MUX: a deceptive multiplexer-based logic-locking scheme that is resilient against structure-exploiting machine learning attacks. Through the design of D-MUX, we uncover a major fallacy in existing multiplexer-based locking schemes in the form of a structural-analysis attack. Finally, an extensive cost evaluation of D-MUX is presented. To the best of our knowledge, D-MUX is the first machine-learning-resilient locking scheme capable of protecting against all known learning-based attacks. Hereby, the presented work offers a starting point for the design and evaluation of future-generation logic locking in the era of machine learning.
Challenging the Security of Logic Locking Schemes in the Era of Deep Learning: A Neuroevolutionary Approach
Nov 30, 2020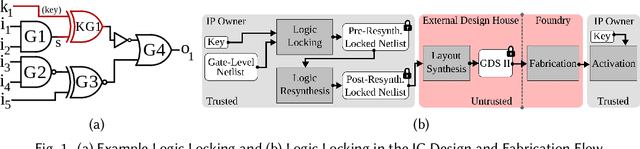

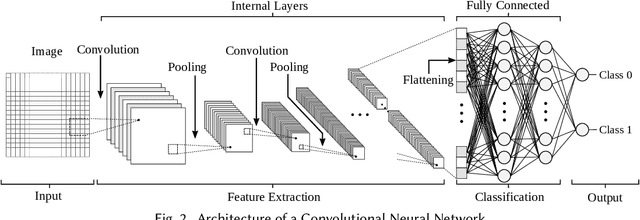
Logic locking is a prominent technique to protect the integrity of hardware designs throughout the integrated circuit design and fabrication flow. However, in recent years, the security of locking schemes has been thoroughly challenged by the introduction of various deobfuscation attacks. As in most research branches, deep learning is being introduced in the domain of logic locking as well. Therefore, in this paper we present SnapShot: a novel attack on logic locking that is the first of its kind to utilize artificial neural networks to directly predict a key bit value from a locked synthesized gate-level netlist without using a golden reference. Hereby, the attack uses a simpler yet more flexible learning model compared to existing work. Two different approaches are evaluated. The first approach is based on a simple feedforward fully connected neural network. The second approach utilizes genetic algorithms to evolve more complex convolutional neural network architectures specialized for the given task. The attack flow offers a generic and customizable framework for attacking locking schemes using machine learning techniques. We perform an extensive evaluation of SnapShot for two realistic attack scenarios, comprising both reference benchmark circuits as well as silicon-proven RISC-V core modules. The evaluation results show that SnapShot achieves an average key prediction accuracy of 82.60% for the selected attack scenario, with a significant performance increase of 10.49 percentage points compared to the state of the art. Moreover, SnapShot outperforms the existing technique on all evaluated benchmarks. The results indicate that the security foundation of common logic locking schemes is build on questionable assumptions. The conclusions of the evaluation offer insights into the challenges of designing future logic locking schemes that are resilient to machine learning attacks.
ExPAN(N)D: Exploring Posits for Efficient Artificial Neural Network Design in FPGA-based Systems
Oct 27, 2020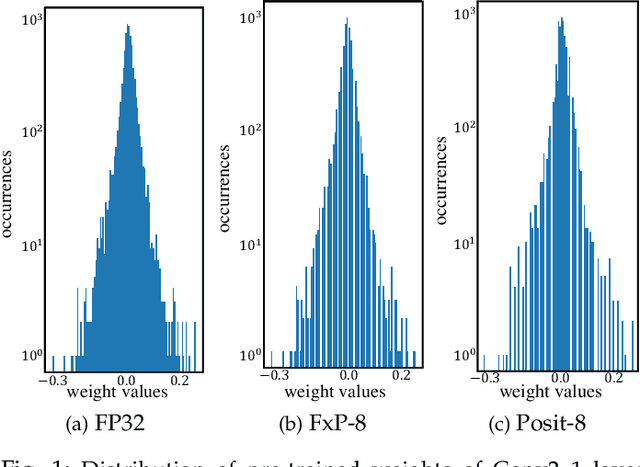
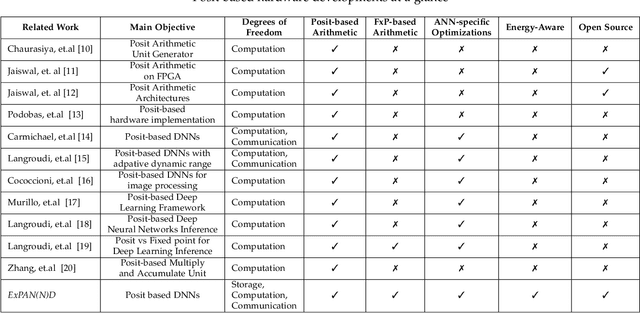
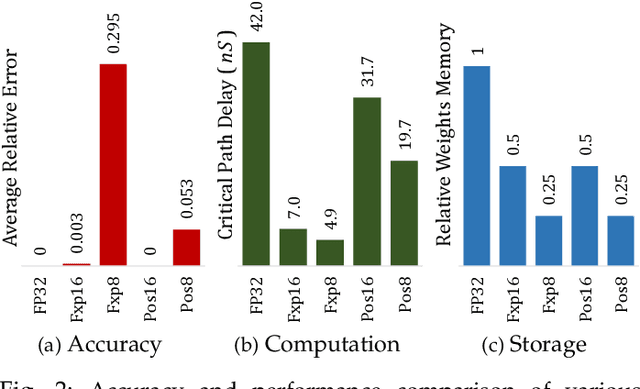
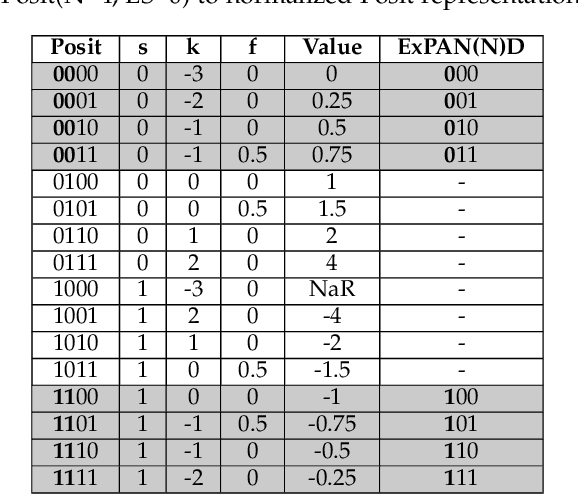
The recent advances in machine learning, in general, and Artificial Neural Networks (ANN), in particular, has made smart embedded systems an attractive option for a larger number of application areas. However, the high computational complexity, memory footprints, and energy requirements of machine learning models hinder their deployment on resource-constrained embedded systems. Most state-of-the-art works have considered this problem by proposing various low bit-width data representation schemes, optimized arithmetic operators' implementations, and different complexity reduction techniques such as network pruning. To further elevate the implementation gains offered by these individual techniques, there is a need to cross-examine and combine these techniques' unique features. This paper presents ExPAN(N)D, a framework to analyze and ingather the efficacy of the Posit number representation scheme and the efficiency of fixed-point arithmetic implementations for ANNs. The Posit scheme offers a better dynamic range and higher precision for various applications than IEEE $754$ single-precision floating-point format. However, due to the dynamic nature of the various fields of the Posit scheme, the corresponding arithmetic circuits have higher critical path delay and resource requirements than the single-precision-based arithmetic units. Towards this end, we propose a novel Posit to fixed-point converter for enabling high-performance and energy-efficient hardware implementations for ANNs with minimal drop in the output accuracy. We also propose a modified Posit-based representation to store the trained parameters of a network. Compared to an $8$-bit fixed-point-based inference accelerator, our proposed implementation offers $\approx46\%$ and $\approx18\%$ reductions in the storage requirements of the parameters and energy consumption of the MAC units, respectively.