 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Freezing: Sparse Tuning Enhances Plasticity in Continual Learning with Pre-Trained Models
May 26, 2025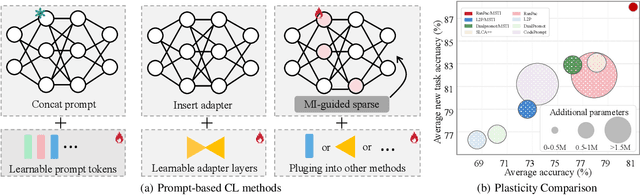



Continual Learning with Pre-trained Models holds great promise for efficient adaptation across sequential tasks. However, most existing approaches freeze PTMs and rely on auxiliary modules like prompts or adapters, limiting model plasticity and leading to suboptimal generalization when facing significant distribution shifts. While full fine-tuning can improve adaptability, it risks disrupting crucial pre-trained knowledge. In this paper, we propose Mutual Information-guided Sparse Tuning (MIST), a plug-and-play method that selectively updates a small subset of PTM parameters, less than 5%, based on sensitivity to mutual information objectives. MIST enables effective task-specific adaptation while preserving generalization. To further reduce interference, we introduce strong sparsity regularization by randomly dropping gradients during tuning, resulting in fewer than 0.5% of parameters being updated per step. Applied before standard freeze-based methods, MIST consistently boosts performance across diverse continual learning benchmarks. Experiments show that integrating our method into multiple baselines yields significant performance gains. Our code is available at https://github.com/zhwhu/MIST.
An All-digital 65-nm Tsetlin Machine Image Classification Accelerator with 8.6 nJ per MNIST Frame at 60.3k Frames per Second
Jan 31, 2025



We present an all-digital programmable machine learning accelerator chip for image classification, underpinning on the Tsetlin machine (TM) principles. The TM is a machine learning algorithm founded on propositional logic, utilizing sub-pattern recognition expressions called clauses. The accelerator implements the coalesced TM version with convolution, and classifies booleanized images of 28$\times$28 pixels with 10 categories. A configuration with 128 clauses is used in a highly parallel architecture. Fast clause evaluation is obtained by keeping all clause weights and Tsetlin automata (TA) action signals in registers. The chip is implemented in a 65 nm low-leakage CMOS technology, and occupies an active area of 2.7mm$^2$. At a clock frequency of 27.8 MHz, the accelerator achieves 60.3k classifications per second, and consumes 8.6 nJ per classification. The latency for classifying a single image is 25.4 $\mu$s which includes system timing overhead. The accelerator achieves 97.42%, 84.54% and 82.55% test accuracies for the datasets MNIST, Fashion-MNIST and Kuzushiji-MNIST, respectively, matching the TM software models.
Constructing Enhanced Mutual Information for Online Class-Incremental Learning
Jul 26, 2024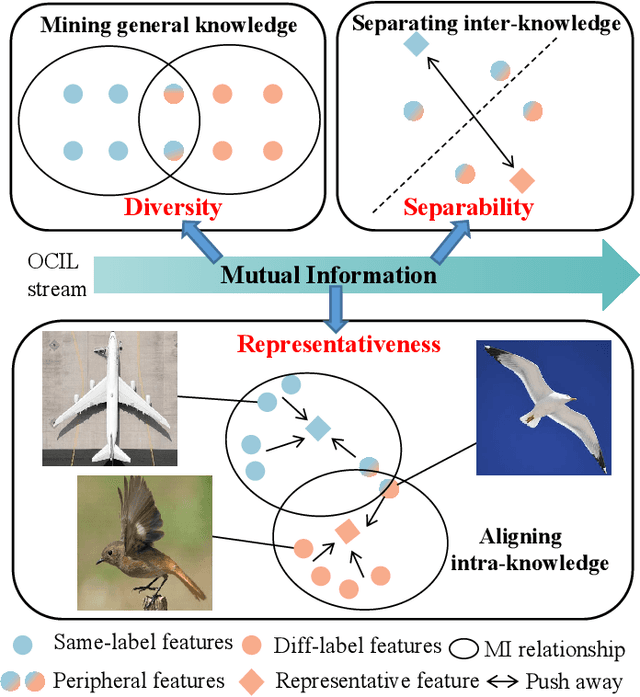
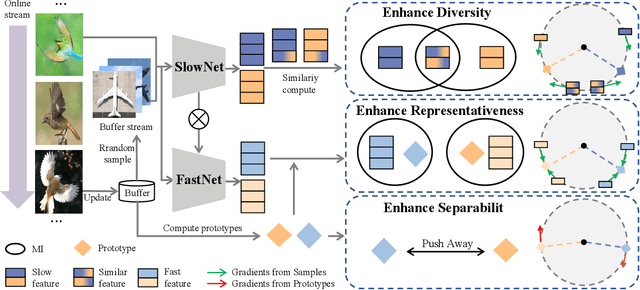
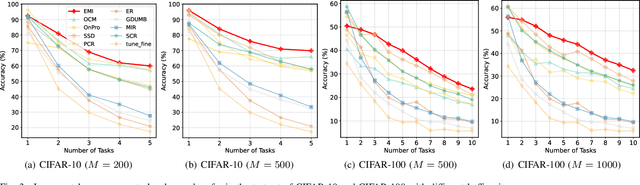
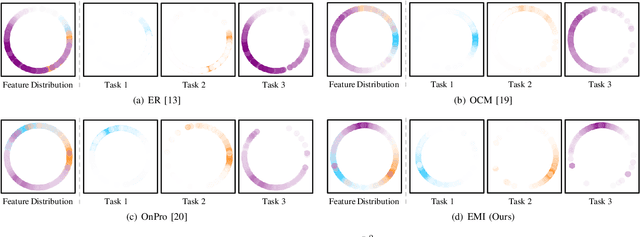
Online Class-Incremental continual Learning (OCIL) addresses the challenge of continuously learning from a single-channel data stream, adapting to new tasks while mitigating catastrophic forgetting. Recently, Mutual Information (MI)-based methods have shown promising performance in OCIL. However, existing MI-based methods treat various knowledge components in isolation, ignoring the knowledge confusion across tasks. This narrow focus on simple MI knowledge alignment may lead to old tasks being easily forgotten with the introduction of new tasks, risking the loss of common parts between past and present knowledge.To address this, we analyze the MI relationships from the perspectives of diversity, representativeness, and separability, and propose an Enhanced Mutual Information (EMI) method based on knwoledge decoupling. EMI consists of Diversity Mutual Information (DMI), Representativeness Mutual Information (RMI) and Separability Mutual Information (SMI). DMI diversifies intra-class sample features by considering the similarity relationships among inter-class sample features to enable the network to learn more general knowledge. RMI summarizes representative features for each category and aligns sample features with these representative features, making the intra-class sample distribution more compact. SMI establishes MI relationships for inter-class representative features, enhancing the stability of representative features while increasing the distinction between inter-class representative features, thus creating clear boundaries between class. Extensive experimental results on widely used benchmark datasets demonstrate the superior performance of EMI over state-of-the-art baseline methods.
IMBUE: In-Memory Boolean-to-CUrrent Inference ArchitecturE for Tsetlin Machines
May 22, 2023



In-memory computing for Machine Learning (ML) applications remedies the von Neumann bottlenecks by organizing computation to exploit parallelism and locality. Non-volatile memory devices such as Resistive RAM (ReRAM) offer integrated switching and storage capabilities showing promising performance for ML applications. However, ReRAM devices have design challenges, such as non-linear digital-analog conversion and circuit overheads. This paper proposes an In-Memory Boolean-to-Current Inference Architecture (IMBUE) that uses ReRAM-transistor cells to eliminate the need for such conversions. IMBUE processes Boolean feature inputs expressed as digital voltages and generates parallel current paths based on resistive memory states. The proportional column current is then translated back to the Boolean domain for further digital processing. The IMBUE architecture is inspired by the Tsetlin Machine (TM), an emerging ML algorithm based on intrinsically Boolean logic. The IMBUE architecture demonstrates significant performance improvements over binarized convolutional neural networks and digital TM in-memory implementations, achieving up to a 12.99x and 5.28x increase, respectively.