 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-Prompt: Cross-Modal Prompt Tuning for Continual Visual Question Answering
May 26, 2025Continual Visual Question Answering (CVQA) based on pre-trained models(PTMs) has achieved promising progress by leveraging prompt tuning to enable continual multi-modal learning. However, most existing methods adopt cross-modal prompt isolation, constructing visual and textual prompts separately, which exacerbates modality imbalance and leads to degraded performance over time. To tackle this issue, we propose MM-Prompt, a novel framework incorporating cross-modal prompt query and cross-modal prompt recovery. The former enables balanced prompt selection by incorporating cross-modal signals during query formation, while the latter promotes joint prompt reconstruction through iterative cross-modal interactions, guided by an alignment loss to prevent representational drift. Extensive experiments show that MM-Prompt surpasses prior approaches in accuracy and knowledge retention, while maintaining balanced modality engagement throughout continual learning.
Beyond Freezing: Sparse Tuning Enhances Plasticity in Continual Learning with Pre-Trained Models
May 26, 2025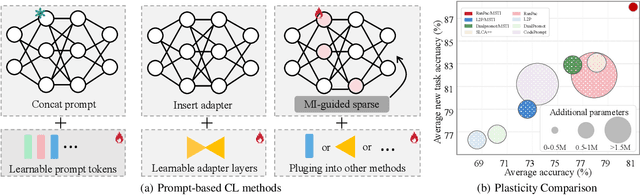



Continual Learning with Pre-trained Models holds great promise for efficient adaptation across sequential tasks. However, most existing approaches freeze PTMs and rely on auxiliary modules like prompts or adapters, limiting model plasticity and leading to suboptimal generalization when facing significant distribution shifts. While full fine-tuning can improve adaptability, it risks disrupting crucial pre-trained knowledge. In this paper, we propose Mutual Information-guided Sparse Tuning (MIST), a plug-and-play method that selectively updates a small subset of PTM parameters, less than 5%, based on sensitivity to mutual information objectives. MIST enables effective task-specific adaptation while preserving generalization. To further reduce interference, we introduce strong sparsity regularization by randomly dropping gradients during tuning, resulting in fewer than 0.5% of parameters being updated per step. Applied before standard freeze-based methods, MIST consistently boosts performance across diverse continual learning benchmarks. Experiments show that integrating our method into multiple baselines yields significant performance gains. Our code is available at https://github.com/zhwhu/MIST.
Beyond Background Shift: Rethinking Instance Replay in Continual Semantic Segmentation
Mar 28, 2025



In this work, we focus on continual semantic segmentation (CSS), where segmentation networks are required to continuously learn new classes without erasing knowledge of previously learned ones. Although storing images of old classes and directly incorporating them into the training of new models has proven effective in mitigating catastrophic forgetting in classification tasks, this strategy presents notable limitations in CSS. Specifically, the stored and new images with partial category annotations leads to confusion between unannotated categories and the background, complicating model fitting. To tackle this issue, this paper proposes a novel Enhanced Instance Replay (EIR) method, which not only preserves knowledge of old classes while simultaneously eliminating background confusion by instance storage of old classes, but also mitigates background shifts in the new images by integrating stored instances with new images. By effectively resolving background shifts in both stored and new images, EIR alleviates catastrophic forgetting in the CSS task, thereby enhancing the model's capacity for CSS. Experimental results validate the efficacy of our approach, which significantly outperforms state-of-the-art CSS methods.
Conformal Uncertainty Indicator for Continual Test-Time Adaptation
Feb 05, 2025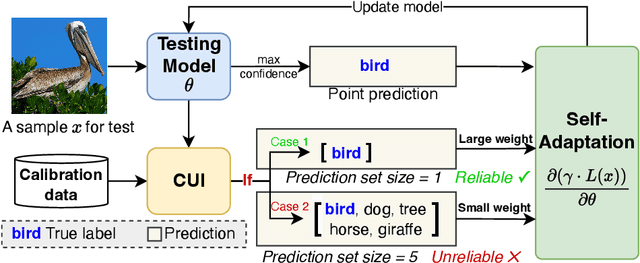
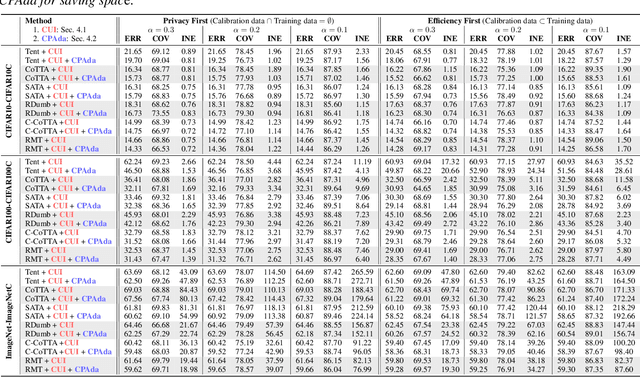
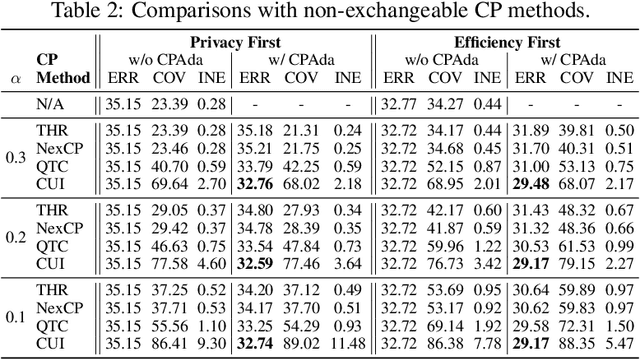
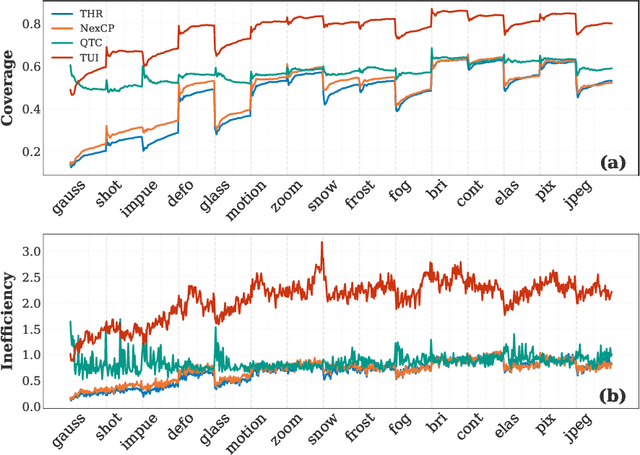
Continual Test-Time Adaptation (CTTA) aims to adapt models to sequentially changing domains during testing, relying on pseudo-labels for self-adaptation. However, incorrect pseudo-labels can accumulate, leading to performance degradation. To address this, we propose a Conformal Uncertainty Indicator (CUI) for CTTA, leveraging Conformal Prediction (CP) to generate prediction sets that include the true label with a specified coverage probability. Since domain shifts can lower the coverage than expected, making CP unreliable, we dynamically compensate for the coverage by measuring both domain and data differences. Reliable pseudo-labels from CP are then selectively utilized to enhance adaptation. Experiments confirm that CUI effectively estimates uncertainty and improves adaptation performance across various existing CTTA methods.
CALA: A Class-Aware Logit Adapter for Few-Shot Class-Incremental Learning
Dec 17, 2024



Few-Shot Class-Incremental Learning (FSCIL) defines a practical but challenging task where models are required to continuously learn novel concepts with only a few training samples. Due to data scarcity, existing FSCIL methods resort to training a backbone with abundant base data and then keeping it frozen afterward. However, the above operation often causes the backbone to overfit to base classes while overlooking the novel ones, leading to severe confusion between them. To address this issue, we propose Class-Aware Logit Adapter (CALA). Our method involves a lightweight adapter that learns to rectify biased predictions through a pseudo-incremental learning paradigm. In the real FSCIL process, we use the learned adapter to dynamically generate robust balancing factors. These factors can adjust confused novel instances back to their true label space based on their similarity to base classes. Specifically, when confusion is more likely to occur in novel instances that closely resemble base classes, greater rectification is required. Notably, CALA operates on the classifier level, preserving the original feature space, thus it can be flexibly plugged into most of the existing FSCIL works for improved performance. Experiments on three benchmark datasets consistently validate the effectiveness and flexibility of CALA. Codes will be available upon acceptance.
Rebalancing Multi-Label Class-Incremental Learning
Aug 22, 2024Multi-label class-incremental learning (MLCIL) is essential for real-world multi-label applications, allowing models to learn new labels while retaining previously learned knowledge continuously. However, recent MLCIL approaches can only achieve suboptimal performance due to the oversight of the positive-negative imbalance problem, which manifests at both the label and loss levels because of the task-level partial label issue. The imbalance at the label level arises from the substantial absence of negative labels, while the imbalance at the loss level stems from the asymmetric contributions of the positive and negative loss parts to the optimization. To address the issue above, we propose a Rebalance framework for both the Loss and Label levels (RebLL), which integrates two key modules: asymmetric knowledge distillation (AKD) and online relabeling (OR). AKD is proposed to rebalance at the loss level by emphasizing the negative label learning in classification loss and down-weighting the contribution of overconfident predictions in distillation loss. OR is designed for label rebalance, which restores the original class distribution in memory by online relabeling the missing classes. Our comprehensive experiments on the PASCAL VOC and MS-COCO datasets demonstrate that this rebalancing strategy significantly improves performance, achieving new state-of-the-art results even with a vanilla CNN backbone.
Constructing Enhanced Mutual Information for Online Class-Incremental Learning
Jul 26, 2024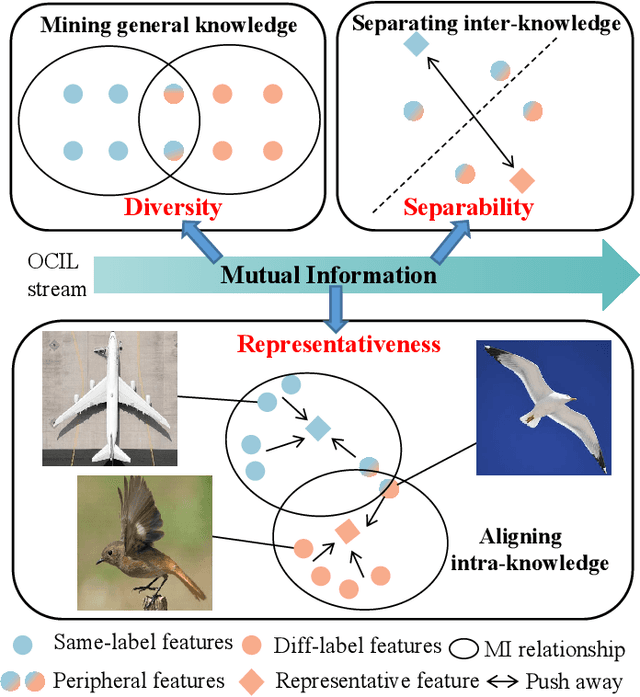
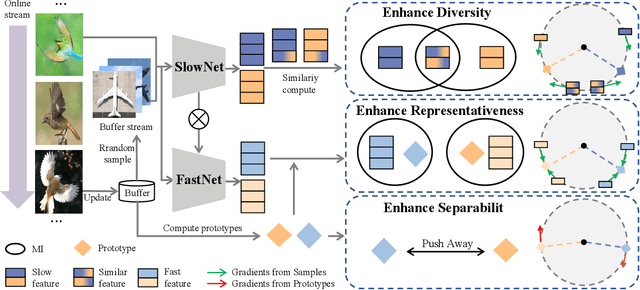
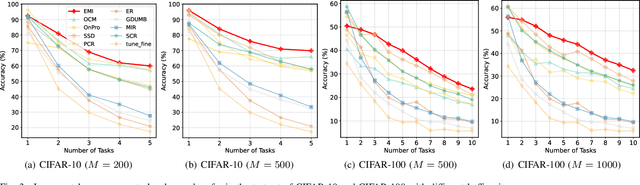
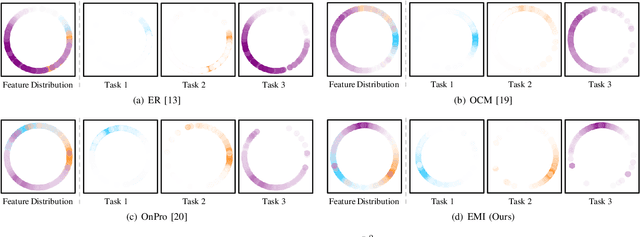
Online Class-Incremental continual Learning (OCIL) addresses the challenge of continuously learning from a single-channel data stream, adapting to new tasks while mitigating catastrophic forgetting. Recently, Mutual Information (MI)-based methods have shown promising performance in OCIL. However, existing MI-based methods treat various knowledge components in isolation, ignoring the knowledge confusion across tasks. This narrow focus on simple MI knowledge alignment may lead to old tasks being easily forgotten with the introduction of new tasks, risking the loss of common parts between past and present knowledge.To address this, we analyze the MI relationships from the perspectives of diversity, representativeness, and separability, and propose an Enhanced Mutual Information (EMI) method based on knwoledge decoupling. EMI consists of Diversity Mutual Information (DMI), Representativeness Mutual Information (RMI) and Separability Mutual Information (SMI). DMI diversifies intra-class sample features by considering the similarity relationships among inter-class sample features to enable the network to learn more general knowledge. RMI summarizes representative features for each category and aligns sample features with these representative features, making the intra-class sample distribution more compact. SMI establishes MI relationships for inter-class representative features, enhancing the stability of representative features while increasing the distinction between inter-class representative features, thus creating clear boundaries between class. Extensive experimental results on widely used benchmark datasets demonstrate the superior performance of EMI over state-of-the-art baseline methods.
Towards stable training of parallel continual learning
Jul 11, 2024



Parallel Continual Learning (PCL) tasks investigate the training methods for continual learning with multi-source input, where data from different tasks are learned as they arrive. PCL offers high training efficiency and is well-suited for complex multi-source data systems, such as autonomous vehicles equipped with multiple sensors. However, at any time, multiple tasks need to be trained simultaneously, leading to severe training instability in PCL. This instability manifests during both forward and backward propagation, where features are entangled and gradients are conflict. This paper introduces Stable Parallel Continual Learning (SPCL), a novel approach that enhances the training stability of PCL for both forward and backward propagation. For the forward propagation, we apply Doubly-block Toeplit (DBT) Matrix based orthogonality constraints to network parameters to ensure stable and consistent propagation. For the backward propagation, we employ orthogonal decomposition for gradient management stabilizes backpropagation and mitigates gradient conflicts across tasks. By optimizing gradients by ensuring orthogonality and minimizing the condition number, SPCL effectively stabilizing the gradient descent in complex optimization tasks. Experimental results demonstrate that SPCL outperforms state-of-the-art methjods and achieve better training stability.
Parameter-Selective Continual Test-Time Adaptation
Jul 02, 2024



Continual Test-Time Adaptation (CTTA) aims to adapt a pretrained model to ever-changing environments during the test time under continuous domain shifts. Most existing CTTA approaches are based on the Mean Teacher (MT) structure, which contains a student and a teacher model, where the student is updated using the pseudo-labels from the teacher model, and the teacher is then updated by exponential moving average strategy. However, these methods update the MT model indiscriminately on all parameters of the model. That is, some critical parameters involving sharing knowledge across different domains may be erased, intensifying error accumulation and catastrophic forgetting. In this paper, we introduce Parameter-Selective Mean Teacher (PSMT) method, which is capable of effectively updating the critical parameters within the MT network under domain shifts. First, we introduce a selective distillation mechanism in the student model, which utilizes past knowledge to regularize novel knowledge, thereby mitigating the impact of error accumulation. Second, to avoid catastrophic forgetting, in the teacher model, we create a mask through Fisher information to selectively update parameters via exponential moving average, with preservation measures applied to crucial parameters. Extensive experimental results verify that PSMT outperforms state-of-the-art methods across multiple benchmark datasets. Our code is available at \url{https://github.com/JiaxuTian/PSMT}.
Less is More: Pseudo-Label Filtering for Continual Test-Time Adaptation
Jun 03, 2024Continual Test-Time Adaptation (CTTA) aims to adapt a pre-trained model to a sequence of target domains during the test phase without accessing the source data. To adapt to unlabeled data from unknown domains, existing methods rely on constructing pseudo-labels for all samples and updating the model through self-training. However, these pseudo-labels often involve noise, leading to insufficient adaptation. To improve the quality of pseudo-labels, we propose a pseudo-label selection method for CTTA, called Pseudo Labeling Filter (PLF). The key idea of PLF is to keep selecting appropriate thresholds for pseudo-labels and identify reliable ones for self-training. Specifically, we present three principles for setting thresholds during continuous domain learning, including initialization, growth and diversity. Based on these principles, we design Self-Adaptive Thresholding to filter pseudo-labels. Additionally, we introduce a Class Prior Alignment (CPA) method to encourage the model to make diverse predictions for unknown domain samples. Through extensive experiments, PLF outperforms current state-of-the-art methods, proving its effectiveness in CTTA.