 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAD: Heterogeneity-Aware Distillation for Lifelong Heterogeneous Learning
Mar 27, 2026Lifelong learning aims to preserve knowledge acquired from previous tasks while incorporating knowledge from a sequence of new tasks. However, most prior work explores only streams of homogeneous tasks (\textit{e.g.}, only classification tasks) and neglects the scenario of learning across heterogeneous tasks that possess different structures of outputs. In this work, we formalize this broader setting as lifelong heterogeneous learning (LHL). Departing from conventional lifelong learning, the task sequence of LHL spans different task types, and the learner needs to retain heterogeneous knowledge for different output space structures. To instantiate the LHL, we focus on LHL in the context of dense prediction (LHL4DP), a realistic and challenging scenario. To this end, we propose the Heterogeneity-Aware Distillation (HAD) method, an exemplar-free approach that preserves previously gained heterogeneous knowledge by self-distillation in each training phase. The proposed HAD comprises two complementary components, including a distribution-balanced heterogeneity-aware distillation loss to alleviate the global imbalance of prediction distribution and a salience-guided heterogeneity-aware distillation loss that concentrates learning on informative edge pixels extracted with the Sobel operator. Extensive experiments demonstrate that the proposed HAD method significantly outperforms existing methods in this new scenario.
VISA: Group-wise Visual Token Selection and Aggregation via Graph Summarization for Efficient MLLMs Inference
Aug 25, 2025In this study, we introduce a novel method called group-wise \textbf{VI}sual token \textbf{S}election and \textbf{A}ggregation (VISA) to address the issue of inefficient inference stemming from excessive visual tokens in multimoal large language models (MLLMs). Compared with previous token pruning approaches, our method can preserve more visual information while compressing visual tokens. We first propose a graph-based visual token aggregation (VTA) module. VTA treats each visual token as a node, forming a graph based on semantic similarity among visual tokens. It then aggregates information from removed tokens into kept tokens based on this graph, producing a more compact visual token representation. Additionally, we introduce a group-wise token selection strategy (GTS) to divide visual tokens into kept and removed ones, guided by text tokens from the final layers of each group. This strategy progressively aggregates visual information, enhancing the stability of the visual information extraction process. We conduct comprehensive experiments on LLaVA-1.5, LLaVA-NeXT, and Video-LLaVA across various benchmarks to validate the efficacy of VISA. Our method consistently outperforms previous methods, achieving a superior trade-off between model performance and inference speed. The code is available at https://github.com/mobiushy/VISA.
CALA: A Class-Aware Logit Adapter for Few-Shot Class-Incremental Learning
Dec 17, 2024



Few-Shot Class-Incremental Learning (FSCIL) defines a practical but challenging task where models are required to continuously learn novel concepts with only a few training samples. Due to data scarcity, existing FSCIL methods resort to training a backbone with abundant base data and then keeping it frozen afterward. However, the above operation often causes the backbone to overfit to base classes while overlooking the novel ones, leading to severe confusion between them. To address this issue, we propose Class-Aware Logit Adapter (CALA). Our method involves a lightweight adapter that learns to rectify biased predictions through a pseudo-incremental learning paradigm. In the real FSCIL process, we use the learned adapter to dynamically generate robust balancing factors. These factors can adjust confused novel instances back to their true label space based on their similarity to base classes. Specifically, when confusion is more likely to occur in novel instances that closely resemble base classes, greater rectification is required. Notably, CALA operates on the classifier level, preserving the original feature space, thus it can be flexibly plugged into most of the existing FSCIL works for improved performance. Experiments on three benchmark datasets consistently validate the effectiveness and flexibility of CALA. Codes will be available upon acceptance.
SAFE: Slow and Fast Parameter-Efficient Tuning for Continual Learning with Pre-Trained Models
Nov 04, 2024



Continual learning aims to incrementally acquire new concepts in data streams while resisting forgetting previous knowledge. With the rise of powerful pre-trained models (PTMs), there is a growing interest in training incremental learning systems using these foundation models, rather than learning from scratch. Existing works often view PTMs as a strong initial point and directly apply parameter-efficient tuning (PET) in the first session for adapting to downstream tasks. In the following sessions, most methods freeze model parameters for tackling forgetting issues. However, applying PET directly to downstream data cannot fully explore the inherent knowledge in PTMs. Additionally, freezing the parameters in incremental sessions hinders models' plasticity to novel concepts not covered in the first session. To solve the above issues, we propose a Slow And Fast parameter-Efficient tuning (SAFE) framework. In particular, to inherit general knowledge from foundation models, we include a transfer loss function by measuring the correlation between the PTM and the PET-applied model. After calibrating in the first session, the slow efficient tuning parameters can capture more informative features, improving generalization to incoming classes. Moreover, to further incorporate novel concepts, we strike a balance between stability and plasticity by fixing slow efficient tuning parameters and continuously updating the fast ones. Specifically, a cross-classification loss with feature alignment is proposed to circumvent catastrophic forgetting. During inference, we introduce an entropy-based aggregation strategy to dynamically utilize the complementarity in the slow and fast learners. Extensive experiments on seven benchmark datasets verify the effectiveness of our method by significantly surpassing the state-of-the-art.
Overcoming Domain Drift in Online Continual Learning
May 15, 2024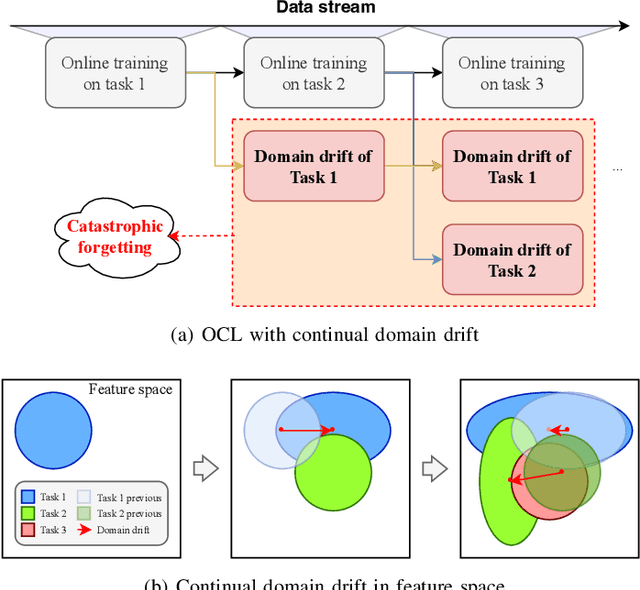
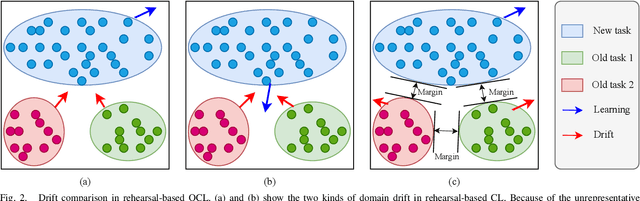
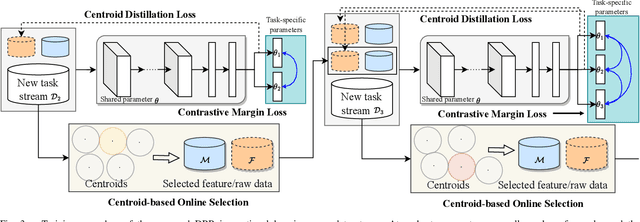
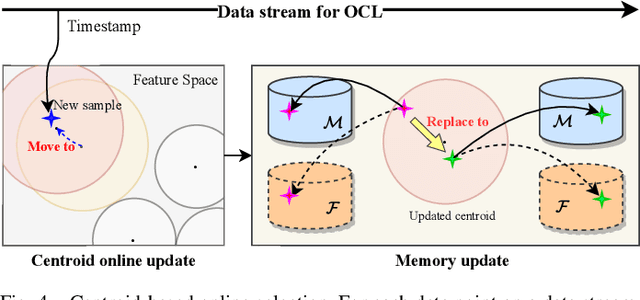
Online Continual Learning (OCL) empowers machine learning models to acquire new knowledge online across a sequence of tasks. However, OCL faces a significant challenge: catastrophic forgetting, wherein the model learned in previous tasks is substantially overwritten upon encountering new tasks, leading to a biased forgetting of prior knowledge. Moreover, the continual doman drift in sequential learning tasks may entail the gradual displacement of the decision boundaries in the learned feature space, rendering the learned knowledge susceptible to forgetting. To address the above problem, in this paper, we propose a novel rehearsal strategy, termed Drift-Reducing Rehearsal (DRR), to anchor the domain of old tasks and reduce the negative transfer effects. First, we propose to select memory for more representative samples guided by constructed centroids in a data stream. Then, to keep the model from domain chaos in drifting, a two-level angular cross-task Contrastive Margin Loss (CML) is proposed, to encourage the intra-class and intra-task compactness, and increase the inter-class and inter-task discrepancy. Finally, to further suppress the continual domain drift, we present an optional Centorid Distillation Loss (CDL) on the rehearsal memory to anchor the knowledge in feature space for each previous old task. Extensive experimental results on four benchmark datasets validate that the proposed DRR can effectively mitigate the continual domain drift and achieve the state-of-the-art (SOTA) performance in OCL.