 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALA: A Class-Aware Logit Adapter for Few-Shot Class-Incremental Learning
Dec 17, 2024



Few-Shot Class-Incremental Learning (FSCIL) defines a practical but challenging task where models are required to continuously learn novel concepts with only a few training samples. Due to data scarcity, existing FSCIL methods resort to training a backbone with abundant base data and then keeping it frozen afterward. However, the above operation often causes the backbone to overfit to base classes while overlooking the novel ones, leading to severe confusion between them. To address this issue, we propose Class-Aware Logit Adapter (CALA). Our method involves a lightweight adapter that learns to rectify biased predictions through a pseudo-incremental learning paradigm. In the real FSCIL process, we use the learned adapter to dynamically generate robust balancing factors. These factors can adjust confused novel instances back to their true label space based on their similarity to base classes. Specifically, when confusion is more likely to occur in novel instances that closely resemble base classes, greater rectification is required. Notably, CALA operates on the classifier level, preserving the original feature space, thus it can be flexibly plugged into most of the existing FSCIL works for improved performance. Experiments on three benchmark datasets consistently validate the effectiveness and flexibility of CALA. Codes will be available upon acceptance.
Rebalancing Multi-Label Class-Incremental Learning
Aug 22, 2024Multi-label class-incremental learning (MLCIL) is essential for real-world multi-label applications, allowing models to learn new labels while retaining previously learned knowledge continuously. However, recent MLCIL approaches can only achieve suboptimal performance due to the oversight of the positive-negative imbalance problem, which manifests at both the label and loss levels because of the task-level partial label issue. The imbalance at the label level arises from the substantial absence of negative labels, while the imbalance at the loss level stems from the asymmetric contributions of the positive and negative loss parts to the optimization. To address the issue above, we propose a Rebalance framework for both the Loss and Label levels (RebLL), which integrates two key modules: asymmetric knowledge distillation (AKD) and online relabeling (OR). AKD is proposed to rebalance at the loss level by emphasizing the negative label learning in classification loss and down-weighting the contribution of overconfident predictions in distillation loss. OR is designed for label rebalance, which restores the original class distribution in memory by online relabeling the missing classes. Our comprehensive experiments on the PASCAL VOC and MS-COCO datasets demonstrate that this rebalancing strategy significantly improves performance, achieving new state-of-the-art results even with a vanilla CNN backbone.
Confidence Self-Calibration for Multi-Label Class-Incremental Learning
Mar 19, 2024



The partial label challenge in Multi-Label Class-Incremental Learning (MLCIL) arises when only the new classes are labeled during training, while past and future labels remain unavailable. This issue leads to a proliferation of false-positive errors due to erroneously high confidence multi-label predictions, exacerbating catastrophic forgetting within the disjoint label space. In this paper, we aim to refine multi-label confidence calibration in MLCIL and propose a Confidence Self-Calibration (CSC) approach. Firstly, for label relationship calibration, we introduce a class-incremental graph convolutional network that bridges the isolated label spaces by constructing learnable, dynamically extended label relationship graph. Then, for confidence calibration, we present a max-entropy regularization for each multi-label increment, facilitating confidence self-calibration through the penalization of over-confident output distributions. Our approach attains new state-of-the-art results in MLCIL tasks on both MS-COCO and PASCAL VOC datasets, with the calibration of label confidences confirmed through our methodology.
Variational Continual Test-Time Adaptation
Feb 13, 2024



The prior drift is crucial in Continual Test-Time Adaptation (CTTA) methods that only use unlabeled test data, as it can cause significant error propagation. In this paper, we introduce VCoTTA, a variational Bayesian approach to measure uncertainties in CTTA. At the source stage, we transform a pre-trained deterministic model into a Bayesian Neural Network (BNN) via a variational warm-up strategy, injecting uncertainties into the model. During the testing time, we employ a mean-teacher update strategy using variational inference for the student model and exponential moving average for the teacher model. Our novel approach updates the student model by combining priors from both the source and teacher models. The evidence lower bound is formulated as the cross-entropy between the student and teacher models, along with the Kullback-Leibler (KL) divergence of the prior mixture. Experimental results on three datasets demonstrate the method's effectiveness in mitigating prior drift within the CTTA framework.
Multi-Label Continual Learning using Augmented Graph Convolutional Network
Nov 27, 2022



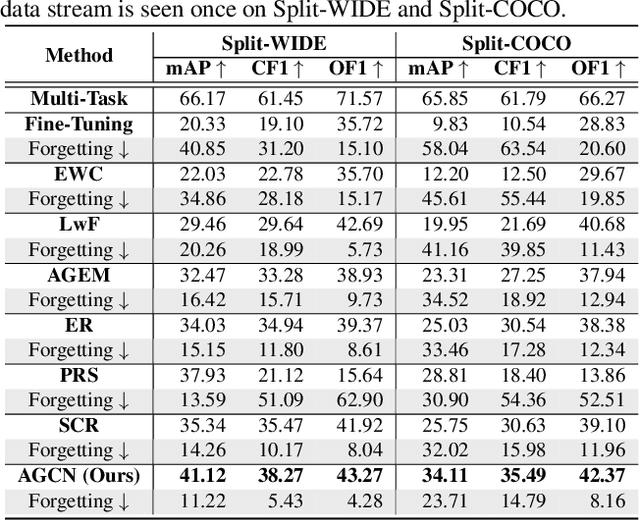
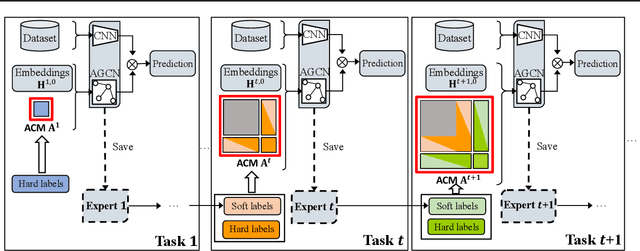
Multi-Label Continual Learning (MLCL) builds a class-incremental framework in a sequential multi-label image recognition data stream. The critical challenges of MLCL are the construction of label relationships on past-missing and future-missing partial labels of training data and the catastrophic forgetting on old classes, resulting in poor generalization. To solve the problems, the study proposes an Augmented Graph Convolutional Network (AGCN++) that can construct the cross-task label relationships in MLCL and sustain catastrophic forgetting. First, we build an Augmented Correlation Matrix (ACM) across all seen classes, where the intra-task relationships derive from the hard label statistics. In contrast, the inter-task relationships leverage hard and soft labels from data and a constructed expert network. Then, we propose a novel partial label encoder (PLE) for MLCL, which can extract dynamic class representation for each partial label image as graph nodes and help generate soft labels to create a more convincing ACM and suppress forgetting. Last, to suppress the forgetting of label dependencies across old tasks, we propose a relationship-preserving constrainter to construct label relationships. The inter-class topology can be augmented automatically, which also yields effective class representations. The proposed method is evaluated using two multi-label image benchmarks. The experimental results show that the proposed way is effective for MLCL image recognition and can build convincing correlations across tasks even if the labels of previous tasks are missing.
Class-Incremental Lifelong Learning in Multi-Label Classification
Jul 16, 2022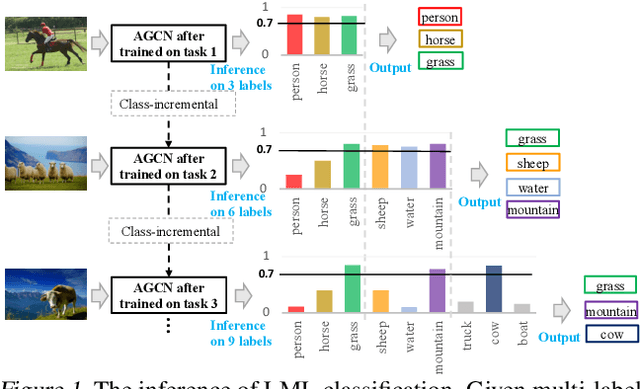
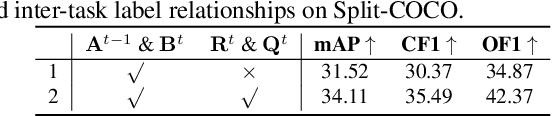
Existing class-incremental lifelong learning studies only the data is with single-label, which limits its adaptation to multi-label data. This paper studies Lifelong Multi-Label (LML) classification, which builds an online class-incremental classifier in a sequential multi-label classification data stream. Training on the data with Partial Labels in LML classification may result in more serious Catastrophic Forgetting in old classes. To solve the problem, the study proposes an Augmented Graph Convolutional Network (AGCN) with a built Augmented Correlation Matrix (ACM) across sequential partial-label tasks. The results of two benchmarks show that the method is effective for LML classification and reducing forgetting.
AGCN: Augmented Graph Convolutional Network for Lifelong Multi-label Image Recognition
Mar 11, 2022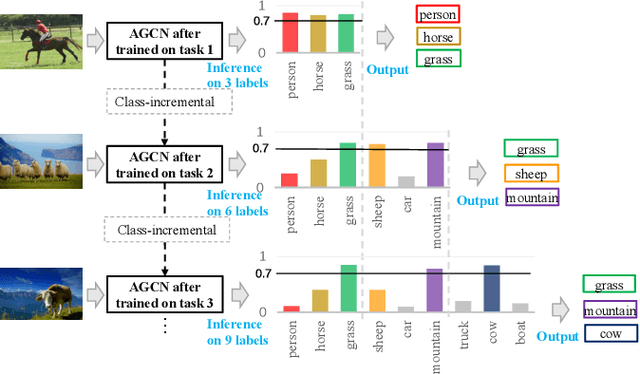
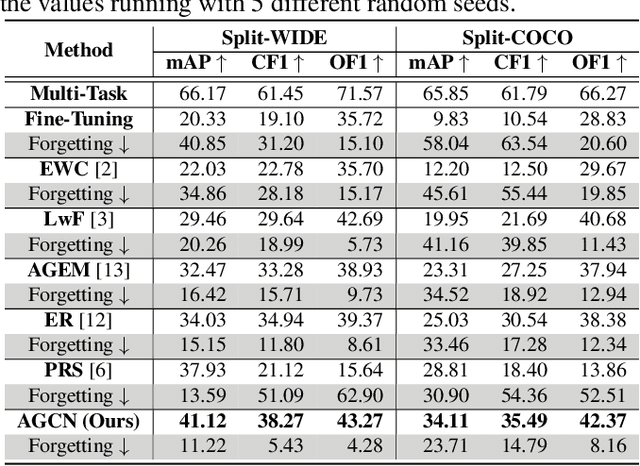
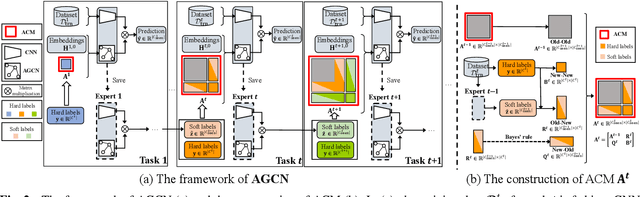
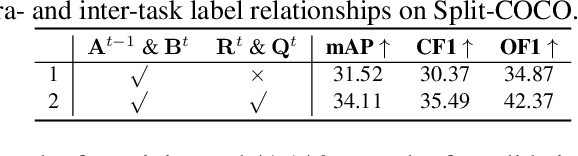
The Lifelong Multi-Label (LML) image recognition builds an online class-incremental classifier in a sequential multi-label image recognition data stream. The key challenges of LML image recognition are the construction of label relationships on Partial Labels of training data and the Catastrophic Forgetting on old classes, resulting in poor generalization. To solve the problems, the study proposes an Augmented Graph Convolutional Network (AGCN) model that can construct the label relationships across the sequential recognition tasks and sustain the catastrophic forgetting. First, we build an Augmented Correlation Matrix (ACM) across all seen classes, where the intra-task relationships derive from the hard label statistics while the inter-task relationships leverage both hard and soft labels from data and a constructed expert network. Then, based on the ACM, the proposed AGCN captures label dependencies with dynamic augmented structure and yields effective class representations. Last, to suppress the forgetting of label dependencies across old tasks, we propose a relationship-preserving loss as a constraint to the construction of label relationships. The proposed method is evaluated using two multi-label image benchmarks and the experimental results show that the proposed method is effective for LML image recognition and can build convincing correlation across tasks even if the labels of previous tasks are missing. Our code is available at https://github.com/Kaile-Du/AGCN.