 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Multimodal Few-Shot 3D Point Cloud Segmentation: From Fused Refinement to Decoupled Arbitration
Jan 04, 2026In this paper, we revisit multimodal few-shot 3D point cloud semantic segmentation (FS-PCS), identifying a conflict in "Fuse-then-Refine" paradigms: the "Plasticity-Stability Dilemma." In addition, CLIP's inter-class confusion can result in semantic blindness. To address these issues, we present the Decoupled-experts Arbitration Few-Shot SegNet (DA-FSS), a model that effectively distinguishes between semantic and geometric paths and mutually regularizes their gradients to achieve better generalization. DA-FSS employs the same backbone and pre-trained text encoder as MM-FSS to generate text embeddings, which can increase free modalities' utilization rate and better leverage each modality's information space. To achieve this, we propose a Parallel Expert Refinement module to generate each modal correlation. We also propose a Stacked Arbitration Module (SAM) to perform convolutional fusion and arbitrate correlations for each modality pathway. The Parallel Experts decouple two paths: a Geometric Expert maintains plasticity, and a Semantic Expert ensures stability. They are coordinated via a Decoupled Alignment Module (DAM) that transfers knowledge without propagating confusion. Experiments on popular datasets (S3DIS, ScanNet) demonstrate the superiority of DA-FSS over MM-FSS. Meanwhile, geometric boundaries, completeness, and texture differentiation are all superior to the baseline. The code is available at: https://github.com/MoWenQAQ/DA-FSS.
Constructing Sample-to-Class Graph for Few-Shot Class-Incremental Learning
Oct 31, 2023Few-shot class-incremental learning (FSCIL) aims to build machine learning model that can continually learn new concepts from a few data samples, without forgetting knowledge of old classes. The challenges of FSCIL lies in the limited data of new classes, which not only lead to significant overfitting issues but also exacerbates the notorious catastrophic forgetting problems. As proved in early studies, building sample relationships is beneficial for learning from few-shot samples. In this paper, we promote the idea to the incremental scenario, and propose a Sample-to-Class (S2C) graph learning method for FSCIL. Specifically, we propose a Sample-level Graph Network (SGN) that focuses on analyzing sample relationships within a single session. This network helps aggregate similar samples, ultimately leading to the extraction of more refined class-level features. Then, we present a Class-level Graph Network (CGN) that establishes connections across class-level features of both new and old classes. This network plays a crucial role in linking the knowledge between different sessions and helps improve overall learning in the FSCIL scenario. Moreover, we design a multi-stage strategy for training S2C model, which mitigates the training challenges posed by limited data in the incremental process. The multi-stage training strategy is designed to build S2C graph from base to few-shot stages, and improve the capacity via an extra pseudo-incremental stage. Experiments on three popular benchmark datasets show that our method clearly outperforms the baselines and sets new state-of-the-art results in FSCIL.
Dynamic V2X Autonomous Perception from Road-to-Vehicle Vision
Oct 29, 2023Vehicle-to-everything (V2X) perception is an innovative technology that enhances vehicle perception accuracy, thereby elevating the security and reliability of autonomous systems. However, existing V2X perception methods focus on static scenes from mainly vehicle-based vision, which is constrained by sensor capabilities and communication loads. To adapt V2X perception models to dynamic scenes, we propose to build V2X perception from road-to-vehicle vision and present Adaptive Road-to-Vehicle Perception (AR2VP) method. In AR2VP,we leverage roadside units to offer stable, wide-range sensing capabilities and serve as communication hubs. AR2VP is devised to tackle both intra-scene and inter-scene changes. For the former, we construct a dynamic perception representing module, which efficiently integrates vehicle perceptions, enabling vehicles to capture a more comprehensive range of dynamic factors within the scene.Moreover, we introduce a road-to-vehicle perception compensating module, aimed at preserving the maximized roadside unit perception information in the presence of intra-scene changes.For inter-scene changes, we implement an experience replay mechanism leveraging the roadside unit's storage capacity to retain a subset of historical scene data, maintaining model robustness in response to inter-scene shifts. We conduct perception experiment on 3D object detection and segmentation, and the results show that AR2VP excels in both performance-bandwidth trade-offs and adaptability within dynamic environments.
Two-level Graph Network for Few-Shot Class-Incremental Learning
Mar 24, 2023Few-shot class-incremental learning (FSCIL) aims to design machine learning algorithms that can continually learn new concepts from a few data points, without forgetting knowledge of old classes. The difficulty lies in that limited data from new classes not only lead to significant overfitting issues but also exacerbates the notorious catastrophic forgetting problems. However, existing FSCIL methods ignore the semantic relationships between sample-level and class-level. % Using the advantage that graph neural network (GNN) can mine rich information among few samples, In this paper, we designed a two-level graph network for FSCIL named Sample-level and Class-level Graph Neural Network (SCGN). Specifically, a pseudo incremental learning paradigm is designed in SCGN, which synthesizes virtual few-shot tasks as new tasks to optimize SCGN model parameters in advance. Sample-level graph network uses the relationship of a few samples to aggregate similar samples and obtains refined class-level features. Class-level graph network aims to mitigate the semantic conflict between prototype features of new classes and old classes. SCGN builds two-level graph networks to guarantee the latent semantic of each few-shot class can be effectively represented in FSCIL. Experiments on three popular benchmark datasets show that our method significantly outperforms the baselines and sets new state-of-the-art results with remarkable advantages.
Multi-Label Continual Learning using Augmented Graph Convolutional Network
Nov 27, 2022



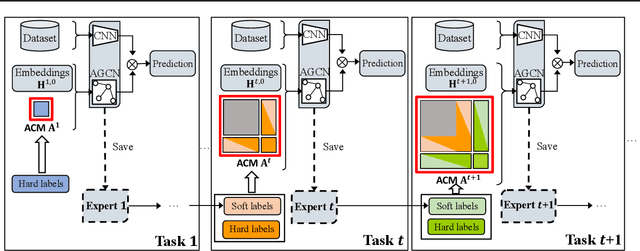
Multi-Label Continual Learning (MLCL) builds a class-incremental framework in a sequential multi-label image recognition data stream. The critical challenges of MLCL are the construction of label relationships on past-missing and future-missing partial labels of training data and the catastrophic forgetting on old classes, resulting in poor generalization. To solve the problems, the study proposes an Augmented Graph Convolutional Network (AGCN++) that can construct the cross-task label relationships in MLCL and sustain catastrophic forgetting. First, we build an Augmented Correlation Matrix (ACM) across all seen classes, where the intra-task relationships derive from the hard label statistics. In contrast, the inter-task relationships leverage hard and soft labels from data and a constructed expert network. Then, we propose a novel partial label encoder (PLE) for MLCL, which can extract dynamic class representation for each partial label image as graph nodes and help generate soft labels to create a more convincing ACM and suppress forgetting. Last, to suppress the forgetting of label dependencies across old tasks, we propose a relationship-preserving constrainter to construct label relationships. The inter-class topology can be augmented automatically, which also yields effective class representations. The proposed method is evaluated using two multi-label image benchmarks. The experimental results show that the proposed way is effective for MLCL image recognition and can build convincing correlations across tasks even if the labels of previous tasks are missing.
Class-Incremental Lifelong Learning in Multi-Label Classification
Jul 16, 2022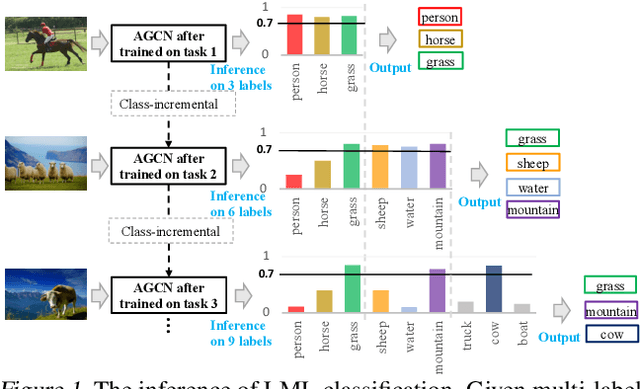
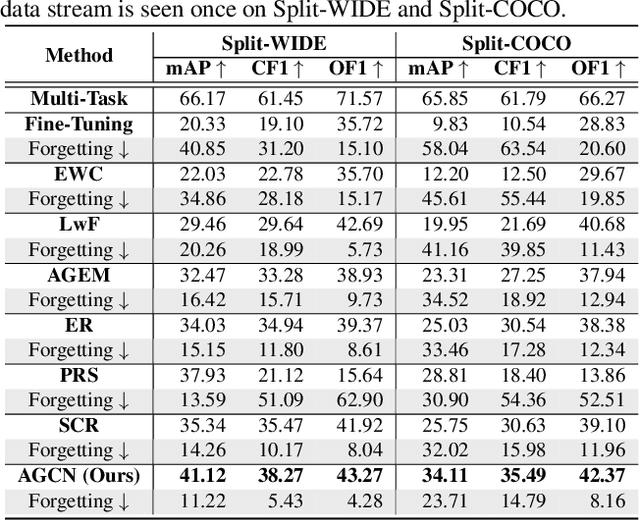
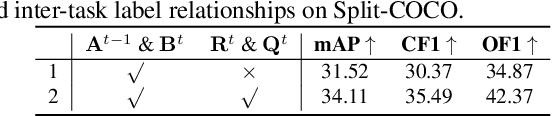
Existing class-incremental lifelong learning studies only the data is with single-label, which limits its adaptation to multi-label data. This paper studies Lifelong Multi-Label (LML) classification, which builds an online class-incremental classifier in a sequential multi-label classification data stream. Training on the data with Partial Labels in LML classification may result in more serious Catastrophic Forgetting in old classes. To solve the problem, the study proposes an Augmented Graph Convolutional Network (AGCN) with a built Augmented Correlation Matrix (ACM) across sequential partial-label tasks. The results of two benchmarks show that the method is effective for LML classification and reducing forgetting.
AGCN: Augmented Graph Convolutional Network for Lifelong Multi-label Image Recognition
Mar 11, 2022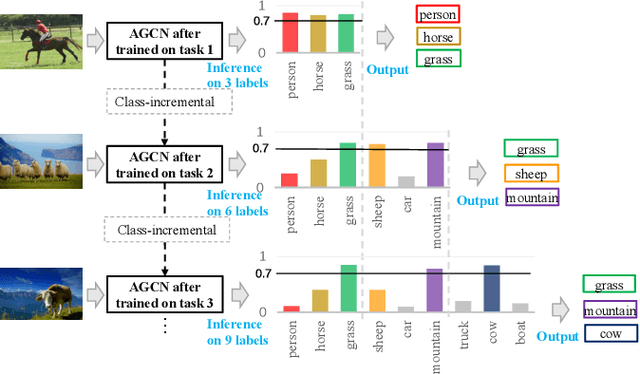
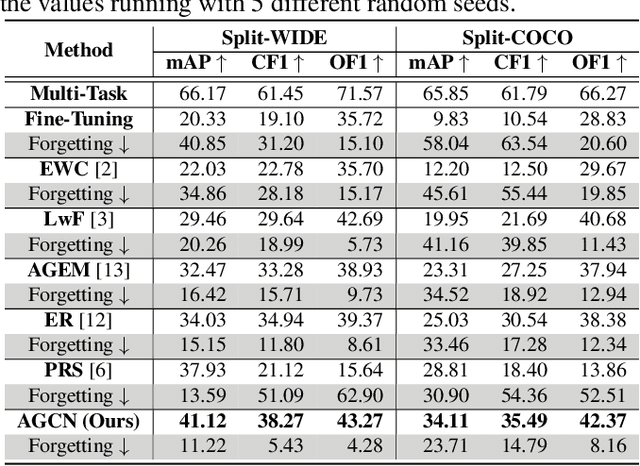
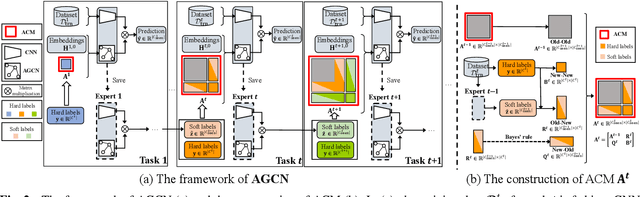
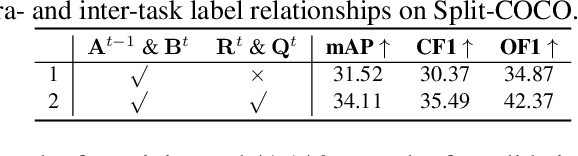
The Lifelong Multi-Label (LML) image recognition builds an online class-incremental classifier in a sequential multi-label image recognition data stream. The key challenges of LML image recognition are the construction of label relationships on Partial Labels of training data and the Catastrophic Forgetting on old classes, resulting in poor generalization. To solve the problems, the study proposes an Augmented Graph Convolutional Network (AGCN) model that can construct the label relationships across the sequential recognition tasks and sustain the catastrophic forgetting. First, we build an Augmented Correlation Matrix (ACM) across all seen classes, where the intra-task relationships derive from the hard label statistics while the inter-task relationships leverage both hard and soft labels from data and a constructed expert network. Then, based on the ACM, the proposed AGCN captures label dependencies with dynamic augmented structure and yields effective class representations. Last, to suppress the forgetting of label dependencies across old tasks, we propose a relationship-preserving loss as a constraint to the construction of label relationships. The proposed method is evaluated using two multi-label image benchmarks and the experimental results show that the proposed method is effective for LML image recognition and can build convincing correlation across tasks even if the labels of previous tasks are missing. Our code is available at https://github.com/Kaile-Du/AGCN.
Each Attribute Matters: Contrastive Attention for Sentence-based Image Editing
Oct 21, 2021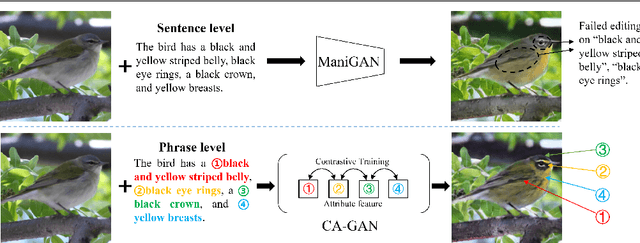

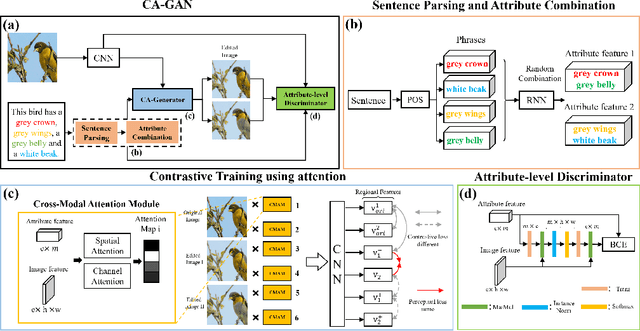
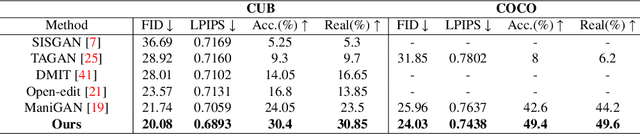
Sentence-based Image Editing (SIE) aims to deploy natural language to edit an image. Offering potentials to reduce expensive manual editing, SIE has attracted much interest recently. However, existing methods can hardly produce accurate editing and even lead to failures in attribute editing when the query sentence is with multiple editable attributes. To cope with this problem, by focusing on enhancing the difference between attributes, this paper proposes a novel model called Contrastive Attention Generative Adversarial Network (CA-GAN), which is inspired from contrastive training. Specifically, we first design a novel contrastive attention module to enlarge the editing difference between random combinations of attributes which are formed during training. We then construct an attribute discriminator to ensure effective editing on each attribute. A series of experiments show that our method can generate very encouraging results in sentence-based image editing with multiple attributes on CUB and COCO dataset. Our code is available at https://github.com/Zlq2021/CA-GAN