 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Agent System for Information Extraction from the Chemical Literature
Jul 27, 2025To fully expedite AI-powered chemical research, high-quality chemical databases are the cornerstone. Automatic extraction of chemical information from the literature is essential for constructing reaction databases, but it is currently limited by the multimodality and style variability of chemical information. In this work, we developed a multimodal large language model (MLLM)-based multi-agent system for automatic chemical information extraction. We used the MLLM's strong reasoning capability to understand the structure of complex chemical graphics, decompose the extraction task into sub-tasks and coordinate a set of specialized agents to solve them. Our system achieved an F1 score of 80.8% on a benchmark dataset of complex chemical reaction graphics from the literature, surpassing the previous state-of-the-art model (F1 score: 35.6%) by a significant margin. Additionally, it demonstrated consistent improvements in key sub-tasks, including molecular image recognition, reaction image parsing, named entity recognition and text-based reaction extraction. This work is a critical step toward automated chemical information extraction into structured datasets, which will be a strong promoter of AI-driven chemical research.
Towards Large-scale Chemical Reaction Image Parsing via a Multimodal Large Language Model
Mar 11, 2025Artificial intelligence (AI) has demonstrated significant promise in advancing organic chemistry research; however, its effectiveness depends on the availability of high-quality chemical reaction data. Currently, most published chemical reactions are not available in machine-readable form, limiting the broader application of AI in this field. The extraction of published chemical reactions into structured databases still relies heavily on manual curation, and robust automatic parsing of chemical reaction images into machine-readable data remains a significant challenge. To address this, we introduce the Reaction Image Multimodal large language model (RxnIM), the first multimodal large language model specifically designed to parse chemical reaction images into machine-readable reaction data. RxnIM not only extracts key chemical components from reaction images but also interprets the textual content that describes reaction conditions. Together with specially designed large-scale dataset generation method to support model training, our approach achieves excellent performance, with an average F1 score of 88% on various benchmarks, surpassing literature methods by 5%. This represents a crucial step toward the automatic construction of large databases of machine-readable reaction data parsed from images in the chemistry literature, providing essential data resources for AI research in chemistry. The source code, model checkpoints, and datasets developed in this work are released under permissive licenses. An instance of the RxnIM web application can be accessed at https://huggingface.co/spaces/CYF200127/RxnIM.
Experimental evaluation of offline reinforcement learning for HVAC control in buildings
Aug 15, 2024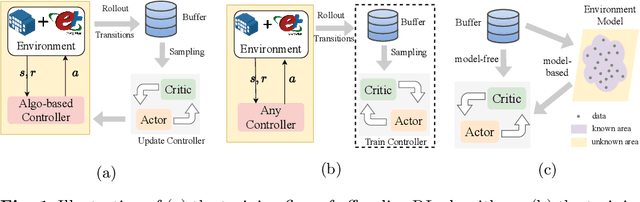
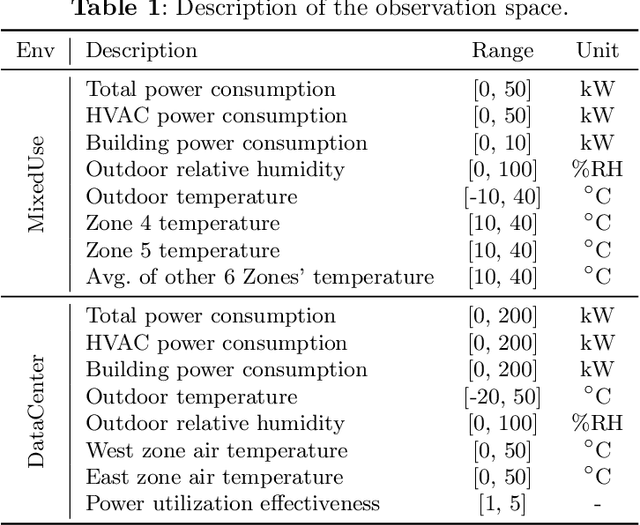
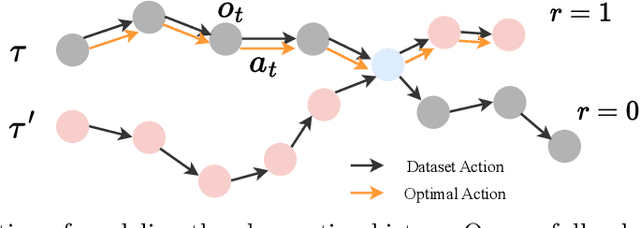
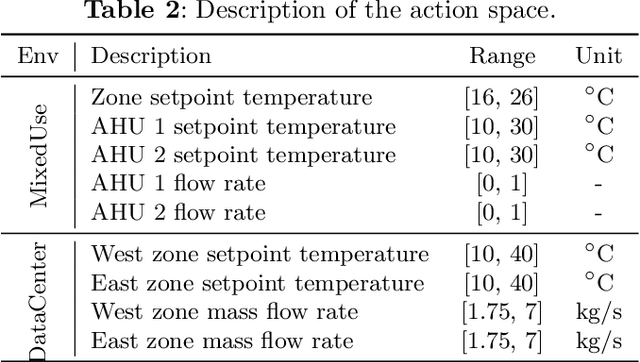
Reinforcement learning (RL) techniques have been increasingly investigated for dynamic HVAC control in buildings. However, most studies focus on exploring solutions in online or off-policy scenarios without discussing in detail the implementation feasibility or effectiveness of dealing with purely offline datasets or trajectories. The lack of these works limits the real-world deployment of RL-based HVAC controllers, especially considering the abundance of historical data. To this end, this paper comprehensively evaluates the strengths and limitations of state-of-the-art offline RL algorithms by conducting analytical and numerical studies. The analysis is conducted from two perspectives: algorithms and dataset characteristics. As a prerequisite, the necessity of applying offline RL algorithms is first confirmed in two building environments. The ability of observation history modeling to reduce violations and enhance performance is subsequently studied. Next, the performance of RL-based controllers under datasets with different qualitative and quantitative conditions is investigated, including constraint satisfaction and power consumption. Finally, the sensitivity of certain hyperparameters is also evaluated. The results indicate that datasets of a certain suboptimality level and relatively small scale can be utilized to effectively train a well-performed RL-based HVAC controller. Specifically, such controllers can reduce at most 28.5% violation ratios of indoor temperatures and achieve at most 12.1% power savings compared to the baseline controller. In summary, this paper presents our well-structured investigations and new findings when applying offline reinforcement learning to building HVAC systems.
Constructing Sample-to-Class Graph for Few-Shot Class-Incremental Learning
Oct 31, 2023Few-shot class-incremental learning (FSCIL) aims to build machine learning model that can continually learn new concepts from a few data samples, without forgetting knowledge of old classes. The challenges of FSCIL lies in the limited data of new classes, which not only lead to significant overfitting issues but also exacerbates the notorious catastrophic forgetting problems. As proved in early studies, building sample relationships is beneficial for learning from few-shot samples. In this paper, we promote the idea to the incremental scenario, and propose a Sample-to-Class (S2C) graph learning method for FSCIL. Specifically, we propose a Sample-level Graph Network (SGN) that focuses on analyzing sample relationships within a single session. This network helps aggregate similar samples, ultimately leading to the extraction of more refined class-level features. Then, we present a Class-level Graph Network (CGN) that establishes connections across class-level features of both new and old classes. This network plays a crucial role in linking the knowledge between different sessions and helps improve overall learning in the FSCIL scenario. Moreover, we design a multi-stage strategy for training S2C model, which mitigates the training challenges posed by limited data in the incremental process. The multi-stage training strategy is designed to build S2C graph from base to few-shot stages, and improve the capacity via an extra pseudo-incremental stage. Experiments on three popular benchmark datasets show that our method clearly outperforms the baselines and sets new state-of-the-art results in FSCIL.
Dynamic V2X Autonomous Perception from Road-to-Vehicle Vision
Oct 29, 2023Vehicle-to-everything (V2X) perception is an innovative technology that enhances vehicle perception accuracy, thereby elevating the security and reliability of autonomous systems. However, existing V2X perception methods focus on static scenes from mainly vehicle-based vision, which is constrained by sensor capabilities and communication loads. To adapt V2X perception models to dynamic scenes, we propose to build V2X perception from road-to-vehicle vision and present Adaptive Road-to-Vehicle Perception (AR2VP) method. In AR2VP,we leverage roadside units to offer stable, wide-range sensing capabilities and serve as communication hubs. AR2VP is devised to tackle both intra-scene and inter-scene changes. For the former, we construct a dynamic perception representing module, which efficiently integrates vehicle perceptions, enabling vehicles to capture a more comprehensive range of dynamic factors within the scene.Moreover, we introduce a road-to-vehicle perception compensating module, aimed at preserving the maximized roadside unit perception information in the presence of intra-scene changes.For inter-scene changes, we implement an experience replay mechanism leveraging the roadside unit's storage capacity to retain a subset of historical scene data, maintaining model robustness in response to inter-scene shifts. We conduct perception experiment on 3D object detection and segmentation, and the results show that AR2VP excels in both performance-bandwidth trade-offs and adaptability within dynamic environments.
Two-level Graph Network for Few-Shot Class-Incremental Learning
Mar 24, 2023Few-shot class-incremental learning (FSCIL) aims to design machine learning algorithms that can continually learn new concepts from a few data points, without forgetting knowledge of old classes. The difficulty lies in that limited data from new classes not only lead to significant overfitting issues but also exacerbates the notorious catastrophic forgetting problems. However, existing FSCIL methods ignore the semantic relationships between sample-level and class-level. % Using the advantage that graph neural network (GNN) can mine rich information among few samples, In this paper, we designed a two-level graph network for FSCIL named Sample-level and Class-level Graph Neural Network (SCGN). Specifically, a pseudo incremental learning paradigm is designed in SCGN, which synthesizes virtual few-shot tasks as new tasks to optimize SCGN model parameters in advance. Sample-level graph network uses the relationship of a few samples to aggregate similar samples and obtains refined class-level features. Class-level graph network aims to mitigate the semantic conflict between prototype features of new classes and old classes. SCGN builds two-level graph networks to guarantee the latent semantic of each few-shot class can be effectively represented in FSCIL. Experiments on three popular benchmark datasets show that our method significantly outperforms the baselines and sets new state-of-the-art results with remarkable advantages.
Centroid Distance Distillation for Effective Rehearsal in Continual Learning
Mar 06, 2023Rehearsal, retraining on a stored small data subset of old tasks, has been proven effective in solving catastrophic forgetting in continual learning. However, due to the sampled data may have a large bias towards the original dataset, retraining them is susceptible to driving continual domain drift of old tasks in feature space, resulting in forgetting. In this paper, we focus on tackling the continual domain drift problem with centroid distance distillation. First, we propose a centroid caching mechanism for sampling data points based on constructed centroids to reduce the sample bias in rehearsal. Then, we present a centroid distance distillation that only stores the centroid distance to reduce the continual domain drift. The experiments on four continual learning datasets show the superiority of the proposed method, and the continual domain drift can be reduced.
Multi-Label Continual Learning using Augmented Graph Convolutional Network
Nov 27, 2022



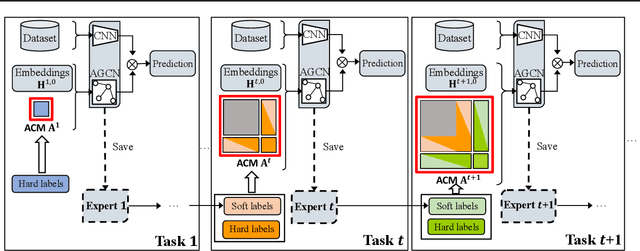
Multi-Label Continual Learning (MLCL) builds a class-incremental framework in a sequential multi-label image recognition data stream. The critical challenges of MLCL are the construction of label relationships on past-missing and future-missing partial labels of training data and the catastrophic forgetting on old classes, resulting in poor generalization. To solve the problems, the study proposes an Augmented Graph Convolutional Network (AGCN++) that can construct the cross-task label relationships in MLCL and sustain catastrophic forgetting. First, we build an Augmented Correlation Matrix (ACM) across all seen classes, where the intra-task relationships derive from the hard label statistics. In contrast, the inter-task relationships leverage hard and soft labels from data and a constructed expert network. Then, we propose a novel partial label encoder (PLE) for MLCL, which can extract dynamic class representation for each partial label image as graph nodes and help generate soft labels to create a more convincing ACM and suppress forgetting. Last, to suppress the forgetting of label dependencies across old tasks, we propose a relationship-preserving constrainter to construct label relationships. The inter-class topology can be augmented automatically, which also yields effective class representations. The proposed method is evaluated using two multi-label image benchmarks. The experimental results show that the proposed way is effective for MLCL image recognition and can build convincing correlations across tasks even if the labels of previous tasks are missing.
Class-Incremental Lifelong Learning in Multi-Label Classification
Jul 16, 2022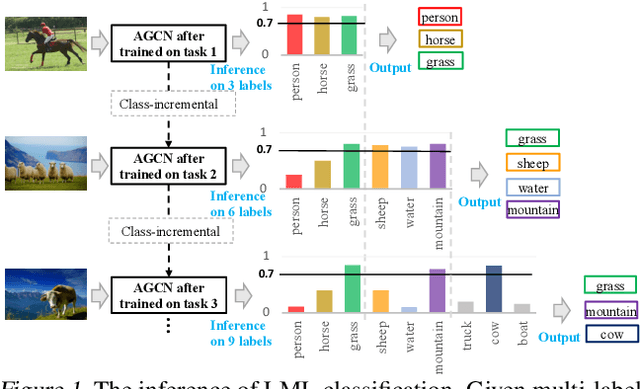
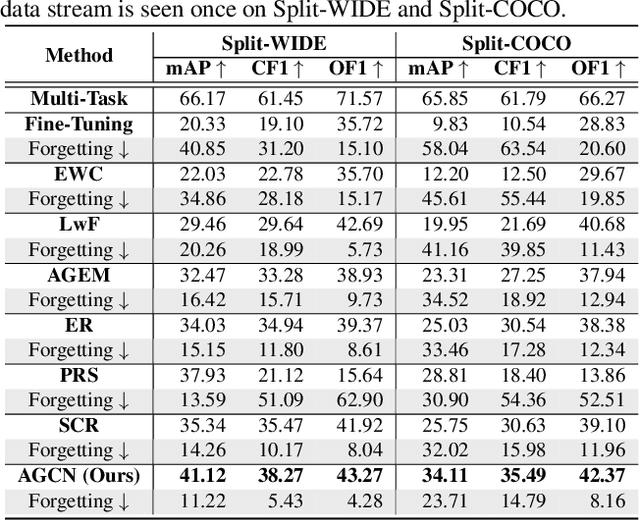
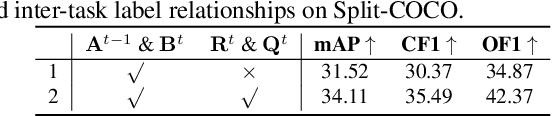
Existing class-incremental lifelong learning studies only the data is with single-label, which limits its adaptation to multi-label data. This paper studies Lifelong Multi-Label (LML) classification, which builds an online class-incremental classifier in a sequential multi-label classification data stream. Training on the data with Partial Labels in LML classification may result in more serious Catastrophic Forgetting in old classes. To solve the problem, the study proposes an Augmented Graph Convolutional Network (AGCN) with a built Augmented Correlation Matrix (ACM) across sequential partial-label tasks. The results of two benchmarks show that the method is effective for LML classification and reducing forgetting.
AGCN: Augmented Graph Convolutional Network for Lifelong Multi-label Image Recognition
Mar 11, 2022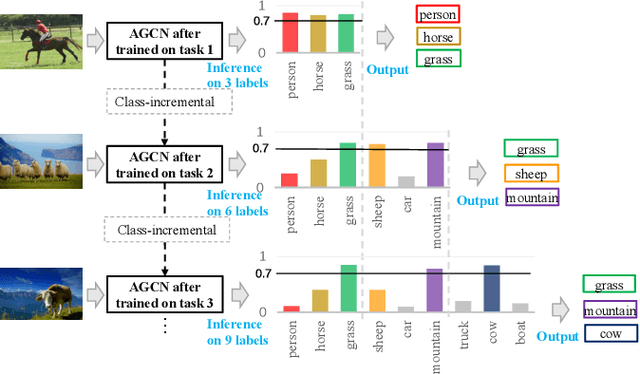
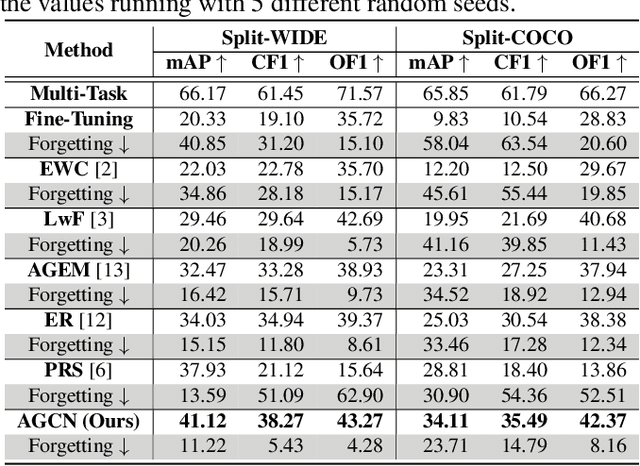
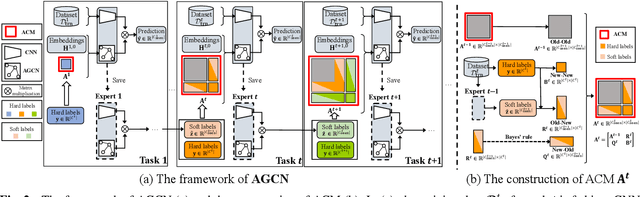
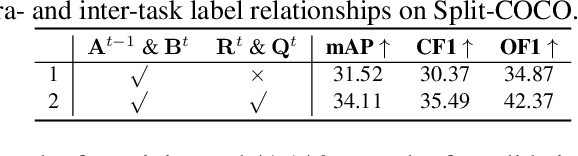
The Lifelong Multi-Label (LML) image recognition builds an online class-incremental classifier in a sequential multi-label image recognition data stream. The key challenges of LML image recognition are the construction of label relationships on Partial Labels of training data and the Catastrophic Forgetting on old classes, resulting in poor generalization. To solve the problems, the study proposes an Augmented Graph Convolutional Network (AGCN) model that can construct the label relationships across the sequential recognition tasks and sustain the catastrophic forgetting. First, we build an Augmented Correlation Matrix (ACM) across all seen classes, where the intra-task relationships derive from the hard label statistics while the inter-task relationships leverage both hard and soft labels from data and a constructed expert network. Then, based on the ACM, the proposed AGCN captures label dependencies with dynamic augmented structure and yields effective class representations. Last, to suppress the forgetting of label dependencies across old tasks, we propose a relationship-preserving loss as a constraint to the construction of label relationships. The proposed method is evaluated using two multi-label image benchmarks and the experimental results show that the proposed method is effective for LML image recognition and can build convincing correlation across tasks even if the labels of previous tasks are missing. Our code is available at https://github.com/Kaile-Du/AGCN.