 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimental evaluation of offline reinforcement learning for HVAC control in buildings
Paper and Code
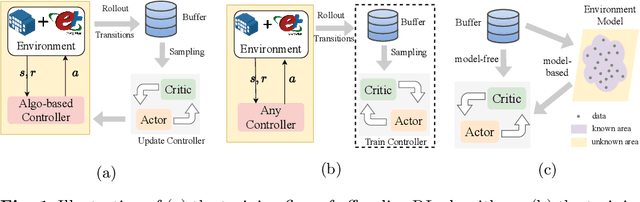
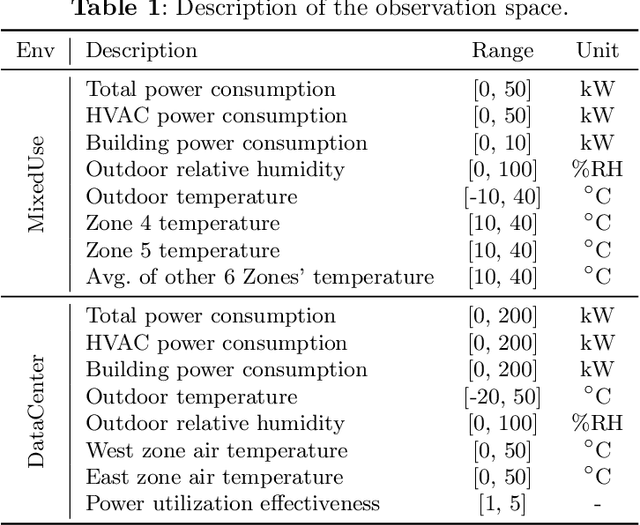
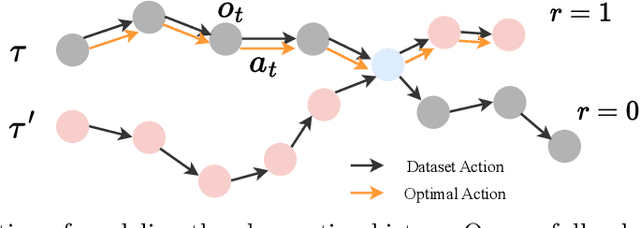
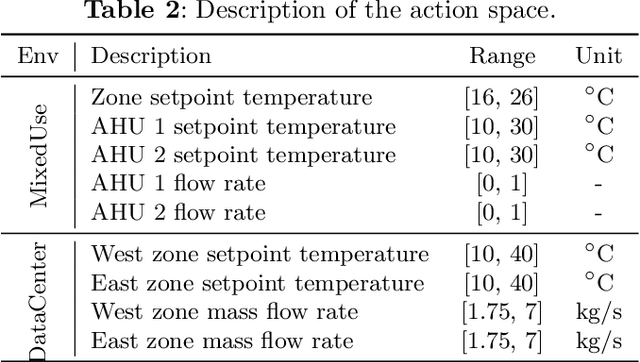
Reinforcement learning (RL) techniques have been increasingly investigated for dynamic HVAC control in buildings. However, most studies focus on exploring solutions in online or off-policy scenarios without discussing in detail the implementation feasibility or effectiveness of dealing with purely offline datasets or trajectories. The lack of these works limits the real-world deployment of RL-based HVAC controllers, especially considering the abundance of historical data. To this end, this paper comprehensively evaluates the strengths and limitations of state-of-the-art offline RL algorithms by conducting analytical and numerical studies. The analysis is conducted from two perspectives: algorithms and dataset characteristics. As a prerequisite, the necessity of applying offline RL algorithms is first confirmed in two building environments. The ability of observation history modeling to reduce violations and enhance performance is subsequently studied. Next, the performance of RL-based controllers under datasets with different qualitative and quantitative conditions is investigated, including constraint satisfaction and power consumption. Finally, the sensitivity of certain hyperparameters is also evaluated. The results indicate that datasets of a certain suboptimality level and relatively small scale can be utilized to effectively train a well-performed RL-based HVAC controller. Specifically, such controllers can reduce at most 28.5% violation ratios of indoor temperatures and achieve at most 12.1% power savings compared to the baseline controller. In summary, this paper presents our well-structured investigations and new findings when applying offline reinforcement learning to building HVAC systems.