 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDTTNet: Improving Video Shadow Detection via Dark-Aware Guidance and Tokenized Temporal Modeling
Nov 10, 2025Video shadow detection confronts two entwined difficulties: distinguishing shadows from complex backgrounds and modeling dynamic shadow deformations under varying illumination. To address shadow-background ambiguity, we leverage linguistic priors through the proposed Vision-language Match Module (VMM) and a Dark-aware Semantic Block (DSB), extracting text-guided features to explicitly differentiate shadows from dark objects. Furthermore, we introduce adaptive mask reweighting to downweight penumbra regions during training and apply edge masks at the final decoder stage for better supervision. For temporal modeling of variable shadow shapes, we propose a Tokenized Temporal Block (TTB) that decouples spatiotemporal learning. TTB summarizes cross-frame shadow semantics into learnable temporal tokens, enabling efficient sequence encoding with minimal computation overhead. Comprehensive Experiments on multiple benchmark datasets demonstrate state-of-the-art accuracy and real-time inference efficiency. Codes are available at https://github.com/city-cheng/DTTNet.
Conformal Uncertainty Indicator for Continual Test-Time Adaptation
Feb 05, 2025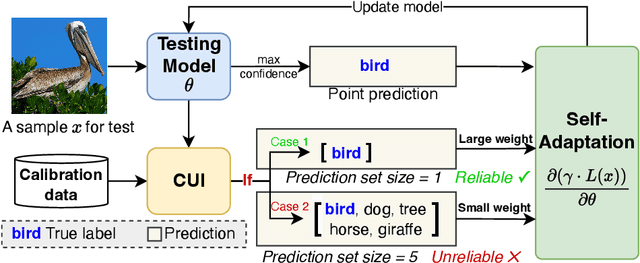
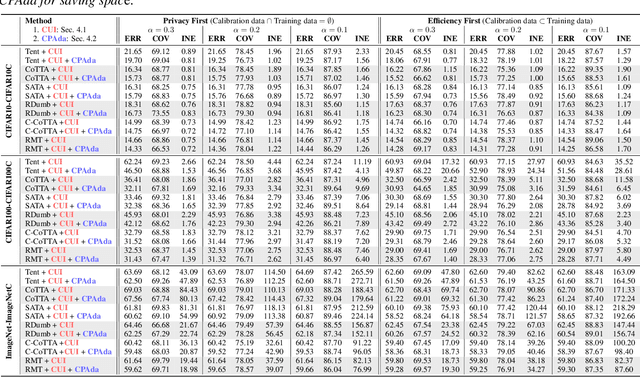
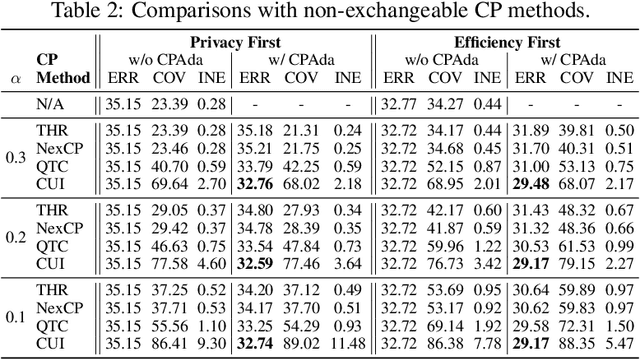
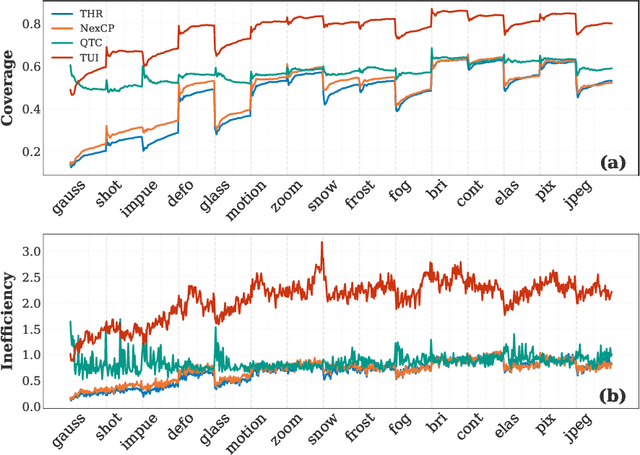
Continual Test-Time Adaptation (CTTA) aims to adapt models to sequentially changing domains during testing, relying on pseudo-labels for self-adaptation. However, incorrect pseudo-labels can accumulate, leading to performance degradation. To address this, we propose a Conformal Uncertainty Indicator (CUI) for CTTA, leveraging Conformal Prediction (CP) to generate prediction sets that include the true label with a specified coverage probability. Since domain shifts can lower the coverage than expected, making CP unreliable, we dynamically compensate for the coverage by measuring both domain and data differences. Reliable pseudo-labels from CP are then selectively utilized to enhance adaptation. Experiments confirm that CUI effectively estimates uncertainty and improves adaptation performance across various existing CTTA methods.
CALA: A Class-Aware Logit Adapter for Few-Shot Class-Incremental Learning
Dec 17, 2024



Few-Shot Class-Incremental Learning (FSCIL) defines a practical but challenging task where models are required to continuously learn novel concepts with only a few training samples. Due to data scarcity, existing FSCIL methods resort to training a backbone with abundant base data and then keeping it frozen afterward. However, the above operation often causes the backbone to overfit to base classes while overlooking the novel ones, leading to severe confusion between them. To address this issue, we propose Class-Aware Logit Adapter (CALA). Our method involves a lightweight adapter that learns to rectify biased predictions through a pseudo-incremental learning paradigm. In the real FSCIL process, we use the learned adapter to dynamically generate robust balancing factors. These factors can adjust confused novel instances back to their true label space based on their similarity to base classes. Specifically, when confusion is more likely to occur in novel instances that closely resemble base classes, greater rectification is required. Notably, CALA operates on the classifier level, preserving the original feature space, thus it can be flexibly plugged into most of the existing FSCIL works for improved performance. Experiments on three benchmark datasets consistently validate the effectiveness and flexibility of CALA. Codes will be available upon acceptance.
Rebalancing Multi-Label Class-Incremental Learning
Aug 22, 2024Multi-label class-incremental learning (MLCIL) is essential for real-world multi-label applications, allowing models to learn new labels while retaining previously learned knowledge continuously. However, recent MLCIL approaches can only achieve suboptimal performance due to the oversight of the positive-negative imbalance problem, which manifests at both the label and loss levels because of the task-level partial label issue. The imbalance at the label level arises from the substantial absence of negative labels, while the imbalance at the loss level stems from the asymmetric contributions of the positive and negative loss parts to the optimization. To address the issue above, we propose a Rebalance framework for both the Loss and Label levels (RebLL), which integrates two key modules: asymmetric knowledge distillation (AKD) and online relabeling (OR). AKD is proposed to rebalance at the loss level by emphasizing the negative label learning in classification loss and down-weighting the contribution of overconfident predictions in distillation loss. OR is designed for label rebalance, which restores the original class distribution in memory by online relabeling the missing classes. Our comprehensive experiments on the PASCAL VOC and MS-COCO datasets demonstrate that this rebalancing strategy significantly improves performance, achieving new state-of-the-art results even with a vanilla CNN backbone.
Less is More: Pseudo-Label Filtering for Continual Test-Time Adaptation
Jun 03, 2024Continual Test-Time Adaptation (CTTA) aims to adapt a pre-trained model to a sequence of target domains during the test phase without accessing the source data. To adapt to unlabeled data from unknown domains, existing methods rely on constructing pseudo-labels for all samples and updating the model through self-training. However, these pseudo-labels often involve noise, leading to insufficient adaptation. To improve the quality of pseudo-labels, we propose a pseudo-label selection method for CTTA, called Pseudo Labeling Filter (PLF). The key idea of PLF is to keep selecting appropriate thresholds for pseudo-labels and identify reliable ones for self-training. Specifically, we present three principles for setting thresholds during continuous domain learning, including initialization, growth and diversity. Based on these principles, we design Self-Adaptive Thresholding to filter pseudo-labels. Additionally, we introduce a Class Prior Alignment (CPA) method to encourage the model to make diverse predictions for unknown domain samples. Through extensive experiments, PLF outperforms current state-of-the-art methods, proving its effectiveness in CTTA.
Controllable Continual Test-Time Adaptation
May 23, 2024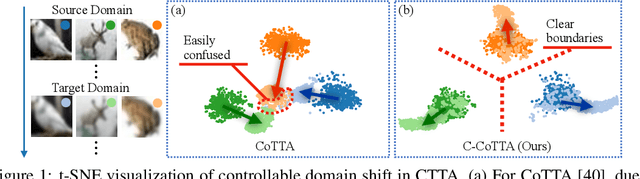
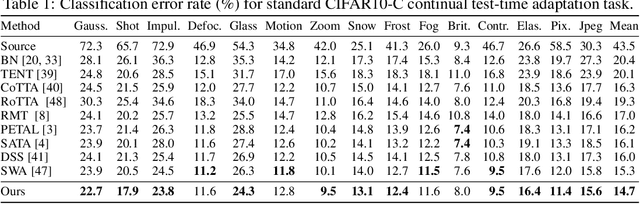

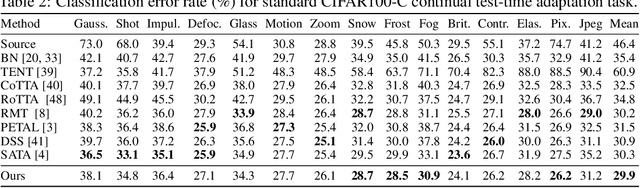
Continual Test-Time Adaptation (CTTA) is an emerging and challenging task where a model trained in a source domain must adapt to continuously changing conditions during testing, without access to the original source data. CTTA is prone to error accumulation due to uncontrollable domain shifts, leading to blurred decision boundaries between categories. Existing CTTA methods primarily focus on suppressing domain shifts, which proves inadequate during the unsupervised test phase. In contrast, we introduce a novel approach that guides rather than suppresses these shifts. Specifically, we propose $\textbf{C}$ontrollable $\textbf{Co}$ntinual $\textbf{T}$est-$\textbf{T}$ime $\textbf{A}$daptation (C-CoTTA), which explicitly prevents any single category from encroaching on others, thereby mitigating the mutual influence between categories caused by uncontrollable shifts. Moreover, our method reduces the sensitivity of model to domain transformations, thereby minimizing the magnitude of category shifts. Extensive quantitative experiments demonstrate the effectiveness of our method, while qualitative analyses, such as t-SNE plots, confirm the theoretical validity of our approach.
Overcoming Domain Drift in Online Continual Learning
May 15, 2024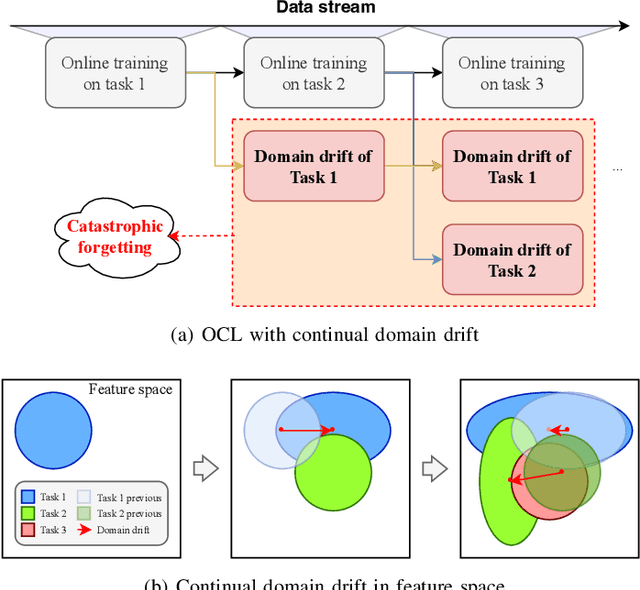
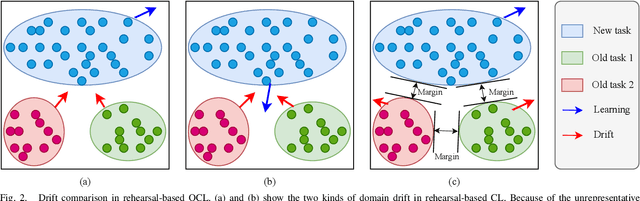
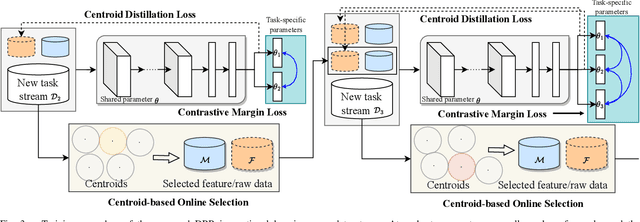
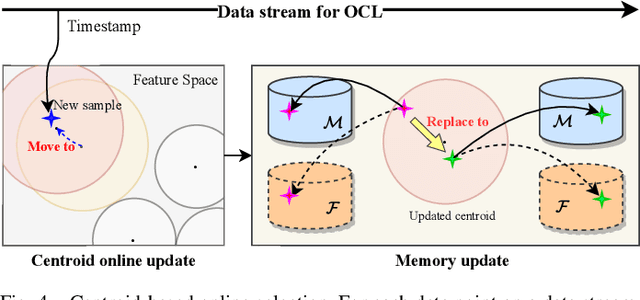
Online Continual Learning (OCL) empowers machine learning models to acquire new knowledge online across a sequence of tasks. However, OCL faces a significant challenge: catastrophic forgetting, wherein the model learned in previous tasks is substantially overwritten upon encountering new tasks, leading to a biased forgetting of prior knowledge. Moreover, the continual doman drift in sequential learning tasks may entail the gradual displacement of the decision boundaries in the learned feature space, rendering the learned knowledge susceptible to forgetting. To address the above problem, in this paper, we propose a novel rehearsal strategy, termed Drift-Reducing Rehearsal (DRR), to anchor the domain of old tasks and reduce the negative transfer effects. First, we propose to select memory for more representative samples guided by constructed centroids in a data stream. Then, to keep the model from domain chaos in drifting, a two-level angular cross-task Contrastive Margin Loss (CML) is proposed, to encourage the intra-class and intra-task compactness, and increase the inter-class and inter-task discrepancy. Finally, to further suppress the continual domain drift, we present an optional Centorid Distillation Loss (CDL) on the rehearsal memory to anchor the knowledge in feature space for each previous old task. Extensive experimental results on four benchmark datasets validate that the proposed DRR can effectively mitigate the continual domain drift and achieve the state-of-the-art (SOTA) performance in OCL.
Constructing Sample-to-Class Graph for Few-Shot Class-Incremental Learning
Oct 31, 2023Few-shot class-incremental learning (FSCIL) aims to build machine learning model that can continually learn new concepts from a few data samples, without forgetting knowledge of old classes. The challenges of FSCIL lies in the limited data of new classes, which not only lead to significant overfitting issues but also exacerbates the notorious catastrophic forgetting problems. As proved in early studies, building sample relationships is beneficial for learning from few-shot samples. In this paper, we promote the idea to the incremental scenario, and propose a Sample-to-Class (S2C) graph learning method for FSCIL. Specifically, we propose a Sample-level Graph Network (SGN) that focuses on analyzing sample relationships within a single session. This network helps aggregate similar samples, ultimately leading to the extraction of more refined class-level features. Then, we present a Class-level Graph Network (CGN) that establishes connections across class-level features of both new and old classes. This network plays a crucial role in linking the knowledge between different sessions and helps improve overall learning in the FSCIL scenario. Moreover, we design a multi-stage strategy for training S2C model, which mitigates the training challenges posed by limited data in the incremental process. The multi-stage training strategy is designed to build S2C graph from base to few-shot stages, and improve the capacity via an extra pseudo-incremental stage. Experiments on three popular benchmark datasets show that our method clearly outperforms the baselines and sets new state-of-the-art results in FSCIL.
Dynamic V2X Autonomous Perception from Road-to-Vehicle Vision
Oct 29, 2023Vehicle-to-everything (V2X) perception is an innovative technology that enhances vehicle perception accuracy, thereby elevating the security and reliability of autonomous systems. However, existing V2X perception methods focus on static scenes from mainly vehicle-based vision, which is constrained by sensor capabilities and communication loads. To adapt V2X perception models to dynamic scenes, we propose to build V2X perception from road-to-vehicle vision and present Adaptive Road-to-Vehicle Perception (AR2VP) method. In AR2VP,we leverage roadside units to offer stable, wide-range sensing capabilities and serve as communication hubs. AR2VP is devised to tackle both intra-scene and inter-scene changes. For the former, we construct a dynamic perception representing module, which efficiently integrates vehicle perceptions, enabling vehicles to capture a more comprehensive range of dynamic factors within the scene.Moreover, we introduce a road-to-vehicle perception compensating module, aimed at preserving the maximized roadside unit perception information in the presence of intra-scene changes.For inter-scene changes, we implement an experience replay mechanism leveraging the roadside unit's storage capacity to retain a subset of historical scene data, maintaining model robustness in response to inter-scene shifts. We conduct perception experiment on 3D object detection and segmentation, and the results show that AR2VP excels in both performance-bandwidth trade-offs and adaptability within dynamic environments.
Two-level Graph Network for Few-Shot Class-Incremental Learning
Mar 24, 2023Few-shot class-incremental learning (FSCIL) aims to design machine learning algorithms that can continually learn new concepts from a few data points, without forgetting knowledge of old classes. The difficulty lies in that limited data from new classes not only lead to significant overfitting issues but also exacerbates the notorious catastrophic forgetting problems. However, existing FSCIL methods ignore the semantic relationships between sample-level and class-level. % Using the advantage that graph neural network (GNN) can mine rich information among few samples, In this paper, we designed a two-level graph network for FSCIL named Sample-level and Class-level Graph Neural Network (SCGN). Specifically, a pseudo incremental learning paradigm is designed in SCGN, which synthesizes virtual few-shot tasks as new tasks to optimize SCGN model parameters in advance. Sample-level graph network uses the relationship of a few samples to aggregate similar samples and obtains refined class-level features. Class-level graph network aims to mitigate the semantic conflict between prototype features of new classes and old classes. SCGN builds two-level graph networks to guarantee the latent semantic of each few-shot class can be effectively represented in FSCIL. Experiments on three popular benchmark datasets show that our method significantly outperforms the baselines and sets new state-of-the-art results with remarkable advantages.