 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Guided Hyperspectral Object Tracking via Semantics Fusion and Contextual Template Updating
Jun 08, 2026Hyperspectral object tracking (HOT) leverages the rich spectral information provided by hyperspectral videos (HSVs), offering substantial potential for object tracking. However, efficiently extracting and exploiting spectral information from redundant spectral bands remains a fundamental challenge, which severely limits model generalization and tracking performance. Moreover, in dynamic scenes, targets often experience drastic appearance variations due to factors such as occlusion and illumination changes. These variations lead to large deformations between the current frame and the template. Such discrepancies pose major challenges for existing temporal modeling approaches. In this work, we propose VLHTrack, a novel hyperspectral vision-language (VL) joint tracking framework. Specifically, we incorporate language priors to address the fundamental challenge of spectral redundancy by designing a Language-Guided Band Selection Module (LBSM). By leveraging Large Language Model (LLM) descriptions, LBSM establishes a semantic-to-spectral mapping that mitigates redundancy and accentuates discriminative spectral features. A Multi-Modal Vision-Language Fusion Module is then employed to seamlessly integrate visual and linguistic embeddings, harnessing their complementary advantages to learn coherent cross-modal representations. To address target deformation in long-term sequences, we propose a dynamic update template feature strategy implemented via the Dynamic Template Update with Mamba (DTUM) module. By leveraging selective state space modeling, DTUM learns inter-frame dependencies to update template feature, ensuring efficient template feature evolution guided by temporal context. Experiments on HOT2023 and HOT2024 demonstrate that VLHTrack outperforms state-of-the-art (SOTA) methods.
Real-Time Oriented Object Detection Transformer in Remote Sensing Images
Mar 16, 2026Recent real-time detection transformers have gained popularity due to their simplicity and efficiency. However, these detectors do not explicitly model object rotation, especially in remote sensing imagery where objects appear at arbitrary angles, leading to challenges in angle representation, matching cost, and training stability. In this paper, we propose a real-time oriented object detection transformer, the first real-time end-to-end oriented object detector to the best of our knowledge, that addresses the above issues. Specifically, angle distribution refinement is proposed to reformulate angle regression as an iterative refinement of probability distributions, thereby capturing the uncertainty of object rotation and providing a more fine-grained angle representation. Then, we incorporate a Chamfer distance cost into bipartite matching, measuring box distance via vertex sets, enabling more accurate geometric alignment and eliminating ambiguous matches. Moreover, we propose oriented contrastive denoising to stabilize training and analyze four noise modes. We observe that a ground truth can be assigned to different index queries across different decoder layers, and analyze this issue using the proposed instability metric. We design a series of model variants and experiments to validate the proposed method. Notably, our O2-DFINE-L, O2-RTDETR-R50 and O2-DEIM-R50 achieve 77.73%/78.45%/80.15% AP50 on DOTA1.0 and 132/119/119 FPS on the 2080ti GPU. Code is available at https://github.com/wokaikaixinxin/ai4rs.
* IEEE Transactions on Geoscience and Remote Sensing, 2026, doi 10.1109/TGRS.2026.3671683
Content-Adaptive Image Retouching Guided by Attribute-Based Text Representation
Dec 10, 2025Image retouching has received significant attention due to its ability to achieve high-quality visual content. Existing approaches mainly rely on uniform pixel-wise color mapping across entire images, neglecting the inherent color variations induced by image content. This limitation hinders existing approaches from achieving adaptive retouching that accommodates both diverse color distributions and user-defined style preferences. To address these challenges, we propose a novel Content-Adaptive image retouching method guided by Attribute-based Text Representation (CA-ATP). Specifically, we propose a content-adaptive curve mapping module, which leverages a series of basis curves to establish multiple color mapping relationships and learns the corresponding weight maps, enabling content-aware color adjustments. The proposed module can capture color diversity within the image content, allowing similar color values to receive distinct transformations based on their spatial context. In addition, we propose an attribute text prediction module that generates text representations from multiple image attributes, which explicitly represent user-defined style preferences. These attribute-based text representations are subsequently integrated with visual features via a multimodal model, providing user-friendly guidance for image retouching. Extensive experiments on several public datasets demonstrate that our method achieves state-of-the-art performance.
DTTNet: Improving Video Shadow Detection via Dark-Aware Guidance and Tokenized Temporal Modeling
Nov 10, 2025Video shadow detection confronts two entwined difficulties: distinguishing shadows from complex backgrounds and modeling dynamic shadow deformations under varying illumination. To address shadow-background ambiguity, we leverage linguistic priors through the proposed Vision-language Match Module (VMM) and a Dark-aware Semantic Block (DSB), extracting text-guided features to explicitly differentiate shadows from dark objects. Furthermore, we introduce adaptive mask reweighting to downweight penumbra regions during training and apply edge masks at the final decoder stage for better supervision. For temporal modeling of variable shadow shapes, we propose a Tokenized Temporal Block (TTB) that decouples spatiotemporal learning. TTB summarizes cross-frame shadow semantics into learnable temporal tokens, enabling efficient sequence encoding with minimal computation overhead. Comprehensive Experiments on multiple benchmark datasets demonstrate state-of-the-art accuracy and real-time inference efficiency. Codes are available at https://github.com/city-cheng/DTTNet.
Learning Gaussian DAG Models without Condition Number Bounds
Nov 08, 2025We study the problem of learning the topology of a directed Gaussian Graphical Model under the equal-variance assumption, where the graph has $n$ nodes and maximum in-degree $d$. Prior work has established that $O(d \log n)$ samples are sufficient for this task. However, an important factor that is often overlooked in these analyses is the dependence on the condition number of the covariance matrix of the model. Indeed, all algorithms from prior work require a number of samples that grows polynomially with this condition number. In many cases this is unsatisfactory, since the condition number could grow polynomially with $n$, rendering these prior approaches impractical in high-dimensional settings. In this work, we provide an algorithm that recovers the underlying graph and prove that the number of samples required is independent of the condition number. Furthermore, we establish lower bounds that nearly match the upper bound up to a $d$-factor, thus providing an almost tight characterization of the true sample complexity of the problem. Moreover, under a further assumption that all the variances of the variables are bounded, we design a polynomial-time algorithm that recovers the underlying graph, at the cost of an additional polynomial dependence of the sample complexity on $d$. We complement our theoretical findings with simulations on synthetic datasets that confirm our predictions.
Interpreting Fedspeak with Confidence: A LLM-Based Uncertainty-Aware Framework Guided by Monetary Policy Transmission Paths
Aug 12, 2025"Fedspeak", the stylized and often nuanced language used by the U.S. Federal Reserve, encodes implicit policy signals and strategic stances. The Federal Open Market Committee strategically employs Fedspeak as a communication tool to shape market expectations and influence both domestic and global economic conditions. As such, automatically parsing and interpreting Fedspeak presents a high-impact challenge, with significant implications for financial forecasting, algorithmic trading, and data-driven policy analysis. In this paper, we propose an LLM-based, uncertainty-aware framework for deciphering Fedspeak and classifying its underlying monetary policy stance. Technically, to enrich the semantic and contextual representation of Fedspeak texts, we incorporate domain-specific reasoning grounded in the monetary policy transmission mechanism. We further introduce a dynamic uncertainty decoding module to assess the confidence of model predictions, thereby enhancing both classification accuracy and model reliability. Experimental results demonstrate that our framework achieves state-of-the-art performance on the policy stance analysis task. Moreover, statistical analysis reveals a significant positive correlation between perceptual uncertainty and model error rates, validating the effectiveness of perceptual uncertainty as a diagnostic signal.
Compliance-to-Code: Enhancing Financial Compliance Checking via Code Generation
May 26, 2025
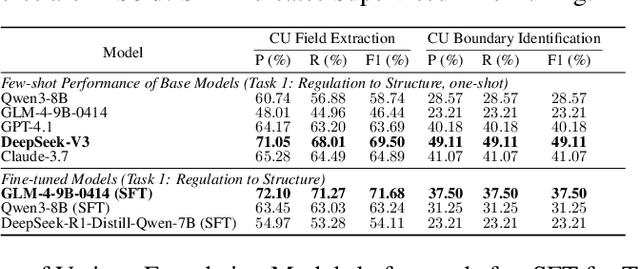
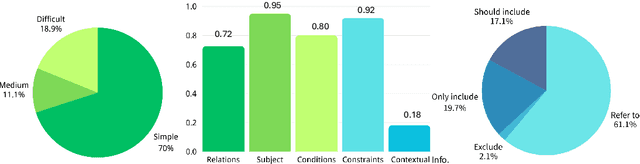
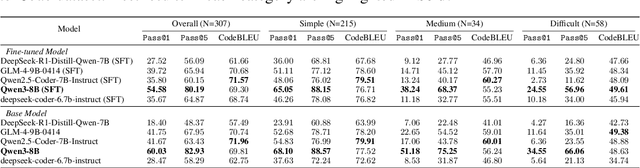
Nowadays, regulatory compliance has become a cornerstone of corporate governance, ensuring adherence to systematic legal frameworks. At its core, financial regulations often comprise highly intricate provisions, layered logical structures, and numerous exceptions, which inevitably result in labor-intensive or comprehension challenges. To mitigate this, recent Regulatory Technology (RegTech) and Large Language Models (LLMs) have gained significant attention in automating the conversion of regulatory text into executable compliance logic. However, their performance remains suboptimal particularly when applied to Chinese-language financial regulations, due to three key limitations: (1) incomplete domain-specific knowledge representation, (2) insufficient hierarchical reasoning capabilities, and (3) failure to maintain temporal and logical coherence. One promising solution is to develop a domain specific and code-oriented datasets for model training. Existing datasets such as LexGLUE, LegalBench, and CODE-ACCORD are often English-focused, domain-mismatched, or lack fine-grained granularity for compliance code generation. To fill these gaps, we present Compliance-to-Code, the first large-scale Chinese dataset dedicated to financial regulatory compliance. Covering 1,159 annotated clauses from 361 regulations across ten categories, each clause is modularly structured with four logical elements-subject, condition, constraint, and contextual information-along with regulation relations. We provide deterministic Python code mappings, detailed code reasoning, and code explanations to facilitate automated auditing. To demonstrate utility, we present FinCheck: a pipeline for regulation structuring, code generation, and report generation.
Modality-Guided Dynamic Graph Fusion and Temporal Diffusion for Self-Supervised RGB-T Tracking
May 06, 2025To reduce the reliance on large-scale annotations, self-supervised RGB-T tracking approaches have garnered significant attention. However, the omission of the object region by erroneous pseudo-label or the introduction of background noise affects the efficiency of modality fusion, while pseudo-label noise triggered by similar object noise can further affect the tracking performance. In this paper, we propose GDSTrack, a novel approach that introduces dynamic graph fusion and temporal diffusion to address the above challenges in self-supervised RGB-T tracking. GDSTrack dynamically fuses the modalities of neighboring frames, treats them as distractor noise, and leverages the denoising capability of a generative model. Specifically, by constructing an adjacency matrix via an Adjacency Matrix Generator (AMG), the proposed Modality-guided Dynamic Graph Fusion (MDGF) module uses a dynamic adjacency matrix to guide graph attention, focusing on and fusing the object's coherent regions. Temporal Graph-Informed Diffusion (TGID) models MDGF features from neighboring frames as interference, and thus improving robustness against similar-object noise. Extensive experiments conducted on four public RGB-T tracking datasets demonstrate that GDSTrack outperforms the existing state-of-the-art methods. The source code is available at https://github.com/LiShenglana/GDSTrack.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Fixed Point Computation: Beating Brute Force with Smoothed Analysis
Jan 18, 2025We propose a new algorithm that finds an $\varepsilon$-approximate fixed point of a smooth function from the $n$-dimensional $\ell_2$ unit ball to itself. We use the general framework of finding approximate solutions to a variational inequality, a problem that subsumes fixed point computation and the computation of a Nash Equilibrium. The algorithm's runtime is bounded by $e^{O(n)}/\varepsilon$, under the smoothed-analysis framework. This is the first known algorithm in such a generality whose runtime is faster than $(1/\varepsilon)^{O(n)}$, which is a time that suffices for an exhaustive search. We complement this result with a lower bound of $e^{\Omega(n)}$ on the query complexity for finding an $O(1)$-approximate fixed point on the unit ball, which holds even in the smoothed-analysis model, yet without the assumption that the function is smooth. Existing lower bounds are only known for the hypercube, and adapting them to the ball does not give non-trivial results even for finding $O(1/\sqrt{n})$-approximate fixed points.