 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCT-Net: Arbitrary-Shaped Text Detection via Contour Transformer
Jul 25, 2023



Contour based scene text detection methods have rapidly developed recently, but still suffer from inaccurate frontend contour initialization, multi-stage error accumulation, or deficient local information aggregation. To tackle these limitations, we propose a novel arbitrary-shaped scene text detection framework named CT-Net by progressive contour regression with contour transformers. Specifically, we first employ a contour initialization module that generates coarse text contours without any post-processing. Then, we adopt contour refinement modules to adaptively refine text contours in an iterative manner, which are beneficial for context information capturing and progressive global contour deformation. Besides, we propose an adaptive training strategy to enable the contour transformers to learn more potential deformation paths, and introduce a re-score mechanism that can effectively suppress false positives. Extensive experiments are conducted on four challenging datasets, which demonstrate the accuracy and efficiency of our CT-Net over state-of-the-art methods. Particularly, CT-Net achieves F-measure of 86.1 at 11.2 frames per second (FPS) and F-measure of 87.8 at 10.1 FPS for CTW1500 and Total-Text datasets, respectively.
TextDCT: Arbitrary-Shaped Text Detection via Discrete Cosine Transform Mask
Jun 27, 2022

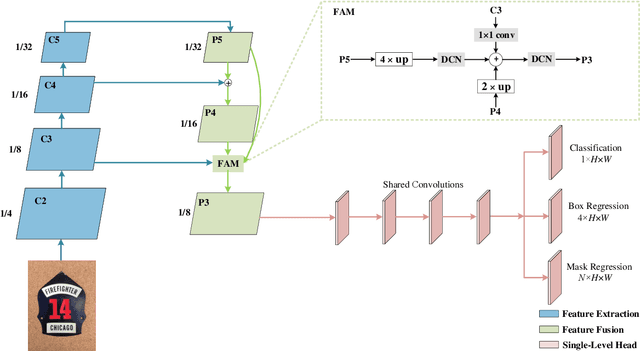
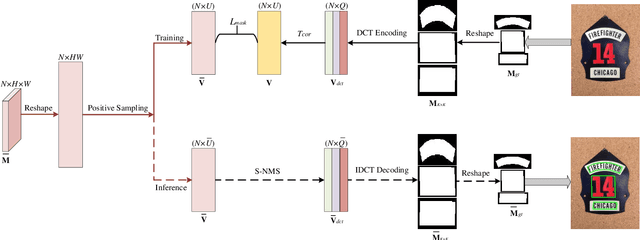
Arbitrary-shaped scene text detection is a challenging task due to the variety of text changes in font, size, color, and orientation. Most existing regression based methods resort to regress the masks or contour points of text regions to model the text instances. However, regressing the complete masks requires high training complexity, and contour points are not sufficient to capture the details of highly curved texts. To tackle the above limitations, we propose a novel light-weight anchor-free text detection framework called TextDCT, which adopts the discrete cosine transform (DCT) to encode the text masks as compact vectors. Further, considering the imbalanced number of training samples among pyramid layers, we only employ a single-level head for top-down prediction. To model the multi-scale texts in a single-level head, we introduce a novel positive sampling strategy by treating the shrunk text region as positive samples, and design a feature awareness module (FAM) for spatial-awareness and scale-awareness by fusing rich contextual information and focusing on more significant features. Moreover, we propose a segmented non-maximum suppression (S-NMS) method that can filter low-quality mask regressions. Extensive experiments are conducted on four challenging datasets, which demonstrate our TextDCT obtains competitive performance on both accuracy and efficiency. Specifically, TextDCT achieves F-measure of 85.1 at 17.2 frames per second (FPS) and F-measure of 84.9 at 15.1 FPS for CTW1500 and Total-Text datasets, respectively.
Optimizing Cost-Sensitive SVM for Imbalanced Data :Connecting Cluster to Classification
Feb 06, 2017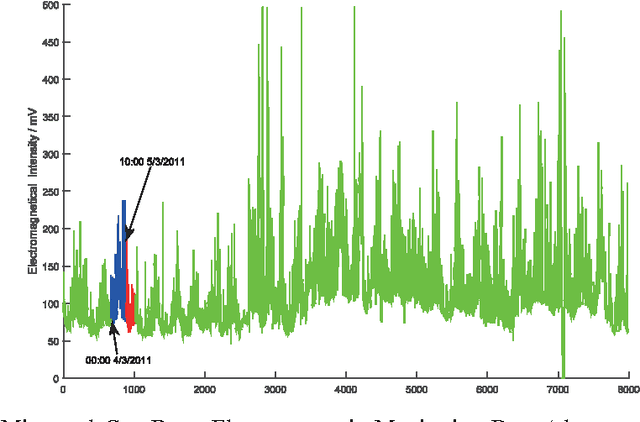
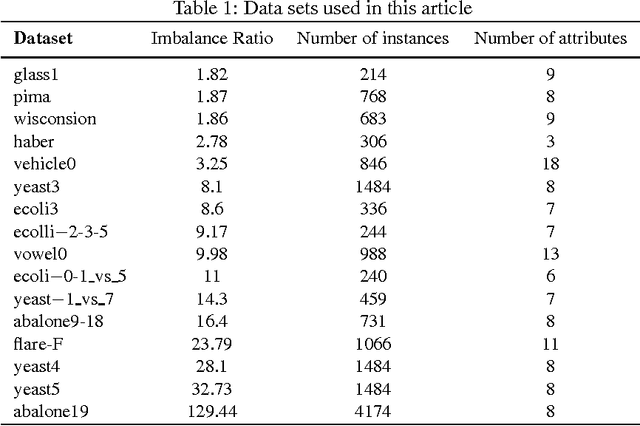
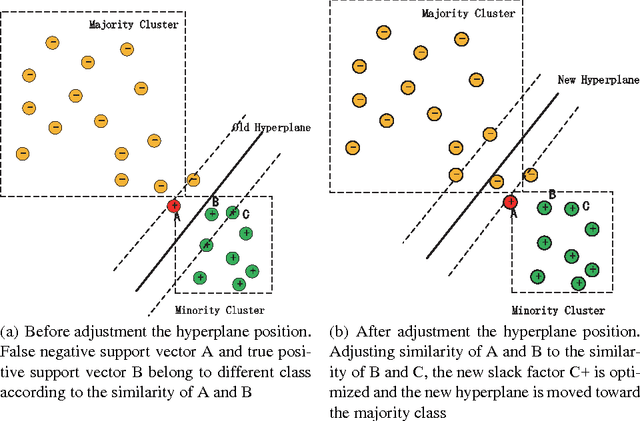
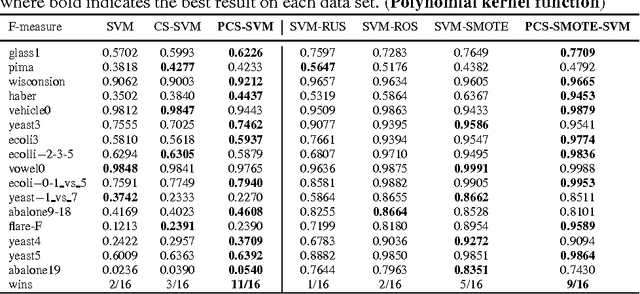
Class imbalance is one of the challenging problems for machine learning in many real-world applications, such as coal and gas burst accident monitoring: the burst premonition data is extreme smaller than the normal data, however, which is the highlight we truly focus on. Cost-sensitive adjustment approach is a typical algorithm-level method resisting the data set imbalance. For SVMs classifier, which is modified to incorporate varying penalty parameter(C) for each of considered groups of examples. However, the C value is determined empirically, or is calculated according to the evaluation metric, which need to be computed iteratively and time consuming. This paper presents a novel cost-sensitive SVM method whose penalty parameter C optimized on the basis of cluster probability density function(PDF) and the cluster PDF is estimated only according to similarity matrix and some predefined hyper-parameters. Experimental results on various standard benchmark data sets and real-world data with different ratios of imbalance show that the proposed method is effective in comparison with commonly used cost-sensitive techniques.